一种基于大语言模型的轨道交通知识库构建方法及系统与流程
- 国知局
- 2024-10-15 10:15:32
本发明属于知识库构建,更具体地,涉及一种基于大语言模型的轨道交通知识库构建方法及系统。
背景技术:
1、通用大语言模型具有强大的推理逻辑,对简单问题能够实现快速准确推理。但是在轨道交通行业,工程量大,专业多,专业复杂,工程特点明显,大模型无法实时获取最新的工程数据建设方案,导致大模型对轨道交通领域的复杂问题推理能力弱,准确率低。虽然可以通过微调技术,结合数据集实现推理能力提高,但是过程需要丰富的经验和庞大的算力,成本高,时间周期长,不具备推广条件。传统的知识库问答系统,经历了数据库查询、文件搜索、知识图谱等技术,虽然准确性和易用性有所提高,但是对用户的语义理解和检索结果缺少智能化处理,查询的精度和效率低。
2、通用的大语言模型虽然在处理简单问题时表现出色,具备快速准确的推理能力,但在面对轨道交通行业这一专业性强、工程量大、数据更新迅速的领域时,其推理能力受限。轨道交通项目涉及众多专业领域,每个领域都有其复杂性,且工程数据和建设方案持续更新,这对大模型的实时数据获取能力提出了挑战。尽管通过微调技术和结合特定数据集可以提升模型的推理能力,但这一过程不仅需要专业知识和丰富经验,还需要巨大的计算资源,导致成本高昂且周期长,难以广泛应用。
3、传统的知识库问答系统,尽管在数据库查询、文件搜索、知识图谱等方面取得了一定的进展,提高了系统的准确性和易用性,但在语义理解与检索结果的智能化处理方面仍有不足,导致查询精度和效率不尽人意,llm+本地知识库方案在多知识点聚合处理场景下,embedding-search召回精度较低的问题。
技术实现思路
1、为解决以上技术问题,本发明提出一种基于大语言模型的轨道交通知识库构建方法,包括:
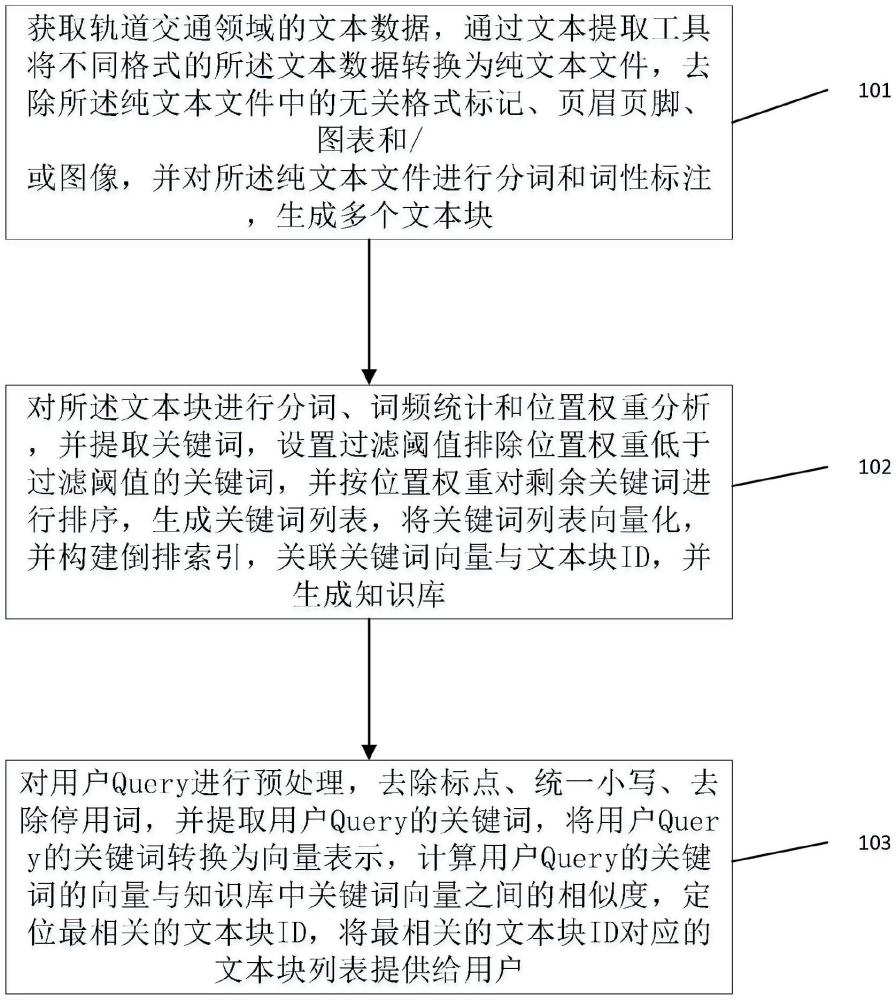
2、获取轨道交通领域的文本数据,通过文本提取工具将不同格式的所述文本数据转换为纯文本文件,去除所述纯文本文件中的无关格式标记、页眉页脚、图表和/或图像,并对所述纯文本文件进行分词和词性标注,生成多个文本块;
3、对所述文本块进行分词、词频统计和位置权重分析,并提取关键词,设置过滤阈值排除位置权重低于过滤阈值的关键词,并按位置权重对剩余关键词进行排序,生成关键词列表,将关键词列表向量化,并构建倒排索引,关联关键词向量与文本块id,并生成知识库;
4、对用户query进行预处理,去除标点、统一小写、去除停用词,并提取用户query的关键词,将用户query的关键词转换为向量表示,计算用户query的关键词的向量与知识库中关键词向量之间的相似度,定位最相关的文本块id,将最相关的文本块id对应的文本块列表提供给用户。
5、进一步的,通过文本提取工具将不同格式的所述文本数据转换为纯文本文件,其中,所述纯文本文件为utf-8编码的纯文本文件。
