一种基于多模态的驾驶员情绪检测的方法与流程
- 国知局
- 2024-11-21 11:30:56
本发明涉及多模态,尤其涉及一种基于多模态的驾驶员情绪检测的方法。
背景技术:
1、随着汽车的普及和交通拥堵的日益加剧,交通安全问题越来越受到人们的关注,而驾驶员的情绪状态是影响驾驶安全的重要因素之一。影响交通安全的情绪主要是指在驾驶过程中因为交通拥堵、违章驾驶、其他行为等引起的驾驶员愤怒、不满和焦虑等负面情绪。这种负面情绪不就影响驾驶员的身心健康,还可能导致交通事故的发生,对交通安全和社会安全造成威胁,因此,如何准确的检测驾驶员的情绪状态,对于提高交通安全具有重要意义。
2、驾驶员的情绪状态,不仅仅从面部和说话时候的语音数据中分析出来,也能从生理指标中分析出来。其中心率变异被认为是自主神经系统得一种反应,而心脏自主神经系统与人们的情绪、心理压力等因素密切相关。研究表明,情绪与心率变异之间存在着密切的关系。不同的情绪状态对心脏自律性产生不同影响,从而导致心率变异的改变。例如,愉快的情绪会增加心率变异的幅度,而焦虑和压力这会减少心率变化的程度。基于这种关系,研究者们通过分析心率变异的特征产生,可以比较准确的判断出一个人的情绪状态。
3、2019年宝马股份公司提出了一种用于识别驾驶员的安全相关的情绪状态的方法和设备,该发明设计一种用于识别在车辆中的驾驶员的安全相关的情绪状态的方法和设备,其中获取驾驶员的面部图像数据,从面部图像数据中借助图像分析来获取表示驾驶员的微表情的微表情数据,获取驾驶员的情绪状态相关的生理数据;,再次通过多模态的识别放,能够较精准地可靠地识别在车辆中的驾驶员的安全相关的情绪状态,并且可以在需要时有针对地采取安全措施。
4、在2022年广州大学提出了一种多模态驾驶员情感特征识别方法及系统,该发明设计多模态识别领域,具有为一种用于驾驶员情绪判断的多模态情感特征识别方法及系统,其核心的方法在于,通过识别模块对上述信息进行识别,其中包括对上述视觉信息及语音信息进行数据预处理,分别形成视觉识别信息和语音识别信息;将上述视觉识别信息和语音识别信息分别输入视觉人脸表情特征识别模型和语音情感特征识别模型,分别得到视觉特征向量和语音特征向量,将视觉特征向量和语音特征向量输入双模态情感特征识别模型,获得决策级融合的情感识别结果。该方法有效解决传统算法中多模态特征的代表性不足和融合算法冗长的技术问题。
5、2022年吉林大学也提出了一种多模态的驾驶员情绪智能识别方法。该发明涉及一种基于多模态网络的驾驶员情绪智能识别的方法,属于智慧交通技术领域。包括多模态情绪数据采集,数据预处理,搭建基于多模态网络的情绪识别网络模型,多模态情绪敢于,优点是提出的多模态网络模型综合多个模态信息进行识别判断,相比于单模态情绪识别,可一定程度上提高识别准确率。
6、针对当前技术的不足和存在的问题,我们提出了一种基于多模态的驾驶员情绪状态识别方法,通过使用摄像机(自带麦克风)捕获驾驶员的面部视频和音频,我们将处理分成三个部分,一个是通过视频数据分析出心率变异特征,第二个是通过面部视频数据分析面部表情特征,第三个是通过语音数据分析驾驶员的语音情绪特征。再根据以上三个特征使用多模态模型进行综合评估出驾驶员的情绪状态,这样综合利用了面部表情、语音、内在生理信息,有望提高驾驶员的情绪状态识别准确率和可靠性。
技术实现思路
1、本发明设计驾驶员在驾驶过程中的情绪状态检测,特别是利用了人工智能对驾驶员面部、语音以及生理指标(心率变异)的变化的情绪检测方法。
2、根据本发明实施例的一种基于多模态的驾驶员情绪检测的方法,包括如下步骤:
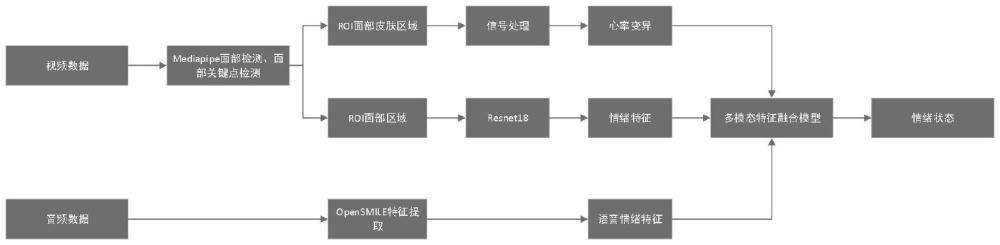
3、s1、通过摄像头和麦克风实时采集驾驶员的面部视频和语音数据;
