一种用于区域健康大数据的分水岭聚类方法
- 国知局
- 2024-11-18 18:14:41
本发明属于大数据处理与模式识别,尤其涉及一种用于区域健康大数据的分水岭聚类方法。
背景技术:
1、人口的快速增长和医疗数据的信息化,导致不同区域的健康数据都在呈现出海量化、模式多样化、数据高维度化和结构自由化。这些大规模健康数据的数据模式(类,簇,群)的规模也随时间跨度和样本数量的增长而增大。从区域健康大数据中检测和挖掘不同健康数据模式,比如健康人群,亚健康人群,不同疾病人群,及其不同人群所反映出的模式信息,不仅能够推进基于健康大数据的准确治疗、“中医治未病”理念和技术、基因靶向治疗等新医疗的发展,而且可以推进康养产业的发展,进而达到减少宝贵医疗健康数据资源的浪费。然而,在数据空间(样本空间)的结构分析过程中,我们发现数据的复杂性表现为多种形式,例如:(1)类的形状多样性;(2)类之间的规模、边界重叠度差异较大;(3)类内弱连通近似于类间距;(4)数据的维度灾难问题导致空空间和距离集中现象等。
2、现有的聚类方法一定程度上缓减了复杂数据结构对数据聚类的影响。例如,中心聚类方法(k-means)解决了能够较好检测边界重叠的高斯类的检测。密度聚类算法方法(dbscan)能够识别不规则形状数据模式。密度峰值聚类方法(dpc)能够解决类边界重叠,并且根据指定类数量、密度峰值点和密度扩散策略检测出不规则形状的数据类。然而,由于区域健康大数据的规模大,混合了多种复杂数据结构,囊括数据模式多,难以获得数据模式的先验知识,加之离群数据点和异常数据类的影响,使得k-means和dpc等基于预指定类数据的聚类方法表现较差。尽管dbscan方法不需预先指定簇的数量且运行速度快,但其及变体方法仍然受统一阈值的影响,难以解决不同类的密度差异和类边界高重叠度带来的影响,进而产生过度分割和过度吸收现象。此外,现有分水岭聚类方法获得了较好性能,但是其二次地形拓扑化和基于角度的离群点的计算成本较大,导致时间复杂度过高。这也是现有密度聚类、中心聚类等方法存在的不足和局限性。
技术实现思路
1、为解决上述技术问题,本发明提出了一种用于区域健康大数据的分水岭聚类方法,以解决上述现有技术存在的问题。
2、为实现上述目的,本发明提供了一种用于区域健康大数据的分水岭聚类方法,包括:
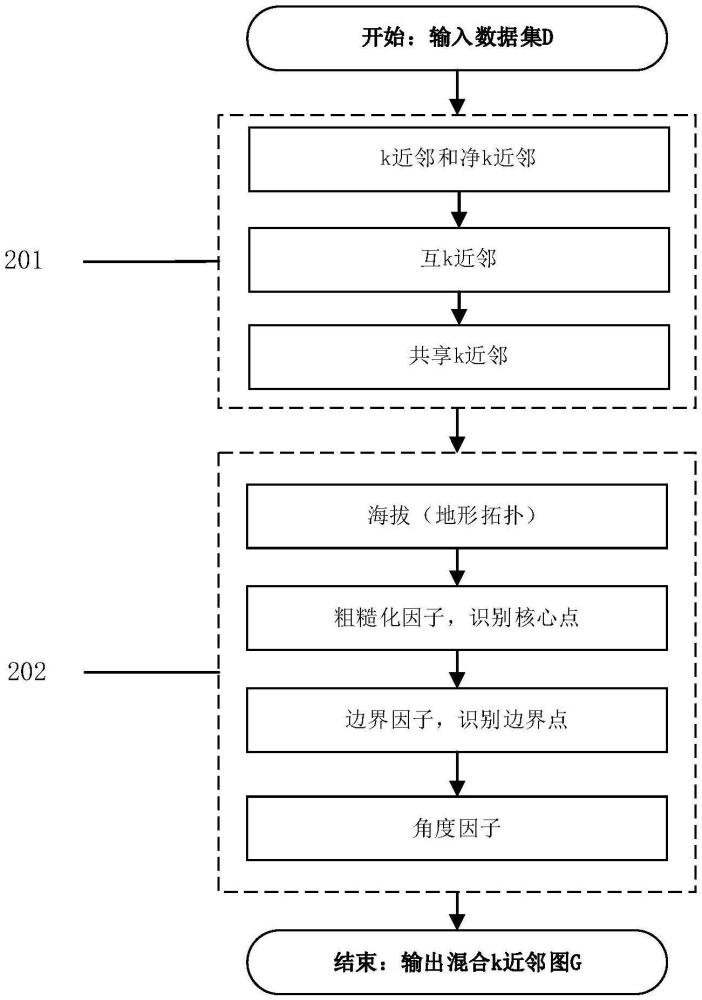
3、基于输入的数据集构建混合k近邻图,所述混合k近邻图包括边权重集和顶点属性集,基于所述顶点属性集的粗糙因子和边界因子分别识别核心点和边界点;
4、基于所述核心点与核心点的近邻成员的海拔和近邻信息发现集水盆集和集水盆连接集;
5、基于稳定因子从所述集水盆连接集中识别有效集水盆连接,利用集水盆级相似性合并集水盆得到合并后的集水盆;
6、利用近邻信息和边界点聚合未被聚类的数据点到集水盆,得到最终的数据聚类。
7、可选地,构建混合k近邻图的过程包括:
8、采用欧氏距离对输入的数据集计算数据点的k近邻信息得到混合k近邻图的边权重集;其中,所述边权重集包括:k近邻、净k近邻、互k近邻和共享k近邻;
9、基于数据点的k近邻信息计算混合k近邻图的顶点属性集;其中,所述顶点属性集包括海拔,粗糙化因子、边界因子和角度因子。
10、可选地,数据点的海拔计算公式为:
11、
12、式中,α(xi)表示数据点xi的海拔,w_dist(xi,xj)表示xi到近邻xj距离与xi到其净t近邻的距离和之比率系数,β(xi,xj)表示xi与近邻xj之间的基于共享近邻的距离均值,pnt(xi)表示xi的净t近邻,t≤k。
13、可选地,数据点的粗糙化因子计算公式为:
14、
15、式中,θ(xi)表示粗糙化因子,cfi(xi,xj)表示一个指示函数。
16、可选地,数据点的边界因子计算公式为:
17、
18、式中,π(xi)表示边界因子,e(xi)表示反方向等距离点,m(xi)表示局部中心点,bfi(xj,m(xi),e(xi))表示角度指示函数。
19、可选地,数据点的角度因子计算公式为:
20、