6、进一步的,在进行分词和词性标注之前还包括:将所述纯文本文件中所有文本转换为小写。
7、进一步的,对所述纯文本文件进行分词和词性标注之后还包括:通过基于文本指纹的哈希算法检测并去除标注后的所述文本文件的重复数据,确保知识库中数据的唯一性。
8、进一步的,提取用户query的关键词之后还包括:通过深度神经网络识别用户query的意图,确定用户想要检索的知识库类型。
9、本发明还提出一种基于大语言模型的轨道交通知识库构建系统,包括:
10、生成文本块模块,用于获取轨道交通领域的文本数据,通过文本提取工具将不同格式的所述文本数据转换为纯文本文件,去除所述纯文本文件中的无关格式标记、页眉页脚、图表和/或图像,并对所述纯文本文件进行分词和词性标注,生成多个文本块;
11、生成知识库模块,用于对所述文本块进行分词、词频统计和位置权重分析,并提取关键词,设置过滤阈值排除位置权重低于过滤阈值的关键词,并按位置权重对剩余关键词进行排序,生成关键词列表,将关键词列表向量化,并构建倒排索引,关联关键词向量与文本块id,并生成知识库;
12、提供知识模块,用于对用户query进行预处理,去除标点、统一小写、去除停用词,并提取用户query的关键词,将用户query的关键词转换为向量表示,计算用户query的关键词的向量与知识库中关键词向量之间的相似度,定位最相关的文本块id,将最相关的文本块id对应的文本块列表提供给用户。
13、进一步的,通过文本提取工具将不同格式的所述文本数据转换为纯文本文件,其中,所述纯文本文件为utf-8编码的纯文本文件。
14、进一步的,在进行分词和词性标注之前还包括:将所述纯文本文件中所有文本转换为小写。
15、进一步的,对所述纯文本文件进行分词和词性标注之后还包括:通过基于文本指纹的哈希算法检测并去除标注后的所述文本文件的重复数据,确保知识库中数据的唯一性。
16、进一步的,提取用户query的关键词之后还包括:通过深度神经网络识别用户query的意图,确定用户想要检索的知识库类型。
17、通过本发明所构思的以上技术方案与现有技术相比,具有以下有益效果:
18、本发明利用自然语言处理(nlp)技术、向量数据库和大语言模型等先进技术,创建了一个智能化的问答平台,旨在提高问答的效率和准确性,从而有效辅助现场决策。系统通过以下关键技术实现优化:数据预处理、知识库管理、关键词提取、向量知识库构建、问题检索、大模型加工处理、性能监控与优化。通过这些技术的融合与应用,本发明的轨道交通知识库问答系统能够提供更加智能化、高效率的知识检索服务,满足轨道交通行业对专业、准确工程信息的需求,有效支持工程从业人员在现场的质量安全管理工作。
技术特征:1.一种基于大语言模型的轨道交通知识库构建方法,其特征在于,包括:
2.如权利要求1所述的一种基于大语言模型的轨道交通知识库构建方法,其特征在于,通过文本提取工具将不同格式的所述文本数据转换为纯文本文件,其中,所述纯文本文件为utf-8编码的纯文本文件。
