基于深度学习与代谢谱分析的心血管年龄预测方法及装置
- 国知局
- 2024-11-06 15:06:52
本发明涉及生物数据处理领域,具体涉及一种基于深度学习与代谢谱分析的心血管年龄预测方法及装置。
背景技术:
1、随着全球人口老龄化的加剧,心血管疾病负担显著上升,这一趋势促使研究者更加深入地探索衰老与心血管健康风险之间复杂而紧密的生物学联系。衰老通常被定义为功能能力和抗逆能力随时间下降的过程,不仅是大多数慢性疾病发展的基础,还被认为是多种致命疾病如心脏病、神经退行性疾病及癌症的主要风险因素。然而,衰退轨迹不仅在个体之间存在显著差异,甚至在不同器官系统之间也表现出高度的异质性。尤其在心血管系统中,这种异质性反映了个体在生理和病理条件下老化速度的显著差别。因此,寻找能够替代时序年龄并更准确反映心血管系统生理状态的指标,以预测心血管健康风险,显得尤为重要。
2、生物年龄已被广泛视为比实际年龄更为精准的疾病风险评估和死亡率预测指标。生物学年龄(biological age, ba)通过一系列生物标志物对个体的生理状态进行精细衡量,其结果可能显著偏离个体的实际年龄,且生物学年龄的升高往往与更高的疾病风险密切相关。近年来,研究者提出了涵盖表观遗传学、蛋白质组学、糖组学等多个领域的生物衰老标志物,例如通过cpg位点dna甲基化状态测量的“表观遗传时钟”,该方法能够将dna甲基化数据转换为与实际年龄高度相关的预测年龄。此外,白细胞端粒长度作为细胞分裂次数增加而缩短的衰老标志物,以及反映糖基化模式变化的n-糖谱和ink4a/arf基因座表达等,这些标志物共同揭示了个体间衰老速度的差异,并反映了衰老过程的复杂性。
3、与此同时,随着生物医学数据量的爆炸性增长,大规模组学数据的可用性也为分子衰老的分析和解读带来了新的挑战,传统统计学方法在处理和解读这些复杂数据时具有一些弊端,而机器学习(ml)和深度学习(dl)作为现代人工智能的核心技术,因其在大规模数据分析中的强大能力,正日益成为生物医学研究中的关键工具。机器学习算法通过识别数据中的模式,能够处理复杂的非线性关系,适用于分析生物学中的高维数据,特别是在组学数据的应用中,帮助筛选和识别与疾病或健康状态相关的重要特征,并建立预测模型。深度学习则是机器学习的一个子领域,在图像识别、自然语言处理等领域已取得了显著成果,而其在生物医学领域的应用潜力也正在逐步显现。研究者越来越多地采用机器学习和深度学习技术,将组学数据提炼为复合衰老生物标志物,以帮助解释衰老的复杂生物学并指导临床决策。代谢组学作为系统生物学的重要组成部分,测量的是相对分子质量较小的细胞代谢最终产物的浓度,是一种前景广阔的综合评估生物衰老的技术。相比其他组学方法,代谢组学能够提供更完整的生物过程图景和更强的表型代表,在预测生物年龄方面显示出显著优势。通过非靶向代谢组学分析,研究者可以最大程度上捕捉样本中所有代谢物的信息,特别是在心血管健康研究中,通过色谱-质谱联用技术(lc-ms),代谢组学可以高效检测和分析代谢物,提供关于心血管系统状态的关键信息。然而,目前尚无通过代谢组学预测并构建心血管系统年龄的研究。
4、目前现有技术中存在以下几点缺陷:
5、1. 缺乏基于代谢组学的心血管年龄预测研究:目前尚无利用代谢组学构建和预测心血管系统生物年龄的研究,表明这一领域的研究仍处于起步阶段,方法学搭建不足。
6、2. 预测准确性较低:传统的实际年龄不能准确反映个体的心血管系统的生物学衰老过程,导致脑健康风险预测的准确性较低。现有组学技术(如转录组学时钟)的年龄预测准确性在不同队列中高度可变,且显著低于表观遗传学时钟。这种不准确性可能部分归因于数据集成过程中技术噪音的增加,特别是当微阵列和测序数据来自多个平台时。
