一种成熟带茎草莓果实采摘点定位方法
- 国知局
- 2024-11-06 14:46:29
本发明涉及计算机视觉与目标检测,具体涉及一种成熟带茎草莓果实采摘点定位方法。
背景技术:
1、随着现代农业的发展,草莓作为一种高附加值的经济作物,受到广泛关注。然而,草莓的采摘过程需要耗费大量人力资源,特别是在设施农业中,大规模的草莓种植更是对采摘效率提出了高要求。为了提高草莓采摘效率,实现自动化采摘成为研究的重点。利用图像处理和机器视觉技术,结合人工智能算法,可以开发出高效的草莓采摘定位方法,从而减轻劳动强度,提高采摘效率和准确性。
2、专利号为cn115984704a的中国发明专利公开了一种番茄采摘机器人的植株与果实检测算法,通过建立多任务卷积神经网络,以yolov5s作为基础网络模型,在基础网络模型中加入关键点预测参数与语义分割模块的方式,识别番茄果实与茎秆,从而达到协助机器人采摘番茄的目的。但这一过程中,因语义切割模块本身对多尺度检测存在局限性,且无法提供实例分割效果;模型本身缺少对输出茎秆图像的进一步分析与采摘坐标进一步计算确认,且易被非成熟果实茎干扰,应用于成熟带茎草莓采摘点定位方面,在实际采摘过程中的准确性与适用程度并不能达到理想水准。
技术实现思路
1、发明目的:针对背景技术中提到的问题,本发明提供了一种成熟带茎草莓果实采摘点定位方法,以深度学习算法yolov5s为模型基础,识别成熟带茎草莓图像,利用改进后的yolov5s-seg-master模型,对草莓成熟果实与对应茎的目标图像集进行茎的目标实例分割,分析并计算草莓采摘点的具体(x,y)坐标,实现采摘点定位。
2、技术方案:本发明提供一种成熟带茎草莓果实采摘点定位方法,所述方法包括如下步骤:
3、s1收集草莓成熟期植株的图像集,对草莓植株图像中的带茎的红色成熟草莓果实进行标注并和原图像打包创建数据集;
4、s2通过yolov5s模型进行草莓带茎成熟果实的目标识别训练与验证;
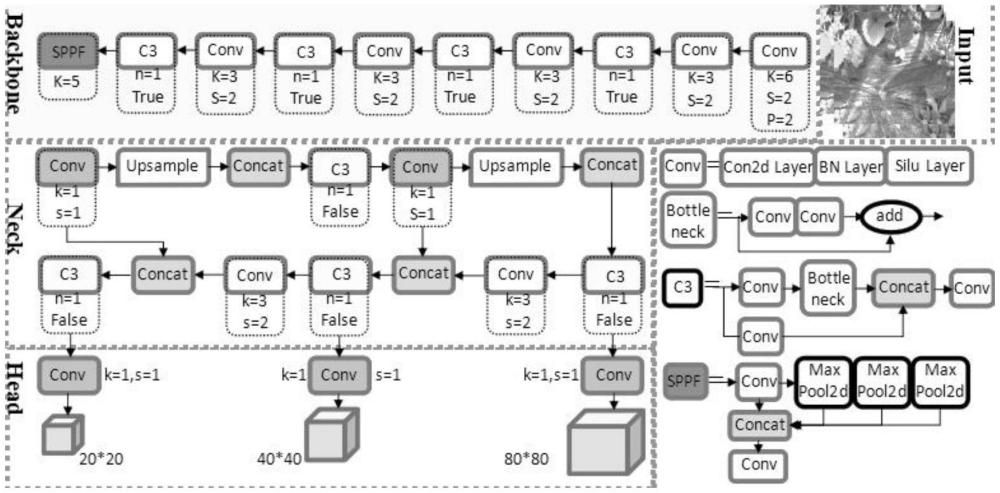
5、s2.1修改yolov5s模型head模块增强检测成熟带茎草莓的可视化表现;
6、s2.2通过修改后的yolov5s模型,输出只包含成熟草莓果实与对应茎的目标图像;
7、s3利用labelme工具对输出的草莓图像进行果茎标注,转化打包并创建数据集;
8、s4改进yolov5s-seg-master模型;
9、s4.1在head模块中创建全零黑色背景数组,调整并应用预测掩码获取二值化图像,引入canny边缘检测;
10、s4.2利用s3获取的数据集对改进后的yolov5s-seg-master模型进行训练,获取最终模型进行实例分割,识别草莓果茎,获取仅包含果茎图像集;
11、s5对果茎图像集进行茎近似矩形特征计算,应用图像掩模覆盖并标记圆心坐标以确定采摘点坐标。
12、进一步地,s2中所述yolov5模型对input、backbone和head三部分进行成熟带茎草莓识别适应化改动,具体方法如下:
13、input部分:将图片尺寸从640x640更变为320x320,在模型配置文件中修改输入图片的尺寸,并重新训练或微调模型以适应新的输入大小;
14、backbone部分:修改yolov5s的配置文件,将yolov5s的模型的channels通道数减少一半,重新训练或微调模型以适应通道数的减少;
15、head部分:修改配置文件中的锚框尺寸,减少预测层的输出通道数至对应类别数量。
16、进一步地,适应化改动还包括:将spp金字塔池化结构改进为sppf,sppf通过优化池化操作,保持与spp相似的多尺度特征融合能力的同时可降低计算量,将sppf应用于backbone中,增强特征提取阶段的多尺度特性。
17、进一步地,head模块增强检测成熟带茎草莓的可视化表现的具体修改步骤如下:
18、目标检测:使用训练好的yolov5s模型对输入图像进行处理,识别出图像中的草莓,并绘制出检测框;
19、内容提取:对于每个检测框,框定的草莓部分将被保留,框外的背景将被忽略;
20、背景处理:创建一个与原始图像大小相同的黑色图像,然后将提取的草莓内容粘贴到这个黑色背景上。
21、进一步地,s4.1的详细步骤为:
22、创建一个全零数组black_background,其形状与原图相同,用于作为黑色背景;在处理预测结果的循环中,对于每个检测到的对象掩码,将其调整大小以匹配图像大小,并应用到black_background上;设置save_img,保存或显示带有绘制掩码的black_background图像,以方便茎形状计算与采摘点定位。
23、进一步地,在head模块中引入canny边缘检测的详细步骤为:
