设备及其语音控制方法、装置和可读存储介质与流程
- 国知局
- 2024-11-18 18:11:21
本发明涉及控制,具体而言,涉及一种设备及其语音控制方法、装置和可读存储介质。
背景技术:
1、相关技术方案中,越来越多的设备支持语音控制。语音控制技术的出现为用户与设备之间的交互提供了便捷。
2、然而,相关技术方案中,设备所支持的语音交互方案多是:利用语音识别模型对用户录入的语音进行语音识别,进而根据识别结果进行控制。
3、采用上述语音交互方案存在以下弊端:
4、在用户的语音输入比较复杂的情况下,语音识别模型所输出的识别结果不尽人意,其语义理解能力有限,处理复杂语境和模糊语义方面仍存在挑战,难以准确地理解用户的需求,从而影响任务执行的准确性和效率。
技术实现思路
1、本发明旨在至少解决现有技术或相关技术中存在的技术问题之一。
2、为此,本发明的第一个方面在于,提供了一种设备的语音控制方法。
3、本发明的第二个方面在于,提供了一种设备的语音控制装置。
4、本发明的第三个方面在于,提供了另一种设备的语音控制装置。
5、本发明的第四个方面在于,提供了一种可读存储介质。
6、本发明的第五个方面在于,提供了一种设备。
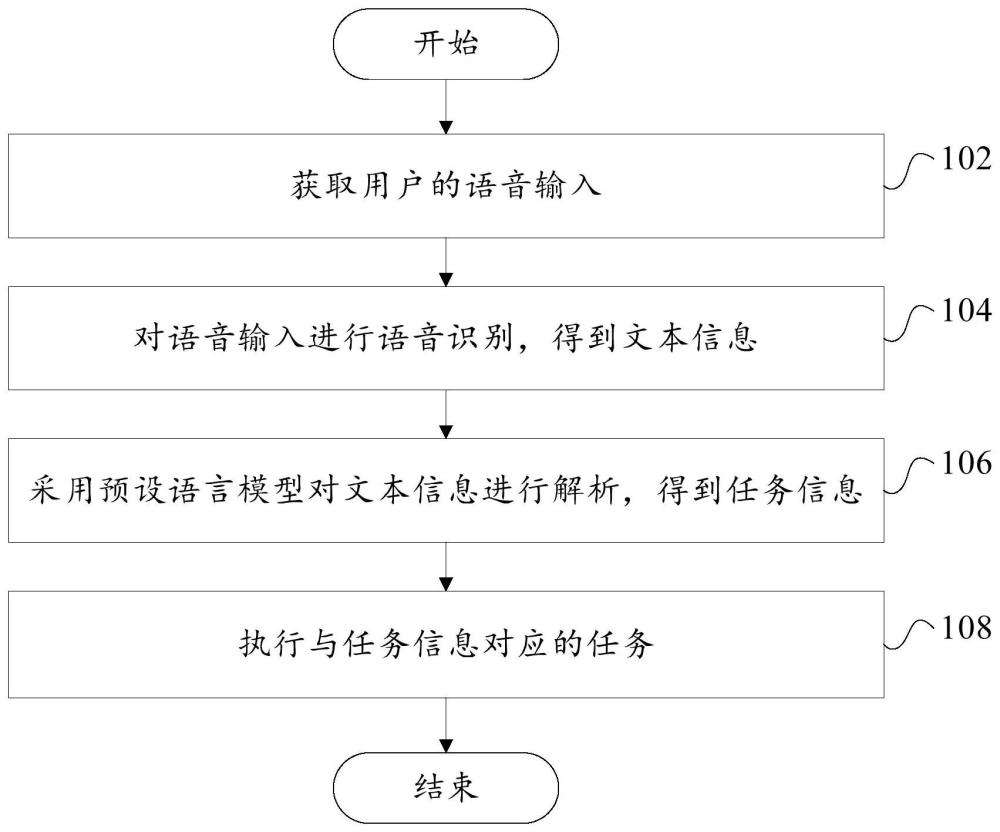
7、有鉴于此,根据本发明的第一个方面,本发明提供了一种设备的语音控制方法,包括:获取用户的语音输入;对语音输入进行语音识别,得到文本信息;采用预设语言模型对文本信息进行解析,得到任务信息;执行与任务信息对应的任务。
8、本技术的技术方案提出了一种设备的语音控制方法,通过运行上述控制方法可以提高语音输入的识别能力,进而在处理复杂语境和模糊语义方面具有较佳的处理表现,进而能够准确理解用户的需求,确保了任务执行的准确性和效率。
9、本技术的技术方案是基于以下原理实现的,具体地,在获取得到语音输入的情况下,通过对语音输入进行语音识别,进而得到与语音输入一一对应的文本信息,再使用预设语言模型对文本信息进行解析,得到任务信息。
10、在此过程中,输入至预设语言模型的是文本信息,相较于直接采用语音输入的方案来说,无需对预设语言模型训练语音识别,降低了模型训练所花费的成本。
11、其中,预设语言模型为大型语言模型,也即大语言模型(large language model,llm)是一种人工智能模型,旨在理解和生成人类语言。它们在大量的文本数据上进行训练,可以执行广泛的任务,包括文本总结、翻译、情感分析。
12、在本技术的技术方案中,利用大型语言模型准确地理解用户需求,确保输出的任务信息的准确性,从而提高任务执行的成功率。
13、在一些技术方案中,可选地,大型语言模型是通过微调和优化后的大型预训练语言模型,其可以是聊天生成预训练转换器(chat generative pre-trained transformer,chatgpt),其可以理解为一种聊天机器人程序,t是人工智能技术驱动的自然语言处理工具,它能够通过理解和学习人类的语言来进行对话,还能根据聊天的上下文进行互动,真正像人类一样来聊天交流,甚至能完成撰写邮件、视频脚本、文案、翻译、代码,写论文等任务。
14、在一些技术方案中,可选地,任务信息为结构化的任务指令。
15、另外,本技术提出的设备的语音控制方法还具有以下附加技术特征。
