一种基于AI训练任务指标的资源调度策略优化方法
- 国知局
- 2024-10-15 10:14:55
本发明涉及计算机科学、人工智能和资源调度领域,特别是涉及一种基于ai训练任务指标的资源调度策略优化方法。
背景技术:
1、随着人工智能技术的快速发展,深度学习模型在图像识别、语音识别、自然语言处理等多个领域得到了广泛应用。这些深度学习模型的训练过程通常需要大量的计算资源和时间。因此,如何高效地调度和利用计算资源成为一个关键问题。
2、目前,已有的资源调度策略大多基于启发式算法,如fifo(先来先服务)、drf(dominant resource fairness)。这些算法虽然在一定程度上提高了资源利用率,但在面对复杂的任务依赖关系和异构计算资源时,难以达到最优的调度效果。现有的调度策略通常关注任务载入时间和执行顺序的优化,忽视了任务间的关联性和资源的动态变化,导致资源利用效率和任务执行性能不理想。
3、为了解决这些问题,学术界和工业界提出了多种优化方法,包括min-min算法、max-min算法、基于遗传算法的优化、基于粒子群算法的优化等。这些方法在某些特定场景下表现良好,但在复杂多变的ai训练任务中,往往缺乏足够的灵活性和适应性。
4、随着深度学习和强化学习技术的发展,研究人员开始探索基于深度强化学习的智能调度策略,以期在异构计算环境中实现更高效的资源利用和更优的任务调度效果。通过不断优化调度策略,能够显著提升ai训练任务的整体性能,减少计算资源的闲置和浪费。
技术实现思路
1、有鉴于此,本发明提出了一种基于深度强化学习的智能资源调度策略优化方法,用于提升人工智能训练任务的资源利用效率和训练性能。本发明的目的是通过引入深度强化学习技术,构建智能调度框架,实现高效、灵活的资源调度和任务分配。该方法结合深度学习、强化学习和异构计算环境,通过优化计算资源的调度策略,提高ai训练任务的运行效率和资源利用率,适用于多种深度学习模型的训练过程。
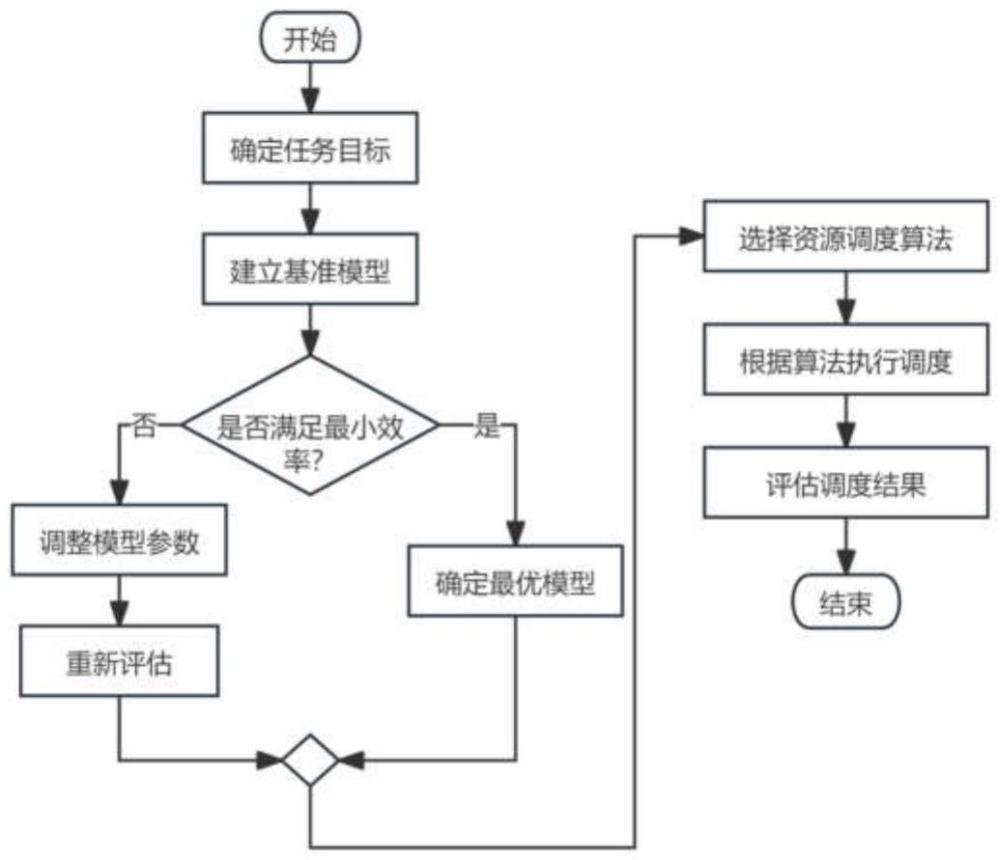
2、本发明为实现上述目的所采用的技术方案是:一种基于ai训练任务指标的资源调度策略优化方法,包括以下步骤:
3、1)任务特征提取:从ai训练任务中提取任务特征信息,并将所述任务特征信息转化为特征向量;
4、2)调度策略建模:将资源调度问题建模为马尔可夫决策过程,根据特征向量构建状态空间、动作空间和奖励函数,其中,状态空间包括当前任务队列和资源利用率,动作空间包括任务分配到某计算节点的各种可能动作,奖励函数根据任务完成时间和资源利用率得到;
5、3)深度强化学习训练:采用深度q网络算法对调度策略进行训练;
6、4)调度决策执行:根据当前的任务和资源状态,利用训练好的q网络选择最优的调度动作,根据最优的调度动作将任务分配到相应的计算节点,实现资源调度策略优化。
7、所述任务特征信息包括任务的资源需求、任务完成时间、依赖关系。
