一种公路工程资源需用计划预测方法、系统、设备及存储介质与流程
- 国知局
- 2024-10-21 14:34:58
本发明属于工程造价领域,涉及一种公路工程资源需用计划预测方法、系统、设备及存储介质。
背景技术:
1、在公路工程建设过程中,资源需用计划的制定是确保工程顺利进行的关键环节。公路工程资源需用计划是一个综合性的规划,旨在确保公路工程建设过程中的各项资源得到合理、高效的使用。然而,传统的资源需用计划制定方法往往基于经验估计或简单统计,难以准确预测资源的实际需求。
技术实现思路
1、本发明的目的在于克服上述现有技术的缺点,提供一种公路工程资源需用计划预测方法、系统、设备及存储介质,充分利用了大数据处理和分布式计算的优势,为公路工程建设提供了科学的资源需用预测方法,具有重要的实际应用价值。
2、为达到上述目的,本发明采用以下技术方案予以实现:
3、一种公路工程资源需用计划预测方法,包括以下过程:
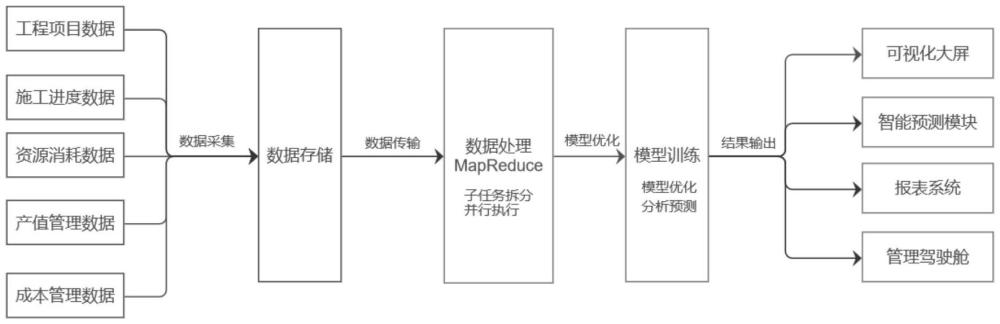
4、s1,实时获取公路工程建设过程中的历史资源消耗数据;
5、s2,将资源需用预测任务拆分成多个子任务,每个子任务在hadoop集群的节点上并行执行,结合公路工程的施工进度,采用实时更新的历史资源消耗数据和历史预测结果,对每个子任务进行分析和预测,最终得到整个工程项目的资源需用预测结果。
6、优选的,s1中,对历史资源消耗数据进行清洗、整合和标准化处理,消除异常值和噪声数据。
7、进一步,通过去重、处理缺失值和转换数据格式进行数据清洗。
8、优选的,获取历史资源消耗数据后,对其进行存储,具体过程为:
9、创建一个名为flume-conf.properties的文件;
10、配置flume源、通道和接收器;
11、启动flume;
12、确保hadoop集群正在运行并且可以通过hdfs://namenode:8020访问hdfs;
13、向flume的netcat源发送历史资源消耗数据。
14、优选的,s2过程通过hadoop的hive工具实现,具体过程为:
15、查询解析:hive接收到用户的査询请求后,首先对查询进行解析,将査询语句解析成抽象语法树;
16、查询优化:hive使用优化器对查询进行优化;
17、任务划分:优化后的查询被划分成多个子任务,每个子任务处理一部分历史资源消耗数据;
18、并行执行:划分好的子任务被提交到集群中的多个节点上并行采用实时更新的预测模型进行预测,每个节点上的任务读取和处理自己负责的数据块;
19、结果合并:各个节点上任务执行完成后,将结果合并成一个最终的结果。
20、进一步,预测模型预测过程为:
21、结合公路工程的施工进度和历史资源消耗数据,生成一个时间序列数据集,通过时间序列数据集建立arma模型;
22、采用实时更新的历史资源消耗数据和历史预测结果的反馈,使用matlab的estimate函数来估计arma模型的参数;
23、使用forecast函数进行预测。
24、进一步,使用优化器对查询进行优化的方式包括列裁剪、谓词下推、表连接优化和聚合推导。
25、一种公路工程资源需用计划预测系统,包括:
26、数据获取模块,用于获取公路工程建设过程中的历史资源消耗数据;
27、资源需用预测模块,用于将资源需用预测任务拆分成多个子任务,每个子任务在hadoop集群的节点上并行执行,结合公路工程的施工进度和历史资源消耗数据,对每个子任务进行分析和预测,最终得到整个工程项目的资源需用预测结果。
