一种基于尺度匹配与语义增强的跨域小样本目标检测方法
- 国知局
- 2024-11-19 09:44:54
本发明涉及目标检测、计算机视觉,特别是一种基于尺度匹配与语义增强的跨域小样本目标检测方法。
背景技术:
1、在目标检测领域,小样本设置是一个重要而富有挑战性的课题。传统的小样本目标检测范式往往涉及两个阶段:首先在基类构成的源数据集上进行预训练,随后将预训练的检测器迁移至目标数据集,该数据集包含少量属于全新类别的实例,这些实例与基类不重叠,但数据领域相似。然而,这种设置在实际应用中,特别是在医疗和航空等特定领域,存在显著局限性。在这些领域中,由于数据收集的困难性和敏感性,很难或几乎不可能获得足够数量的目标类别样本,更不用说满足领域相似的假设。随着计算机视觉技术的快速发展,目标检测作为其中的关键任务之一,已经取得了显著的进步。然而,在实际应用中,跨域小样本目标检测仍然是一个具有挑战性的问题。这主要是由于不同领域或场景下的目标在尺度、形状、纹理等方面存在较大的差异,同时小样本数据又增加了模型的泛化难度。传统的目标检测方法主要依赖于大量的标注数据进行训练,但在跨域小样本场景下,这样的数据往往难以获取。因此,如何有效地利用有限的标注数据,并克服跨域差异,成为目标检测领域亟待解决的问题。
技术实现思路
1、有鉴于此,本发明的目的在于提供一种基于尺度匹配与语义增强的跨域小样本目标检测方法,通过知识蒸馏的强弱增强架构,提升跨域情况下的锚框匹配以及利用语义空间对数据样本进行插值或外推,进行了隐式语义的数据扩充,增加了样本的多样性。
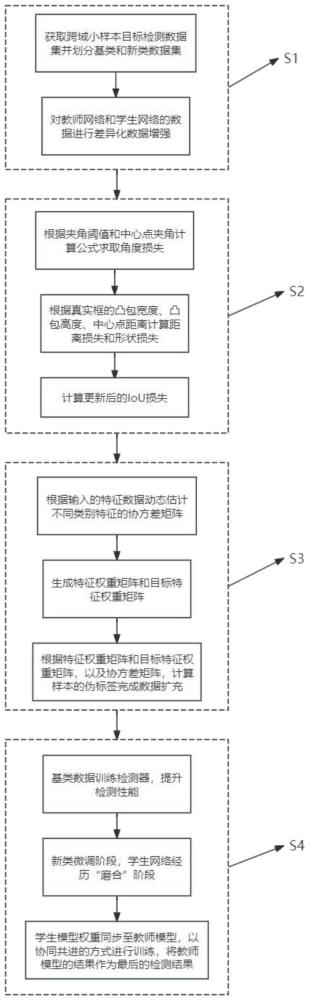
2、为实现上述目的,本发明采用如下技术方案:一种基于尺度匹配与语义增强的跨域小样本目标检测方法,包括以下步骤:
3、步骤s1:通过跨域小样本目标检测通用训练集,并分别对数据采用强弱数据增强方法,将数据分别送入resnet50骨干网络中训练特征;
4、步骤s2:采用已训练的特征提取网络作为特征提取模块,引入跨域尺度形状优化匹配模块,解决不同域的情况下的尺度形状影响检测精度的问题;
5、步骤s3:设计动态语义协方差增强模块,利用语义空间对数据样本进行插值或外推,来生成新的数据样本,从而对数据进行扩充;
6、步骤s4:进行知识蒸馏,教师模型与学生模型以协同共进的方式进行训练;教师模型利用蒸馏损失指导学生模型,促进其性能提升;而学生模型则通过指数移动平均ema策略持续优化参数权重,逐步向教师模型靠拢;最终用教师模型的特征进行跨域小样本目标检测。
7、在一较佳的实施例中,步骤s1具体包括以下步骤:
8、步骤s11:从网络上获取公开的小样本分割训练集,并获得训练数据的相关标注;模型是从基类数据集中每个类都有大量注释实例进行训练,然后将模型迁移并微调到目标数据集中每个类只有很少样本的情况;基类数据集和新类数据集来自不同的领域,将mscoco2017数据集设定为基类数据集,而将artaxor、uodd、dior数据集作为新类数据集,它们的领域分别为生物领域、水下领域和航空领域;
9、步骤s12:在数据载入后对教师网络和学生网络的数据进行不同的数据增强;教师网络采用弱增强方法,即随机翻转,学生网络实施增强措施,包括随机颜色抖动、灰度化、高斯模糊和随机剪切,以模拟真实场景中的复杂变化,并迫使学生网络学习更为鲁棒的特征表示;
10、步骤s13:对跨域小样本目标检测数据集中的待检测图像采用预训练的resnet50特征提取网络初始化网络权重和参数。
11、在一较佳的实施例中,步骤s2具体包括以下步骤:
12、步骤s21:定义a表示检测框,b表示真实框,area(·)表示对应区域的面积,a∩b表示检测框和真实框的交集区域;首先,获得每个检测框宽度w和高度h,以及真实框的宽度w′和高度h′,并由此计算它们的面积area(a)和area(b);具体计算如下所示:
13、area(a)=w×h,area(b)=w′×h′
14、步骤s22:计算检测框和真实框中心点的宽度差scw和高度差sch,以及它们之间的距离sigma;计算公式如下所示:
15、
16、其中,x′min、x′max分别为真实框的最小和最大横坐标,xmin、xmax分别为检测框的最小和最大横坐标;同理,y′min、y′max分别为真实框的最小和最大纵坐标,ymin、ymax分别为检测框的最小和最大纵坐标;