4、s2、利用mediapipe提取面部视频中的468个面部关键点,并且计算面部皮肤区域的rgb均值,通过pos模型计算心率变异值,利用散射变换方法处理信号,提取心率变异特征,使用mediapipe进行面部检测,提取面部区域图像,将面部区域图像resize到resnet18模型所需的大小,利用resnet18模型提取面部表情特征,利用opensmile框架提取语音特征,使用config/is09-13/is09_emotion
5、.conf配置文件;
6、s3、将生理特征、面部表情特征和语音情绪特征输入多模态融合模型,多模态融合模型使用全连接层和最大池化层进行特征融合,评估驾驶员的情绪状态。
7、可选的,所述s1具体包括:
8、s11、通过摄像头采集驾驶员的面部视频数据,摄像头安装在车辆中控台上,摄像头需对准驾驶员面部;
9、s12、通过麦克风采集驾驶员的语音数据,麦克风内置于摄像头中或单独安装在车内,捕捉驾驶员说话时的语音信息;
10、s13、将摄像头采集到的视频数据和麦克风采集到的音频数据同步传输到计算平台;
11、s14、视频数据采集的帧率为20帧/秒,音频数据采集的采样率为16khz;
12、s15、所采集的视频数据和音频数据均序列形式保存。
13、可选的,所述s2具体包括:
14、s21、对获取到的视频数据,对每张实时图像使用mediapipe进行facemesh468个面部关键点提取,并且通过面部各个关键点寻找到面部皮肤区域,对每张图像的面部皮肤区域进行rgb求均值计算,可得到每张图像的皮肤均值,将该窗口内的rgb均值数据经过pos模型计算,再通过散射变换,再对信号进行重构,并寻找峰值,计算各个峰值之间的时间差的变化就是心率变异值,提取一段时间内的心率变异值作为生理特征,生理特征提取:对获取到的视频数据,对每张实时图像使用mediapipe进行facemesh提取,并且通过面部各个关键点寻找到面部皮肤区域,对每张图像的面部皮肤区域进行rgb求均值计算,得到每张图像的皮肤均值,将该窗口内的rgb均值数据经过pos模型计算,再通过散射变换,再对信号进行重构,并寻找峰值,计算各个峰值之间的时间差的变化就是心率变异值,提取一段时间内的心率变异值作为生理特征;使用库射变换,并选择morlet小波与信号进行卷积:
15、
16、其中k是归一化常数,w是频率,t是时间,morlet小波在ppg研究中已经被使用;
17、s22、面部表情特征提取:对获取到的面部视频数据,对每张实时图像使用mediapipe进行facedetect提取面部区域,并通过roi提取所需的面部区域图像,对面部区域图像进行resize处理,放缩到resnet18所需图像大小,再讲图像送入resnet18模型进行特征提取,即得到所需面部表情特征;
18、s23、语音情绪特征提取:从麦克风获取音频数据,再对音频数据送入opensmile开源特征提取框架,使用opensmile里面config/is09-13/is09_emotion.conf作为配置提取语音特征,并将此特征作为语音情绪特征。
19、可选的,所述s22具体包括:
20、s221、对获取到的面部视频数据,对每张实时图像使用mediapipe进行facedetect提取面部区域;
21、s222、通过roi提取所需的面部区域图像;
22、s223、对面部区域图像进行resize处理,将图像尺寸调整至224x224像素,使图像满足resnet18模型的输入要求;
23、s224、将处理后的面部区域图像输入resnet18模型进行特征提取,得到面部表情特征向量;
24、s225、通过特征向量计算得到面部表情特征:
25、fi=resnet18(iroi);
26、其中,fi表示第i帧图像的面部表情特征向量,iroi表示调整尺寸后的面部区域图像;
27、s226、将多帧图像的面部表情特征向量进行时间序列处理,捕捉面部表情随时间的变化:
28、f=[f1,f2,...,fn];