28、一种计算机设备,包括存储器、处理器以及存储在所述存储器中并可在所述处理器上运行的计算机程序,所述处理器执行所述计算机程序时实现所述公路工程资源需用计划预测方法的步骤。
29、一种计算机可读存储介质,所述计算机可读存储介质存储有计算机程序,所述计算机程序被处理器执行时实现所述公路工程资源需用计划预测方法的步骤。
30、与现有技术相比,本发明具有以下有益效果:
31、本发明利用hadoop的分布式计算能力,实现对海量数据的并行处理,提高了预测的效率,采用基于时间序列的预测模型和自适应调整机制,提高了预测的准确性和稳定性,应用于公路工程的资源调配和管理中,有助于降低资源浪费和短缺的风险,提高工程建设的效率和质量。充分利用了大数据处理和分布式计算的优势,为公路工程建设提供了科学的资源需用预测方法,具有重要的实际应用价值。
技术特征:1.一种公路工程资源需用计划预测方法,其特征在于,包括以下过程:
2.根据权利要求1所述的公路工程资源需用计划预测方法,其特征在于,s1中,对历史资源消耗数据进行清洗、整合和标准化处理,消除异常值和噪声数据。
3.根据权利要求2所述的公路工程资源需用计划预测方法,其特征在于,通过去重、处理缺失值和转换数据格式进行数据清洗。
4.根据权利要求1所述的公路工程资源需用计划预测方法,其特征在于,获取历史资源消耗数据后,对其进行存储,具体过程为:
5.根据权利要求1所述的公路工程资源需用计划预测方法,其特征在于,s2过程通过hadoop的hive工具实现,具体过程为:
6.根据权利要求5所述的公路工程资源需用计划预测方法,其特征在于,预测模型预测过程为:
7.根据权利要求5所述的公路工程资源需用计划预测方法,其特征在于,使用优化器对查询进行优化的方式包括列裁剪、谓词下推、表连接优化和聚合推导。
8.一种公路工程资源需用计划预测系统,其特征在于,包括:
9.一种计算机设备,包括存储器、处理器以及存储在所述存储器中并可在所述处理器上运行的计算机程序,其特征在于,所述处理器执行所述计算机程序时实现如权利要求1至7任意一项所述公路工程资源需用计划预测方法的步骤。
10.一种计算机可读存储介质,所述计算机可读存储介质存储有计算机程序,其特征在于,所述计算机程序被处理器执行时实现如权利要求1至7任意一项所述公路工程资源需用计划预测方法的步骤。
技术总结本发明公开了一种公路工程资源需用计划预测方法、系统、设备及存储介质,包括以下过程:S1,实时获取公路工程建设过程中的历史资源消耗数据;S2,将资源需用预测任务拆分成多个子任务,每个子任务在Hadoop集群的节点上并行执行,结合公路工程的施工进度,采用实时更新的历史资源消耗数据和历史预测结果,对每个子任务进行分析和预测,最终得到整个工程项目的资源需用预测结果。充分利用了大数据处理和分布式计算的优势,为公路工程建设提供了科学的资源需用预测方法,具有重要的实际应用价值。技术研发人员:孙志勇,辛友强,郭威受保护的技术使用者:陕西交建云数据科技有限公司技术研发日:技术公布日:2024/10/17本文地址:https://www.jishuxx.com/zhuanli/20241021/318657.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表