7、3. 模型基于小规模队列,缺乏广泛验证:目前大多数生物年龄预测模型都是基于小样本量建立,缺乏在大规模独立队列中的验证,因此模型的准确性和可重复性在大规模人群中的表现尚不清楚。
8、4. 成本高昂,限制应用:许多组学方法(如蛋白组学、甲基化组学)成本较高,限制了其在大规模生物样本库和人群健康中的应用,尤其是一些高通量的组学技术,如表观遗传组学和转录组学,虽然可以提供丰富的信息,但其高成本和技术门槛阻碍了在脑健康领域的广泛应用。
9、5. 预测模型过于简单:当前大多数生物年龄预测模型(包括统计学和简单机器学习方法)在处理高维、复杂的组学数据时表现不佳。简单线性回归模型无法捕捉数据中非线性关系和交互效应,对共线性敏感,导致模型不稳定、预测误差增加,缺乏处理复杂数据的能力。
10、以上缺陷表明,尽管心血管生物年龄预测在个性化健康管理和疾病干预中具有巨大潜力,但现有技术和方法的局限性阻碍了其在临床和大规模应用中的发展。
技术实现思路
1、本技术的目的在于针对上述提到的技术问题提出一种基于深度学习与代谢谱分析的心血管年龄预测方法及装置。
2、第一方面,本发明提供了一种基于深度学习与代谢谱分析的心血管年龄预测方法,包括以下步骤:
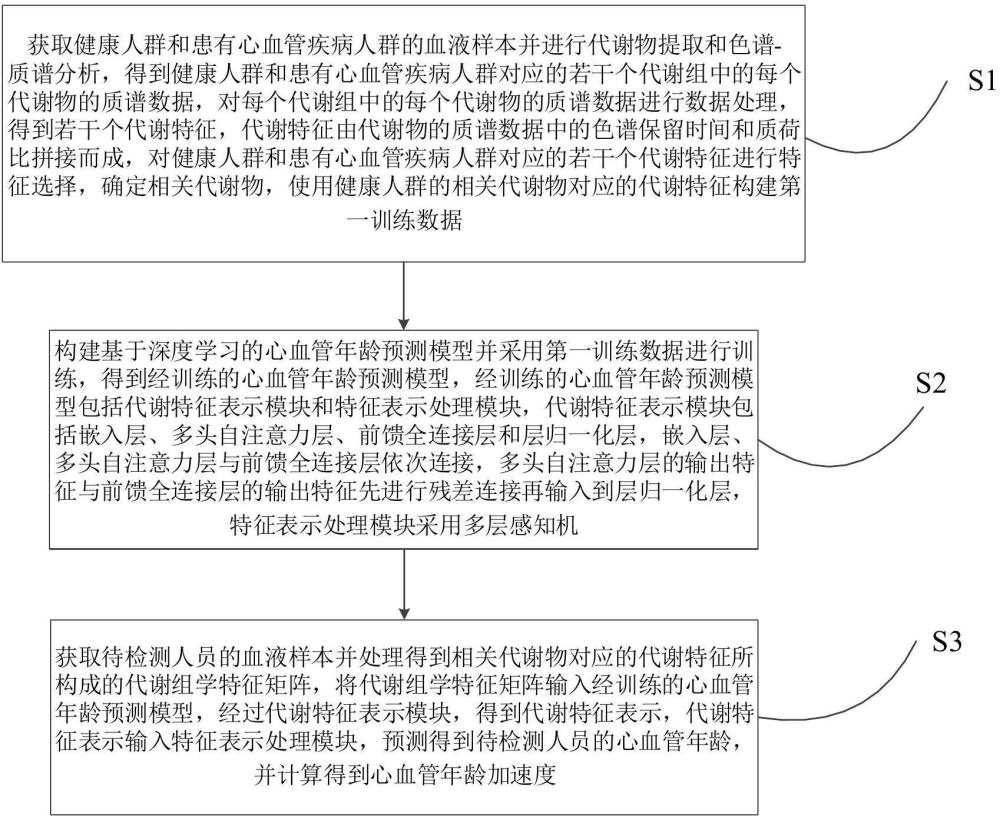
3、获取健康人群和患有心血管疾病人群的血液样本并进行代谢物提取和色谱-质谱分析,得到健康人群和患有心血管疾病人群对应的若干个代谢组中的每个代谢物的质谱数据,对每个代谢组中的每个代谢物的质谱数据进行数据处理,得到若干个代谢特征,代谢特征由代谢物的质谱数据中的色谱保留时间和质荷比拼接而成,对健康人群和患有心血管疾病人群对应的若干个代谢特征进行特征选择,确定相关代谢物,使用健康人群的相关代谢物对应的代谢特征构建第一训练数据;
4、构建基于深度学习的心血管年龄预测模型并采用第一训练数据进行训练,得到经训练的心血管年龄预测模型,经训练的心血管年龄预测模型包括代谢特征表示模块和特征表示处理模块,代谢特征表示模块包括嵌入层、多头自注意力层、前馈全连接层和层归一化层,嵌入层、多头自注意力层与前馈全连接层依次连接,多头自注意力层的输出特征与前馈全连接层的输出特征先进行残差连接再输入到层归一化层,特征表示处理模块采用多层感知机;
5、获取待检测人员的血液样本并处理得到相关代谢物对应的代谢特征所构成的代谢组学特征矩阵,将代谢组学特征矩阵输入经训练的心血管年龄预测模型,经过代谢特征表示模块,得到代谢特征表示,代谢特征表示输入特征表示处理模块,预测得到待检测人员的心血管年龄,并计算得到心血管年龄加速度。
6、作为优选,特征选择所采用的方式包括差异分析特征筛选方式和boruta法特征筛选方式,将差异分析特征筛选方式所得到的代谢物集合和boruta法特征筛选方式所得到的代谢物集合取交集,得到相关代谢物,相关代谢物对应的代谢特征为与心血管疾病年龄相关的代谢特征。
7、作为优选,差异分析特征筛选方式具体包括:
8、将健康人群的代谢特征与患有心血管疾病人群的代谢特征进行双样本t检验,得到p值,采用bh方法对p值进行校正,得到校正后的p值,将满足校正后的p值小于0.05,同时差异倍数大于2或小于1/2的代谢特征所对应的代谢物构成差异分析特征筛选方式所得到的代谢集合,差异倍数为每种代谢物的患有心血管疾病人群中的代谢特征的中位数与健康人群的代谢特征的中位数的倍数比;
9、boruta法特征筛选方式具体包括:
10、构建随机森林模型,随机森林模型包括多棵决策树,将健康人群的代谢特征与患有心血管疾病人群的代谢特征作为原始特征,将原始特征中的数值随机打乱生成影子特征,基于原始特征和影子特征构建第二训练数据,采用第二训练数据对随机森林模型进行训练,将第二训练数据中的代谢特征输入随机森林模型,得到分类结果,分类结果为健康人群或患有心血管疾病人群,针对每个原始特征和每个影子特征,在训练过程中计算每个原始特征和每个影子特征在每棵决策树中每个节点上引起的基尼指数的减少量并进行累加,得到每棵决策树的基尼指数的减少总量,对所有决策树的基尼指数的减少总量取平均值,计算得到每个原始特征的基尼指数平均减少量和每个影子特征的基尼指数平均减少量,根据每个影子特征的基尼指数平均减少量确定所有影子特征中的最大基尼指数平均减少量;
11、响应于当其中一个原始特征的基尼指数平均减少量大于所有影子特征中的最大基尼指数平均减少量时,则将该其中一个原始特征标记为重要特征;
12、响应于当其中一个原始特征的基尼指数平均减少量小于或等于所有影子特征中的最大基尼指数平均减少量时,则将其中一个原始特征标记为不重要特征;
13、将标记为重要特征对应的代谢物作为boruta法特征筛选方式所得到的代谢物集合。
14、作为优选,代谢组学特征矩阵输入代谢特征表示模块,先通过嵌入层将维度为n×m的代谢组学特征矩阵中的每个代谢特征映射成一个256维的向量,得到维度为n×256的嵌入后的特征表示矩阵,其中,n为样本的总数,m为相关代谢物对应的代谢特征的数量;多头自注意力层中包含6个自注意力头,n×256的嵌入后的特征表示矩阵被映射成6组不同的查询矩阵、键矩阵和值矩阵,每组查询矩阵、键矩阵和值矩阵经过每个自注意力头,输出每个输出特征矩阵,将6个输出特征矩阵拼接,得到拼接矩阵,拼接矩阵输入线性变换层,得到多头自注意力层的输出特征;前馈全连接层包括依次连接的第一全连接层和第二全连接层,第一全连接层使用relu激活函数,多头自注意力层的输出特征输入前馈全连接层,依次经过第一全连接层和第二全连接层,得到前馈全连接层的输出特征,多头自注意力层的输出特征与前馈全连接层的输出特征相加后输入层归一化层,得到代谢特征表示。
15、作为优选,多层感知机包括依次连接的输入层、第一隐藏层、第二隐藏层、批量归一化层、dropout层和输出层;输入层用于接收代谢特征表示,第一隐藏层包含256个神经元,并使用relu激活函数;第二隐藏层包含128个神经元,并使用relu激活函数;dropout层中的丢弃比例为0.5,输出层包含1个神经元,并使用线性激活函数,输出心血管年龄。
16、作为优选,基于深度学习的心血管年龄预测模型的训练过程中所使用的总损失函数为:
17、;
18、其中,n是样本的总数,,为第i个样本的均方误差损失函数,为第i个样本的加权损失函数,α和β分别为均方误差损失函数和加权损失函数的权重系数,加权损失函数表示为:
19、;
20、其中,表示权重因子,,γ表示超参数,表示第i个样本的实际年龄,表示第i个样本经过基于深度学习的心血管年龄预测模型预测出的心血管年龄。
21、第二方面,本发明提供了一种基于深度学习与代谢谱分析的心血管年龄预测装置,包括:
22、特征选择模块,被配置为获取健康人群和患有心血管疾病人群的血液样本并进行代谢物提取和色谱-质谱分析,得到健康人群和患有心血管疾病人群对应的若干个代谢组中的每个代谢物的质谱数据,对每个代谢组中的每个代谢物的质谱数据进行数据处理,得到若干个代谢特征,代谢特征由代谢物的质谱数据中的色谱保留时间和质荷比拼接而成,对健康人群和患有心血管疾病人群对应的若干个代谢特征进行特征选择,确定相关代谢物,使用健康人群的相关代谢物对应的代谢特征构建第一训练数据;