8、所述任务特征提取,包括以下步骤:
9、(1)数据预处理:对ai训练任务数据进行清洗和标准化处理,去除异常值和噪声数据,采用归一化将不同尺度的数据转换到同一范围;
10、(2)特征选择:从预处理后的数据中提取重要特征,所述重要特征包括:任务完成时间、资源利用率、内存使用量和任务优先级;
11、(3)特征向量生成:将提取在重要特征转换为向量形式,得到特征向量。
12、所述调度策略建模,包括以下步骤:
13、构建状态空间:状态空间s表示当前时刻的资源利用状态和任务队列状态,s={(u1,u2,...,un),(q1,q2,...,qm)},其中,ui表示第i个节点的资源利用率,qj表示第j个任务的特征向量;
14、构建动作空间:动作空间a表示将任务分配到指定计算节点的操作,a={a1,a2,...,ak},其中,ai表示将某个任务分配到第i个节点;
15、构建奖励函数:奖励函数r=-(w1*任务完成时间+w2*资源利用率),其中w1和w2为权重系数。
16、所述深度强化学习训练,包括以下步骤:
17、q网络初始化:初始化q网络和目标q网络,q网络采用多层感知机结构,输入为状态向量,输出为每个动作的q值;
18、经验回放机制:在训练过程中,存储状态、动作、奖励、下一状态的四元组,经验回放池中的数据通过随机抽样的方式进行训练;
19、训练步骤:在每个时间步,基于当前状态选择动作,执行动作,观察下一状态和即时奖励,存储经验到经验回放池中,从经验回放池中随机抽取批量经验,更新q网络,定期将q网络的参数复制到目标q网络。
20、所述调度决策执行,包括以下步骤:
21、状态监测:实时监测资源使用情况和任务执行状态,收集状态信息;
22、决策执行:根据当前状态信息和q网络的输出,选择最优调度动作,并将任务分配到相应节点;
23、反馈调整:根据任务执行结果和状态的变化,实时调整调度策略。
24、一种基于ai训练任务指标的资源调度策略优化系统,包括:
25、任务特征提取模块,用于从ai训练任务中提取任务特征信息,并将所述任务特征信息转化为特征向量;
26、调度策略构建模块,用于将资源调度问题建模为马尔可夫决策过程,根据特征向量构建状态空间、动作空间和奖励函数,其中,状态空间包括当前任务队列和资源利用率,动作空间包括任务分配到某计算节点的各种可能动作,奖励函数根据任务完成时间和资源利用率得到;
27、深度强化学习训练模块,用于采用深度q网络算法对调度策略进行训练;
28、调度决策执行模块,用于根据当前的任务和资源状态,利用训练好的q网络选择最优的调度动作,根据最优的调度动作将任务分配到相应的计算节点,实现资源调度策略优化。
29、本发明通过引入深度强化学习技术,实现了对ai训练任务的智能资源调度,具有以下优点:
30、1、提高资源利用率:通过智能调度策略优化,显著提高计算资源的利用效率,减少资源闲置和浪费。
31、2、缩短任务完成时间:优化任务的调度顺序和分配,显著缩短ai训练任务的总完成时间。