16、在一些技术方案中,可选地,在生成任务信息的过程中,语音控制方法还包括:基于预设语言模型生成自然语言的反馈信息;在执行与任务信息对应的任务之前,还包括:基于反馈信息合成语音信息;播放语音信息。
17、在该技术方案中,利用预设语言模型生成自然语言形式的反馈信息,在此过程中,可以借助预设语言模型的优势来确保输出的反馈信息于用户的语音输入的匹配程度。通过播放基于反馈信息所合成的语音信息,以便实现设备与用户之间的语音交互,在此过程中,可以实现设备与用户之间形成流畅的交互,从而提高设备的交互体验。
18、在一些技术方案中,可选地,语音合成是将文本信息转换为人类可理解的语音信号。
19、在本发明中,语音合成用于将自然语言的反馈信息转换为语音信号(也即语音信息),以便于用户听取。
20、在一些技术方案中,语音控制方法还包括:输出反馈信息。
21、在该技术方案中,反馈信息可以采用文字的形式输出,以便设备能够采用不同的形式向用户展示反馈信息,进而满足不同场景的交互需要。
22、在一些技术方案中,可选地,对语音输入进行语音识别,得到文本信息,具体包括:采用基于深度学习的语音识别模型对语音输入进行语音识别,得到文本信息。
23、在该技术方案中,基于深度学习的语音识别模型具有较佳的语音合成能力,通过采用上述语音训练模型,以便使得识别所得到的文本信息能够准确的表达用户的想法。相对于采用逐字进行文字识别的识别方案,本技术的技术方案能够更为准确的表达出语音输入所表达的含义,进而充分理解到语音输入的含义。
24、在一些技术方案中,可选地,语音识别是将人类语音信号转换为可被计算机处理的文字信息的过程。在本发明中,语音识别技术用于将用户的语音输入转换为文字,便于后续与预设语言模型进行交互。
25、在一些技术方案中,可选地,语音识别模型可以是长短期记忆网络(long short-term memory,lstm)或自然语言处理的模型。
26、其中,自然语言处理(natural language processing,nlp),自然语言处理是计算机科学、人工智能和语言学的交叉领域,致力于使计算机能够理解、解析和生成人类语言。在本发明中,自然语言处理技术被用于解析用户的语音输入,提取关键信息,并与预设语言模型进行交互,以生成结构化任务指令(也即任务信息)和自然语言反馈(也即反馈信息)。
27、在一些技术方案中,可选地,基于反馈信息合成语音信息,具体包括:基于深度学习的端到端语音合成模型,对反馈信息进行语音合成,得到语音信息。
28、在该技术方案中,通过合成语音信息,以便用户与设备之间能够通过语音进行交互,克服了相关技术方案中,用于控制设备运行的命令对手动输入或固定的命令集的依赖,从而提高了用户与设备之间的交互体验。
29、在一些技术方案中,可选地,端到端语音合成模型可以是基于tacotron的语音合成模型。
30、在该技术方案中,采用上述端到端语音合成模型,使得生成的语音信息的语句更加自然、流畅,使得用户与设备之间的交互更加自然、便捷,提高用户体验和接受度。
31、在一些技术方案中,可选地,任务信息包括至少一个任务时间和对应的任务执行地点;执行与任务信息对应的任务,具体包括:基于至少一个任务时间和对应的任务执行地点,确定任务执行路径;基于任务执行路径,执行与任务信息对应的任务。
32、在该技术方案中,在语音输入包含多个任务的情况下,预设语言模型在对文本信息进行解析的过程中,能够解析出每一个任务对应的任务时间以及任务时间对应的任务执行地点,进而根据解析得到的任务时间和任务执行地点来确定任务执行路径,以便设备在作业的过程中,能够以任务执行路径作为任务执行的引导,从而更为准确的理解用户需求,提高任务执行的成功率。