17、步骤s23:根据夹角阈值threshold和中心点夹角α的计算公式,求取角度损失angle_cost;中心点夹角的计算公式如下所示,角度损失计算公式具体如下所示:
18、
19、其中,σ表示的是锚框的尺度;
20、步骤s24:计算检测框和真实框的凸包宽度cw和凸包高度ch,以及中心点距离sigma,进而计算距离损失distance_cost和形状损失shape_cost;其中凸包宽度cw是指检测框和真实框在水平方向上的最大距离,即检测框和真实框水平方向上的最大重叠长度;凸包高度ch则是指检测框和真实框在垂直方向上的最大距离,即检测框和真实框垂直方向上的最大重叠高度;具体计算公式如下所示:
21、cw=max(w,w′),ch=max(h,h′)
22、
23、distance_cost=2-exp(γ·rhox)-exp(γ·rhoy)
24、
25、其中,w为检测框宽度,h为检测框高度,w′为真实框的宽度,h′为真实框的高度;在形状和距离损失的计算中,引入了rho值,用于衡量检测框和真实框之间的形状差异;rhox指的是检测框和真实框的宽度上的差异;rhoy指的是检测框和真实框的高度上的差异;rho值的计算涉及到中心点差异scw和sch与凸包宽度cw和凸包高度ch的比值;∈是一个极小的正数,用于防止凸包宽度cw和凸包高度ch为零时,导致rho的计算出现除以零的情况;γ代表一个权重参数,用于调节形状和距离损失的相对重要性;γ越大,表示形状损失和距离损失对dssom值的影响越大;γ越小,则表示形状损失和距离损失的影响相对较小;
26、步骤s25:根据交集区域的计算公式,计算交集区域的面积irtterarea,具体计算如下所示:
27、irtterarea=(xmax_inter-xmin_inter)×(ymax_inter-ymin_inter)
28、其中,xmax_inter和xmin_inter为交集区域的最大横坐标和最小横坐标;ymax_inter和ymin_inter为交集区域的最大纵坐标和最小纵坐标;
29、步骤s26:最后,将交集区域的面积除以并集区域的面积,再减去距离损失和形状损失的一半,得到最终的iou损失值ldssom,具体计算公式如下所示:
30、
31、在一较佳的实施例中,步骤s3具体包括以下步骤:
32、步骤s31:设计协方差矩阵的估计模块,根据输入的特征数据动态估计不同类别特征的协方差矩阵;这个模块在训练过程中维护着每个类别的协方差矩阵、均值矩阵和样本数量信息,并根据新的样本来更新这些统计信息;
33、首先将特征重塑成n×1×a的形状以匹配后续操作所需的维度,n和a分别为样本数量和特征数量;然后计算标签的one-hot编码以确定每个样本的类别成员关系;接着,计算每个类别下的特征数据的均值向量avec,a,作为该类别特征的代表性向量;avec,a的具体计算公式如下所示:
34、
35、其中,c表示类别索引,a表示特征向量的维度,featuresi,a为重塑后的特征值,i表示样本索引,onehot c,i为样本i的one-hot类别向量,amountc,a表示类别c的特征数量;
36、步骤s32:在上述协方差矩阵生成的基础上进行隐式语义的数据扩充;首先,从网络的权重中获取特征权重矩阵m_ij,它将特征映射到类别空间;该矩阵的形状为n×c×a,其中:n是样本数量,c是类别数量,a是特征数量;特征权重矩阵m_ij的公式如下所示:
37、m_ij=weight_m×ones(n,c,a)
38、其中,weight_m是网络的权重参数,ones(n,c,a)是形状为n×c×a的全1张量;
39、步骤s33:根据真实标签labels从特征权重矩阵中获取目标特征权重矩阵m_kj,用于计算样本的伪标签;目标特征权重矩阵的形状与特征权重矩阵相同;目标特征权重矩阵m_kj的公式如下所示:
40、m_kj=gather(m_ij,1,labels)
41、其中,gather(·)表示按照给定维度进行索引;
42、步骤s34:根据特征权重矩阵和目标特征权重矩阵,以及协方差矩阵,计算样本的伪标签isda_aug_y;伪标签将用于计算损失值,伪标签isda_aug_y的公式如下所示:
43、sigma2=ratio×(weight_m-m_kj)2×covariancec,a
44、isda_aug_y=y+0.5×sigma2
45、其中,ratio是损失的比率参数,covariancec,a是从协方差估计器中获取的协方差矩阵,y是模型的原始输出,sigma2代表样本的伪标签的调整值,将原始输出调整为更适合目标域的形式;
46、步骤s35:最后,使用交叉熵损失函数计算伪标签和真实标签之间的损失值;该损失值将作为模型的训练目标,通过优化网络参数来最小化该损失值;损失值laug的公式如下所示:
47、laug=ce(isda_aug_y,labels)
48、其中,ce表示交叉熵损失函数,labels是样本的真实标签。
49、在一较佳的实施例中,步骤s4具体包括以下步骤:
50、步骤s41:首先基于跨域目标检测的经典框架,划分为两大阶段,即训练阶段与测试阶段;在训练阶段,基类数据被用来训练检测器,提升检测性能;随后,在进行新类微调之前,将初始化完成的检测器参数复制到学生模型中;学生模型在正式蒸馏之前,需经历一个“磨合”阶段;在此阶段中,模型针对特定数量的新类数据,利用标准的检测监督损失进行精细调整,以适应跨域小样本目标检测的需求;完成磨合后,学生模型的权重将同步至教师模型,为后续的蒸馏训练做好准备;在进行蒸馏的时候,教师模型与学生模型以协同共进的方式进行训练;
51、步骤s42:采用知识蒸馏的架构将强增强图像作为学生模型的输入,将弱增强图像作为教师模型的输入,以提供可靠的伪标签;在监督分支中,计算学生模型的监督检测损失:分类损失lcls和定位损失lloc;在新类样本的情况下,监督检测损失ls的计算公式如下所示:
52、
53、其中,表示的是图像值,表示的是标签真实值,s是指新类样本,i指的是新类样本的第i个,lcls表示的是分类损失,lloc表示的是定位损失;
54、步骤s43:教师和学生共享相同的架构,并在老化步骤后用相同的权重初始化;图像由学生和教师独立处理;教师用于为弱增强版本生成数千个框候选,并通过非最大抑制nms来消除冗余;学生模型使用强增强版本进行预测,并通过计算学生预测和伪标签之间的检测损失来获得蒸馏损失ld;ld的具体计算公式如下所示:
55、
56、其中,为蒸馏情况下的正确结果,为蒸馏情况下生成的预测结果;
57、步骤s44:采用指数移动平均ema来分离教师和学生;教师用于对测试图像进行推理和评估;值得注意的是,在推理阶段,不会对输入图像执行任何数据增强操作;
58、至此,在进行知识蒸馏之前,损失函数计算公式如下所示:
59、l=ls+ldssom+laug
60、其中,l表示的是损失函数的值,ls表示的是监督检测损失值,ldssom表示的是步骤s2中生成的跨域尺度形状优化匹配模块的损失值,laug表示的是步骤s3中生成的动态语义协方差增强模块的损失值;
61、在进行知识蒸馏计算之后,新的损失函数计算公式如下所示:
62、l=ls+ld+ldssom+laug
63、其中,ld表示的是蒸馏损失;
64、步骤s45:将训练好的教师模型在验证集上进行测试,得到最终的检测准确率,得到适应于新类数据集的训练模型。
65、与现有技术相比,本发明具有以下有益效果:
66、1、与小样本目标检测不同的是,考虑到基类和新类的领域不相交问题,在跨域目标检测的基础上引入小样本学习,能够更贴合实际应用场景。
67、2、利用知识蒸馏中的教师和学生网络,两者协同发展,能够在不同领域和较少样本的情况下达到极好的检测性能,大大提高了模型的泛化能力。
68、3、考虑了检测框和真实框之间的尺度和形状差异,从跨域的角度入手解决了不同领域的情况下的尺度形状影响检测精度的问题,设计了跨域尺度形状匹配模块。
69、4、进一步解决了跨域小样本目标检测所存在的数据稀缺性的问题,提出了一种隐式语义的数据扩充方法,称为动态语义协方差增强模块,利用语义空间对数据样本进行插值或外推,来生成新的数据样本,从而对数据进行扩充。
本文地址:https://www.jishuxx.com/zhuanli/20241118/330045.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。