24、定义canny边缘检测函数:创建一个名为canny_demo的函数,它接受源图像文件夹和目标输出文件夹作为参数;
25、检查并创建目标文件夹:在函数内部,首先检查目标文件夹是否存在,如果不存在,则创建它;
26、遍历源文件夹中的图像:使用os.listdir遍历源文件夹中的所有文件,并检查每个文件是否为图片格式;
27、读取和预处理图像:对于每个图像文件,使用cv2.imread读取图像,并使用cv2.cvtcolor将其从bgr颜色空间转换为rgb,然后转换为灰度图像;
28、应用高斯模糊:对灰度图像应用高斯模糊,以减少图像噪声,为canny边缘检测做准备;
29、执行canny边缘检测:使用cv2.canny函数对模糊后的图像执行canny边缘检测,设置适当的阈值来提取边缘;
30、保存处理后的图像:将canny边缘检测后的图像保存到目标文件夹,并记录处理信息;
31、调用函数:最后,定义源文件夹和目标文件夹的路径,并调用canny_demo函数来处理图像。
32、进一步地,s5茎近似矩形特征计算步骤详细为:
33、定义处理函数:创建一个名为rectangle_approximation的函数,它接受源图像文件夹和目标输出文件夹作为参数;
34、检查并创建目标文件夹:在函数内部,首先检查目标文件夹是否存在,如果不存在,则创建它;
35、遍历源文件夹中的图像:使用os.listdir遍历源文件夹中的所有文件,并检查每个文件是否为图片格式;
36、读取图像并转换为灰度:对于每个图像文件,使用cv2.imread读取图像,并使用cv2.cvtcolor将其转换为灰度图像;
37、检测图像轮廓:使用cv2.findcontours函数检测灰度图像中的轮廓;
38、创建黑色背景图像:为每个图像创建一个与原图尺寸相同的全黑背景图像;
39、轮廓多边形近似:遍历检测到的轮廓,使用cv2.approxpolydp函数对每个轮廓进行多边形近似;
40、计算最小面积矩形:使用cv2.minarearect计算近似多边形的最小面积矩形;
41、确定矩形中心和宽度:从最小面积矩形中提取宽度、高度和中心点;
42、在黑色背景上绘制圆圈:在黑色背景上,以矩形中心为圆心,宽度的一半为半径,绘制一个蓝色实心圆;
43、保存处理后的图像:将绘制有圆圈的黑色背景图像保存到目标文件夹。
44、进一步地,s5应用图像掩模覆盖并标记圆心坐标以确定采摘点坐标的方法详细为:
45、定义掩模和覆盖函数:创建一个名为
46、mask_and_overlay_circles_with_coordinates_above的函数,它接受原始图像文件夹、圆圈图像文件夹和目标输出文件夹作为参数;
47、检查并创建目标文件夹:在函数内部,首先检查目标文件夹是否存在,如果不存在,则创建它;
48、遍历图像文件夹:使用os.listdir遍历原始图像文件夹和圆圈图像文件夹中的所有文件;
49、读取图像:对于每个图像文件,使用cv2.imread读取原始草莓图像和对应的蓝色实心圆图像;
50、创建掩模:使用cv2.inrange创建一个掩模,该掩模仅包含蓝色实心圆的像素,使用cv2.dilate进行形态学膨胀,以填补掩模中的小洞;
51、提取前景和背景:使用掩模和掩模的补集,分别从原始图像中提取将要被圆圈覆盖的背景和圆圈的前景;
52、覆盖圆圈:将提取出的蓝色圆圈前景覆盖到原始图像的背景上;
53、标记圆心坐标:使用cv2.findcontours和cv2.moments查找所有圆的中心,并计算其坐标,每个圆上方标记圆心的坐标;
54、保存结果图像:将处理后的图像保存到目标文件夹,并记录处理信息。
55、有益效果:
56、1.本发明对yolov5s的head模块进行了修改,提高检测结果的可视化效果,经过训练后的yolov5s模型对成熟带茎草莓的识别率达到97%。
57、2.本发明通过改进yolov5s-seg-master模型,于head模块创建全零黑色背景数组,调整并应用预测掩码获取二值化图像,引入canny边缘检测的方式,进一步减少了进行实例分割,识别草莓果茎过程中的其他细节所干扰,提高了草莓及其果茎的识别精度,尤其是在复杂环境下的鲁棒性。
58、3.本发明对果茎图像集进行茎近似矩形特征计算,应用图像掩模覆盖并标记圆心坐标以确定采摘点坐标,通过精确定位果茎,为自动化采摘提供了准确的采摘点,从而提高了采摘效率。
本文地址:https://www.jishuxx.com/zhuanli/20241106/324063.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
上一篇
码流加载系统和方法与流程
下一篇
返回列表