33、在上述技术方案中,任务执行路径可以理解为在存在多个任务的情况下,多个任务先后执行的排列次序。
34、在一些技术方案中,任务执行路径以每一任务所对应的任务时间作为排序条件,其中,任务时间包括执行任务时的开始时间和结束时间,以便提高任务执行的可靠性。
35、在一些技术方案中,可选地,设备为清洁机器人或服务机器人,语音控制方法,还包括:获取设备的当前位置信息;根据当前位置信息和任务执行路径确定导航路径;其中,设备基于导航路径行走。
36、在该技术方案中,在设备运行的过程中,通过获取当前位置信息,以便根据当前位置信息、结合任务执行路径来指导设备的行走,在此过程中,设备可以实现自主行走,进而自动执行作业。
37、在此过程中,无需用户参与设备的移动,克服了设备需要用户手动参与下才能作业的弊端,提高了作业的效率。
38、在一些技术方案中,可选地,服务机器人可以是宾馆的客房机器人、亦或是用于餐厅上菜的移动机器人,服务机器人可以根据其使用场景的不同部署不同的功能,在此不再进行赘述。
39、在一些技术方案中,可选地,当前位置信息可以通过设置在设备上的位置传感器获取得到。
40、其中,位置传感器可以根据实际使用场景来选择对应的传感器,其具体选型,在此不再进行赘述。
41、在一些技术方案中,可选地,还包括:获取设备所处环境的环境信息;基于环境信息更新导航路径。
42、在该技术方案中,通过获取环境信息,以便设备在行走的过程中,能够根据环境信息更新导航路径,减少与环境中的其它物体出现撞击,以此来实现动态避障,最大程度的保护设备自身的安全的同时,减少设备运行对环境中的其它物体所带来的影响。
43、在一些技术方案中,可选地,环境信息包括环境中除设备之外的其它物体的摆放位置信息。
44、在一些技术方案中,可选地,环境信息在包含其它物体的摆放位置信息的同时,还包括其它物体的位姿信息。
45、在该技术方案中,通过获取上述信息,能够最大程度的进行避障。
46、在一些技术方案中,可选地,环境信息采用摄像头、激光雷达、红外传感器中的一种或多种来实现获取和感知。
47、在一些技术方案中,可选地,还包括:在任务信息包括用于表示重复执行的关键词的情况下,确定与关键词关联的开始时间、结束时间和目标任务;基于开始时间、结束时间和目标任务确定周期任务。
48、在该技术方案中,关键词可以是每周、每间隔、每月、每天这类能够表达重复执行的词语,其可以根据实际使用场景来选取,在此不再进行赘述。
49、在上述技术方案中,开始时间、结束时间和目标任务可以通过对语音输入进行识别、解析得到,在此不再进行赘述。
50、在上述技术方案中,通过确定周期任务,以便设备能够周期性执行任务,无需用户重复下达语音输入的指令,便于减少用户与设备之间的交互频率,从而提高了设备的使用体验。
51、在一些技术方案中,可选地,采用预设语言模型对文本信息进行解析,得到任务信息,包括:将文本信息发送至部署在服务器上的预设语言模型;接收来自预设语言模型输出的任务信息。
52、在该技术方案中,通过将文本信息发出,以便部署在服务器上的预设语言模型能够对接收到的文本信息进行处理,进而得到任务信息。在此过程中,能够将文本信息的处理过程从设备端的本地转移到云端,也即服务器侧,利用服务器算力大、充足的特点来进行数据处理,以便提高了数据处理的速度,以便满足不同场景下的不同需求。