29、其中,f表示一个时间窗口内的面部表情特征矩阵,n为时间窗口内的帧数;
30、s227、对面部表情特征矩阵进行归一化处理,减小个体差异对特征提取的影响:
31、
32、其中,f′表示归一化后的面部表情特征矩阵,μ(fi)和σ(fi)分别表示第i帧图像特征向量的均值和标准差;
33、s228、将归一化处理后的面部表情特征矩阵输入时间卷积网络,进一步提取时序特征:
34、t=tcn(f′);
35、其中,t表示经过时间卷积网络处理后的时序特征:
36、
37、其中,tj表示时序特征的第j个通道,wjk表示时间卷积网络的卷积核,*表示卷积运算,f′k表示归一化后的面部表情特征矩阵的第k个通道,bj表示偏置项。
38、可选的,所述s23具体包括:
39、s231、从麦克风获取音频数据,并将音频数据进行预处理,包括降噪、归一化和分帧处理,预处理后的音频信号:
40、
41、其中,x(t)为归一化后的音频信号,s(t)为原始音频信号,μ(s)和σ(s)分别为音频信号的均值和标准差;
42、s232、对预处理后的音频数据进行特征提取,使用opensmile开源特征提取框架,配置文件为config/is09-13/is09_emotion.conf;
43、提取的特征包括但不限于mfcc、音调、能量和其他统计特征,mfcc特征提取:
44、
45、其中,mfcc(n)表示第n个mfcc特征,x(m)表示第m帧的音频信号,m为滤波器的数量,k为特征数量;
46、s233、将提取的多维特征向量组合形成特征矩阵:
47、faudio=[f1,f2,...,fn];
48、其中,faudio为音频特征矩阵,fi为第i帧的音频特征向量,n为总帧数;
49、s234、对音频特征矩阵进行归一化处理,减小个体差异对特征提取的影响:
50、
51、其中,f′audio表示归一化后的音频特征矩阵,μ(fi)和σ(fi)分别表示第i帧音频特征向量的均值和标准差;
52、s235、将lstm提取的时序特征输入情绪分类模型,生成语音情绪识别结果,情绪分类:
53、eaudio=softmax(we·h+be);
54、其中,eaudio表示语音情绪识别结果,we和be分别表示分类模型的权重和偏置项。
55、可选的,所述s3具体包括:
56、s31、将生理特征、面部表情特征和语音情绪特征分别进行标准化处理;
57、s32、将标准化后的生理特征、面部表情特征和语音情绪特征连接成一个综合特征向量;
58、s33、将综合特征向量输入全连接层,计算融合特征;
59、s34、将融合特征输入最大池化层,进行特征降维和聚合;
60、s35、将池化后的特征输入情绪分类模型,生成最终的情绪状态评估结果;
61、可选的,所述s32具体包括:
62、s321、将标准化后的生理特征表示为向量f′ph ysio,面部表情特征表示为向量f′face,语音情绪特征表示为向量f′audio;
63、s322、对各特征向量进行降维处理,保证它们具有相同的维度d,降维过程采用主成分分析方法:
64、f″ph ysio=pca(f′ph ysio);
65、f″face=pca(f′face);
66、f″audio=pca(f′audio);
67、其中,f″ph ysio、f″face和f″audio分别表示降维后的生理特征、面部表情特征和语音情绪特征;
68、s323、将降维后的特征向量进行拼接,形成一个综合特征向量fcombined:
69、fcombined=[f″ph ysio,f″face,f″audio];
70、其中,fcombined为拼接后的综合特征向量;
71、s3124、对综合特征向量进行归一化处理,减小不同模态特征之间的尺度差异,归一化:
72、
73、其中,f′combined为归一化后的综合特征向量,μ(fcombined)和σ(fcombined)分别表示综合特征向量的均值和标准差;