23、模型构建模块,被配置为构建基于深度学习的心血管年龄预测模型并采用第一训练数据进行训练,得到经训练的心血管年龄预测模型,经训练的心血管年龄预测模型包括代谢特征表示模块和特征表示处理模块,代谢特征表示模块包括嵌入层、多头自注意力层、前馈全连接层和层归一化层,嵌入层、多头自注意力层与前馈全连接层依次连接,多头自注意力层的输出特征与前馈全连接层的输出特征先进行残差连接再输入到层归一化层,特征表示处理模块采用多层感知机;
24、预测模块,被配置为获取待检测人员的血液样本并处理得到相关代谢物对应的代谢特征所构成的代谢组学特征矩阵,将代谢组学特征矩阵输入经训练的心血管年龄预测模型,经过代谢特征表示模块,得到代谢特征表示,代谢特征表示输入特征表示处理模块,预测得到待检测人员的心血管年龄,并计算得到心血管年龄加速度。
25、第三方面,本发明提供了一种电子设备,包括一个或多个处理器;存储装置,用于存储一个或多个程序,当一个或多个程序被一个或多个处理器执行,使得一个或多个处理器实现如第一方面中任一实现方式描述的方法。
26、第四方面,本发明提供了一种计算机可读存储介质,其上存储有计算机程序,该计算机程序被处理器执行时实现如第一方面中任一实现方式描述的方法。
27、第五方面,本发明提供了一种计算机程序产品,包括计算机程序,计算机程序被处理器执行时实现如第一方面中任一实现方式描述的方法。
28、相比于现有技术,本发明具有以下有益效果:
29、(1)本发明提出的基于深度学习与代谢谱分析的心血管年龄预测方法将代谢组学数据与深度学习模型结合,为心血管系统生物年龄的预测提供了新的方向。这种结合使模型能够利用代谢组学中隐含的生物标志物,更准确地反映个体的心血管生物学状态。代谢组学捕捉了细胞代谢过程中发生的变化,这些变化与心血管系统的衰老过程密切相关。相比于传统的临床指标,代谢组学数据更能反映个体的真实生理状态和衰老程度。能提供多维度的生物信息。
30、(2)本发明提出的基于深度学习与代谢谱分析的心血管年龄预测方法中的心血管年龄预测模型通过在代谢特征表示模块使用改进的transformer模型的编码器结构,能够高效捕捉代谢物之间的复杂相互作用和非线性关系。改进的transformer模型的编码器结构中的多头自注意力机制使其能够并行处理多维特征,捕捉更丰富的特征关系,超越了传统线性回归和简单机器学习模型的能力。利用嵌入层和多头自注意力机制,能够将高维稀疏的代谢组学数据转换为低维稠密的代谢特征表示,减少数据噪音,提高模型的特征表达能力和预测准确性。
31、(3)本发明提出的基于深度学习与代谢谱分析的心血管年龄预测方法能够精准的预测出心血管年龄,能够识别个体的早期老化迹象,为个性化健康管理和疾病预防提供依据,助力于制定个性化的干预措施。通过分析模型提取的代谢组学特征,可能进一步挖掘与心血管老化密切相关的代谢物,为未来的临床研究和干预策略提供重要的生物标志物。代谢组学的检测成本相对较低,数据采集和处理更为简便,特别是在大规模生物样本库和人群健康研究中具有较高的经济可行性,使得本发明能够广泛应用于临床、公共健康和个性化健康管理等领域,为大规模的心血管健康监测和干预策略提供支持。
本文地址:https://www.jishuxx.com/zhuanli/20241106/325384.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。