53、根据本发明的第二个方面,本发明提供了一种设备的语音控制装置,包括:人机交互模块,用于获取用户的语音输入;语音识别模块,用于对语音输入进行语音识别,得到文本信息;生成模块,用于采用预设语言模型对文本信息进行解析,得到任务信息;执行模块,用于执行与任务信息对应的任务。
54、本技术的技术方案提出了一种设备的语音控制装置,可以提高语音输入的识别能力,进而在处理复杂语境和模糊语义方面具有较佳的处理表现,进而能够准确理解用户的需求,确保了任务执行的准确性和效率。
55、本技术的技术方案是基于以下原理实现的,具体地,在获取得到语音输入的情况下,通过对语音输入进行语音识别,进而得到与语音输入一一对应的文本信息,再使用预设语言模型对文本信息进行解析,得到任务信息。
56、在此过程中,输入至预设语言模型的是文本信息,相较于直接采用语音输入的方案来说,无需对预设语言模型训练语音识别,降低了模型训练所花费的成本。
57、其中,预设语言模型为大型语言模型,也即大语言模型(large language model,llm)是一种人工智能模型,旨在理解和生成人类语言。它们在大量的文本数据上进行训练,可以执行广泛的任务,包括文本总结、翻译、情感分析。
58、在本技术的技术方案中,利用大型语言模型准确地理解用户需求,确保输出的任务信息的准确性,从而提高任务执行的成功率。
59、在一些技术方案中,可选地,大型语言模型是通过微调和优化后的大型预训练语言模型,其可以是聊天生成预训练转换器(chat generative pre-trained transformer,chatgpt),其可以理解为一种聊天机器人程序,t是人工智能技术驱动的自然语言处理工具,它能够通过理解和学习人类的语言来进行对话,还能根据聊天的上下文进行互动,真正像人类一样来聊天交流,甚至能完成撰写邮件、视频脚本、文案、翻译、代码,写论文等任务。
60、在一些技术方案中,可选地,任务信息为结构化的任务指令。
61、另外,本技术提出的设备的语音控制装置还具有以下附加技术特征。
62、在一些技术方案中,可选地,在生成任务信息的过程中,生成模块还用于:基于预设语言模型生成自然语言的反馈信息;在执行与任务信息对应的任务之前,设备的语音控制装置还包括:语音合成模块,用于基于反馈信息合成语音信息;播放语音信息。
63、在该技术方案中,利用预设语言模型生成自然语言形式的反馈信息,在此过程中,可以借助预设语言模型的优势来确保输出的反馈信息于用户的语音输入的匹配程度。通过播放基于反馈信息所合成的语音信息,以便实现设备与用户之间的语音交互,在此过程中,可以实现设备与用户之间形成流畅的交互,从而提高设备的交互体验。
64、在一些技术方案中,可选地,语音合成是将文本信息转换为人类可理解的语音信号。
65、在本发明中,语音合成用于将自然语言的反馈信息转换为语音信号(也即语音信息),以便于用户听取。
66、在一些技术方案中,语音控制方法还包括:输出反馈信息。
67、在该技术方案中,反馈信息可以采用文字的形式输出,以便设备能够采用不同的形式向用户展示反馈信息,进而满足不同场景的交互需要。
68、在一些技术方案中,可选地,语音识别模块具体用于:采用基于深度学习的语音识别模型对语音输入进行语音识别,得到文本信息。