74、s325、将归一化后的综合特征向量输入到特征融合网络中,进行特征融合计算:
75、ffusion=σ(w·f′combined+b);
76、其中,ffusion为融合后的特征向量,w为特征融合网络的权重矩阵,b为偏置项,σ为激活函数。
77、可选的,所述s33具体包括:
78、s331、将归一化后的综合特征向量f′combined作为输入,定义全连接层的权重矩阵wfc和偏置向量bfc;
79、s332、通过全连接层计算初步融合特征:
80、ffc1=σ(wfc1·f′combined+bfc1);
81、其中,ffc1表示初步融合特征,wfc1为第一层全连接层的权重矩阵,bfc1为偏置向量,σ为激活函数;
82、s333、引入第二层全连接层进一步融合特征:
83、ffc2=σ(wfc2·ffc1+bfc2);
84、其中,ffc2表示进一步融合的特征,wfc2为第二层全连接层的权重矩阵,bfc2为偏置向量;
85、s334、为了增强模型的表达能力,引入残差连接:
86、fres=ffc1+ffc2;
87、其中,fres表示引入残差连接后的融合特征;
88、s335、将残差连接后的融合特征输入第三层全连接层,计算最终融合特征:
89、ffusion=σ(wfc3·fres+bfc3);
90、其中,ffusion表示最终的融合特征,wfc3为第三层全连接层的权重矩阵,bfc3为偏置向量;
91、s336、应用批量归一化和dropout技术,增强模型的泛化能力和稳定性:
92、fbn=batch norm(ftusion);
93、fdropout=dropout(fbn,p);
94、其中,fbn为批量归一化后的特征,fdropout为应用dropout后的特征,p为dropout的保留概率。
95、本发明的有益效果是:
96、本发明充分利用了人工智能技术中的深度学习和多模态数据融合方法,详细描述了基于多模态的驾驶员情绪检测算法。通过结合面部表情特征、语音情绪特征和生理特征(心率变异),有效提高了情绪状态识别的准确性和可靠性。该方法具备以下有益效果:
97、1.一种基于多模态的驾驶员情绪检测的方法安全性高一种基于多模态的驾驶员情绪检测的方法:本发明通过实时监测驾驶员的情绪状态,能够及时识别和预警潜在的情绪异常,减少因驾驶员情绪波动导致的交通事故,显著提升驾驶安全性。
98、2.一种基于多模态的驾驶员情绪检测的方法精准度高一种基于多模态的驾驶员情绪检测的方法:多模态数据融合方法综合考虑了面部表情、语音和生理信号的变化,通过多层次的特征提取和融合计算,极大地提高了情绪状态识别的精准度,相比单一模态的检测方法具有更高的可靠性和准确性。
99、3.一种基于多模态的驾驶员情绪检测的方法实时性强一种基于多模态的驾驶员情绪检测的方法:本发明利用高效的深度学习模型和优化算法,能够在驾驶过程中实时处理和分析多模态数据,确保情绪检测的及时性,为驾驶安全提供了快速响应的技术支持。
100、4.一种基于多模态的驾驶员情绪检测的方法系统鲁棒性一种基于多模态的驾驶员情绪检测的方法:通过标准化处理、特征融合和残差连接等技术手段,本发明在应对不同驾驶环境和驾驶员个体差异方面表现出较高的鲁棒性,保证了系统的稳定性和一致性。
101、5.一种基于多模态的驾驶员情绪检测的方法应用广泛一种基于多模态的驾驶员情绪检测的方法:该方法不仅适用于私人车辆,还可广泛应用于公共交通工具、商业运输和自动驾驶系统,为智能交通和智慧城市建设提供了坚实的技术支撑。
102、本发明通过多模态情绪检测技术,全面提升了驾驶员情绪状态的监测和管理能力,为构建更安全、更智能的交通系统奠定了基础。。
本文地址:https://www.jishuxx.com/zhuanli/20241120/331580.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。