3.如权利要求1所述的一种基于大语言模型的轨道交通知识库构建方法,其特征在于,在进行分词和词性标注之前还包括:将所述纯文本文件中所有文本转换为小写。
4.如权利要求1所述的一种基于大语言模型的轨道交通知识库构建方法,其特征在于,对所述纯文本文件进行分词和词性标注之后还包括:通过基于文本指纹的哈希算法检测并去除标注后的所述文本文件的重复数据,确保知识库中数据的唯一性。
5.如权利要求1所述的一种基于大语言模型的轨道交通知识库构建方法,其特征在于,提取用户query的关键词之后还包括:通过深度神经网络识别用户query的意图,确定用户想要检索的知识库类型。
6.一种基于大语言模型的轨道交通知识库构建系统,其特征在于,包括:
7.如权利要求6所述的一种基于大语言模型的轨道交通知识库构建系统,其特征在于,通过文本提取工具将不同格式的所述文本数据转换为纯文本文件,其中,所述纯文本文件为utf-8编码的纯文本文件。
8.如权利要求6所述的一种基于大语言模型的轨道交通知识库构建系统,其特征在于,在进行分词和词性标注之前还包括:将所述纯文本文件中所有文本转换为小写。
9.如权利要求6所述的一种基于大语言模型的轨道交通知识库构建系统,其特征在于,对所述纯文本文件进行分词和词性标注之后还包括:通过基于文本指纹的哈希算法检测并去除标注后的所述文本文件的重复数据,确保知识库中数据的唯一性。
10.如权利要求6所述的一种基于大语言模型的轨道交通知识库构建系统,其特征在于,提取用户query的关键词之后还包括:通过深度神经网络识别用户query的意图,确定用户想要检索的知识库类型。
技术总结本发明公开一种基于大语言模型的轨道交通知识库构建方法及系统,该方法包括:获取轨道交通领域的文本数据,通过文本提取工具将不同格式的所述文本数据转换为纯文本文件,去除所述纯文本文件中的无关格式标记、页眉页脚、图表和/或图像,并对所述纯文本文件进行分词和词性标注,生成多个文本块;提取关键词,设置过滤阈值排除位置权重低于过滤阈值的关键词,并按位置权重对剩余关键词进行排序,生成关键词列表,将关键词列表向量化,并构建倒排索引,关联关键词向量与文本块ID,并生成知识库;提取用户Query的关键词,将用户Query的关键词转换为向量表示,计算用户Query的关键词的向量与知识库中关键词向量之间的相似度,定位最相关的文本块ID。技术研发人员:王臣,张鑫,段宪锋,周明科,张波,王浩任,李佳蓉,马骉,高晗受保护的技术使用者:北京城建设计发展集团股份有限公司技术研发日:技术公布日:2024/10/10本文地址:https://www.jishuxx.com/zhuanli/20241015/316986.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表