21、式中,表示角度因子,表示xi的归一化的t近邻球的半径,ζ(xi)表示xi的归一化的t近邻球的中心偏移量,表示xi到净t近邻的最后成员的距离,srpc(pnt(xi))={pg1,…,pgj,…,pgm},pgi表示点xi关于t近邻的点xj的共享近邻分组的点集合,pgs(srpc(pnt(xi)))表示所有分组点二元子集的集合,γ(xi)表示xi与被分组净t近邻形成的角度密度。
22、可选地,发现集水盆集和集水盆连接集的过程包括:
23、s1、对所述混合k近邻图采用顶点属性集中的海拔升序排列所有数据点得到初始数据点队列,并初始化集水盆集和集水盆连接集;
24、s2、顺序提取初始数据点队列的队头数据点,当所述队头数据点为核心点且未被聚合,则将当前队头数据点添加新集水盆至集水盆集;
25、s3、从当前队头数据点的k近邻队列顺序提取近邻成员,当当前队头数据点和近邻成员的海拔和近邻信息满足共享近邻法则、拉依达法则和投票法时,进行聚合;
26、s4、循环执行s2-s3,直至数据点为空得到集水盆集和集水盆连接集。
27、可选地,利用集水盆级相似性合并集水盆的过程包括:
28、s5、基于所述集水盆连接集的连接对的海拔升序排列连接对得到连接对队列;
29、s6、顺序提取连接对队列的队头连接对,计算连接对中成员的稳定因子,当所述稳定因子大于0.2时执行s7,否则执行s6;
30、s7、当连接对中的成员至少有一个为集水盆的盆点时,合并集水盆;当连接对中的成员均不为盆点,且连接对中的成员至少有一个位于所属集水盆的一半以下海拔时,合并集水盆;
31、s8、循环执行s6-s7,当连接对队列为空时,输出合并后的集水盆。
32、可选地,所述稳定因子的计算公式为:
33、
34、式中,χ(xi)表示稳定因子,xi表示集水盆连接(i,j)中的任意成员;θ(xi)表示xi的粗糙化因子;表示xi的角度因子;max()表示最大值运算;表示xi所属集水盆;表示xi所属集水盆的竞争点集。
35、可选地,利用近邻信息和边界点聚合未被聚类的数据点到集水盆的过程包括:
36、s9、基于未被聚类的数据点得到非核心点,将所述非核心点根据海拔升序排序得到非核心点队列;
37、s10、顺序提取非核心点队列的队头非核心点,从当前的队头非核心点的k近邻中顺序获取最近且已经被聚类的数据点,当当前的队头非核心点和k近邻中被聚类的数据点的局部区域海拔和近邻信息满足共享近邻法则和拉依达法则时,将当前的队头非核心点聚合到k近邻中被聚类的数据点所属集水盆,否则执行s10;
38、s11、当当前的队头非核心点为边界点时,根据共享近邻法则,将当前的队头非核心点聚合到k近邻中被聚类的数据点所属集水盆;
39、s12、循环执行s10-s11,当非核心点队列为空时,输出最终的数据聚类。
40、与现有技术相比,本发明具有如下优点和技术效果:
41、本发明利用分水岭算法的思想,实现了自动聚类和获取类数量,克服了传统聚类方法需要预先指定类数量的缺陷;结合地形拓扑方法和重叠高斯分布方法,提出了用于多维度、多模式的区域健康大数据的一种新分水岭聚类方法。
42、本发明结合互k近邻法则、拉依达法则和基于四分位数的变异性度量方法,提出了粗糙化因子,用于度量数据点的核心性。相比于密度聚类的基于截距和密度阈值的核心点度量方法,融合了图论、地形拓扑、局部信息和数据变异性度量,进一步提升了识别核心点的效果。
43、本发明相比于简单考虑密度信息的密度聚类方法,结合数据点的边界性和粗糙因子,提出了用于检测有效集水盆连接的稳定因子,实现集水盆之间有效连接的准确识别,避免了不同类的子类之间的无效连接产生聚合,进一步提升聚类准确度。
44、本发明克服了现有分水岭聚类方法和传统密度聚类方法未能处理多种复杂结构的局限性,包括多密度、不规则形状、类内弱连通、类边界重叠等复杂结构,提高了聚类性能和结果。
本文地址:https://www.jishuxx.com/zhuanli/20241118/327779.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表