69、在该技术方案中,基于深度学习的语音识别模型具有较佳的语音合成能力,通过采用上述语音训练模型,以便使得识别所得到的文本信息能够准确的表达用户的想法。相对于采用逐字进行文字识别的识别方案,本技术的技术方案能够更为准确的表达出语音输入所表达的含义,进而充分理解到语音输入的含义。
70、在一些技术方案中,可选地,语音识别是将人类语音信号转换为可被计算机处理的文字信息的过程。在本发明中,语音识别技术用于将用户的语音输入转换为文字,便于后续与预设语言模型进行交互。
71、在一些技术方案中,可选地,语音识别模型可以是长短期记忆网络(long short-term memory,lstm)或自然语言处理的模型。
72、其中,自然语言处理(natural language processing,nlp),自然语言处理是计算机科学、人工智能和语言学的交叉领域,致力于使计算机能够理解、解析和生成人类语言。在本发明中,自然语言处理技术被用于解析用户的语音输入,提取关键信息,并与预设语言模型进行交互,以生成结构化任务指令(也即任务信息)和自然语言反馈(也即反馈信息)。
73、在一些技术方案中,可选地,语音合成模块,具体用于:基于深度学习的端到端语音合成模型,对反馈信息进行语音合成,得到语音信息。
74、在该技术方案中,通过合成语音信息,以便用户与设备之间能够通过语音进行交互,克服了相关技术方案中,用于控制设备运行的命令对手动输入或固定的命令集的依赖,从而提高了用户与设备之间的交互体验。
75、在一些技术方案中,可选地,端到端语音合成模型可以是基于tacotron的语音合成模型。
76、在该技术方案中,采用上述端到端语音合成模型,使得生成的语音信息的语句更加自然、流畅,使得用户与设备之间的交互更加自然、便捷,提高用户体验和接受度。
77、在一些技术方案中,可选地,任务信息包括至少一个任务时间和对应的任务执行地点;执行模块,具体用于:基于至少一个任务时间和对应的任务执行地点,确定任务执行路径;基于任务执行路径,执行与任务信息对应的任务。
78、在该技术方案中,在语音输入包含多个任务的情况下,预设语言模型在对文本信息进行解析的过程中,能够解析出每一个任务对应的任务时间以及任务时间对应的任务执行地点,进而根据解析得到的任务时间和任务执行地点来确定任务执行路径,以便设备在作业的过程中,能够以任务执行路径作为任务执行的引导,从而更为准确的理解用户需求,提高任务执行的成功率。
79、在上述技术方案中,任务执行路径可以理解为在存在多个任务的情况下,多个任务先后执行的排列次序。
80、在一些技术方案中,任务执行路径以每一任务所对应的任务时间作为排序条件,其中,任务时间包括执行任务时的开始时间和结束时间,以便提高任务执行的可靠性。
81、在一些技术方案中,可选地,设备为清洁机器人或服务机器人,语音控制装置,还包括:位置信息模块,用于获取设备的当前位置信息;路径规划模块,用于根据当前位置信息和任务执行路径确定导航路径;其中,设备基于导航路径行走。
82、在该技术方案中,在设备运行的过程中,通过获取当前位置信息,以便根据当前位置信息、结合任务执行路径来指导设备的行走,在此过程中,设备可以实现自主行走,进而自动执行作业。
83、在此过程中,无需用户参与设备的移动,克服了设备需要用户手动参与下才能作业的弊端,提高了作业的效率。
84、在一些技术方案中,可选地,服务机器人可以是宾馆的客房机器人、亦或是用于餐厅上菜的移动机器人,服务机器人可以根据其使用场景的不同部署不同的功能,在此不再进行赘述。