32、3、适应复杂环境:能够在异构计算环境中灵活调度任务,适应不同的资源配置和任务需求。
33、4、自适应优化:通过不断学习和调整,智能调度系统能够根据实际情况自适应优化调度策略,持续提升性能。
技术特征:1.一种基于ai训练任务指标的资源调度策略优化方法,其特征在于,包括以下步骤:
2.根据权利要求1所述的一种基于ai训练任务指标的资源调度策略优化方法,其特征在于,所述任务特征信息包括任务的资源需求、任务完成时间、依赖关系。
3.根据权利要求1所述的一种基于ai训练任务指标的资源调度策略优化方法,其特征在于,所述任务特征提取,包括以下步骤:
4.根据权利要求1所述的一种基于ai训练任务指标的资源调度策略优化方法,其特征在于,所述调度策略建模,包括以下步骤:
5.根据权利要求1所述的一种基于ai训练任务指标的资源调度策略优化方法,其特征在于,所述深度强化学习训练,包括以下步骤:
6.根据权利要求1所述的一种基于ai训练任务指标的资源调度策略优化方法,其特征在于,所述调度决策执行,包括以下步骤:
7.一种基于ai训练任务指标的资源调度策略优化系统,其特征在于,包括:
8.一种基于ai训练任务指标的资源调度策略优化装置,其特征在于,包括存储器和处理器;所述存储器,用于存储计算机程序;所述处理器,用于当执行所述计算机程序时,实现如权利要求1-6任一项所述的一种基于ai训练任务指标的资源调度策略优化方法。
9.一种计算机可读存储介质,其特征在于,所述存储介质上存储有计算机程序,当所述计算机程序被处理器执行时,实现如权利要求1-6任一项所述的一种基于ai训练任务指标的资源调度策略优化方法。
技术总结本发明涉及一种基于AI训练任务指标的资源调度策略优化方法,一种基于AI训练任务指标的资源调度策略优化方法,包括以下步骤:任务特征提取:从AI训练任务中提取任务特征信息,并将所述任务特征信息转化为特征向量;调度策略建模:将资源调度问题建模为马尔可夫决策过程,根据特征向量构建状态空间、动作空间和奖励函数;深度强化学习训练:采用深度Q网络算法对调度策略进行训练;调度决策执行:根据当前的任务和资源状态,利用训练好的Q网络选择最优的调度动作,根据最优的调度动作将任务分配到相应的计算节点,实现资源调度策略优化。本发明能够提高资源利用率,通过智能调度策略优化,显著提高计算资源的利用效率,减少资源闲置和浪费;缩短任务完成时间,优化任务的调度顺序和分配,显著缩短AI训练任务的总完成时间。技术研发人员:郭锐锋,王传晨,王鸿亮,李雪娆,修鹏飞,许晶受保护的技术使用者:中国科学院沈阳计算技术研究所有限公司技术研发日:技术公布日:2024/10/10本文地址:https://www.jishuxx.com/zhuanli/20241015/316942.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。