85、在一些技术方案中,可选地,当前位置信息可以通过设置在设备上的位置传感器获取得到。
86、其中,位置传感器可以根据实际使用场景来选择对应的传感器,其具体选型,在此不再进行赘述。
87、在一些技术方案中,可选地,还包括:传感器模块,用于获取设备所处环境的环境信息;路径规划模块还用于基于环境信息更新导航路径。
88、在该技术方案中,通过获取环境信息,以便设备在行走的过程中,能够根据环境信息更新导航路径,减少与环境中的其它物体出现撞击,以此来实现动态避障,最大程度的保护设备自身的安全的同时,减少设备运行对环境中的其它物体所带来的影响。
89、在一些技术方案中,可选地,环境信息包括环境中除设备之外的其它物体的摆放位置信息。
90、在一些技术方案中,可选地,环境信息在包含其它物体的摆放位置信息的同时,还包括其它物体的位姿信息。
91、在该技术方案中,通过获取上述信息,能够最大程度的进行避障。
92、在一些技术方案中,可选地,环境信息采用摄像头、激光雷达、红外传感器中的一种或多种来实现获取和感知。
93、在一些技术方案中,可选地,还包括:时间管理模块,用于在任务信息包括用于表示重复执行的关键词的情况下,确定与关键词关联的开始时间、结束时间和目标任务;基于开始时间、结束时间和目标任务确定周期任务。
94、在该技术方案中,关键词可以是每周、每间隔、每月、每天这类能够表达重复执行的词语,其可以根据实际使用场景来选取,在此不再进行赘述。
95、在上述技术方案中,开始时间、结束时间和目标任务可以通过对语音输入进行识别、解析得到,在此不再进行赘述。
96、在上述技术方案中,通过确定周期任务,以便设备能够周期性执行任务,无需用户重复下达语音输入的指令,便于减少用户与设备之间的交互频率,从而提高了设备的使用体验。
97、在一些技术方案中,可选地,还包括:云计算模块,用于将文本信息发送至部署在服务器上的预设语言模型;以及接收来自预设语言模型输出的任务信息。
98、在该技术方案中,通过将文本信息发出,以便部署在服务器上的预设语言模型能够对接收到的文本信息进行处理,进而得到任务信息。在此过程中,能够将文本信息的处理过程从设备端的本地转移到云端,也即服务器侧,利用服务器算力大、充足的特点来进行数据处理,以便提高了数据处理的速度,以便满足不同场景下的不同需求。
99、根据本发明的第三个方面,本发明提供了一种设备的语音控制装置,包括处理器和存储器,存储器存储可在处理器上运行的程序或指令,程序或指令被处理器执行时实现如第一方面中任一项的方法的步骤。
100、根据本发明的第四个方面,本发明提供了一种可读存储介质,可读存储介质上存储程序或指令,程序或指令被处理器执行时实现如第一方面中任一项的方法的步骤。
101、根据本发明的第五个方面,本发明提供了一种设备,包括:如上述任意方面中的设备的语音控制装置;和/或如上述可读存储介质。
102、在一些技术方案中,可选地,设备包括以下之一:清洁机器人或服务机器人。
103、本发明的附加方面和优点将在下面的描述中部分给出,部分将从下面的描述中变得明显,或通过本发明的实践了解到。
本文地址:https://www.jishuxx.com/zhuanli/20241118/327513.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。