一种基于改进的transformer结构的通用特征提取系统、提取方法及应用与流程
- 国知局
- 2024-11-21 11:32:44
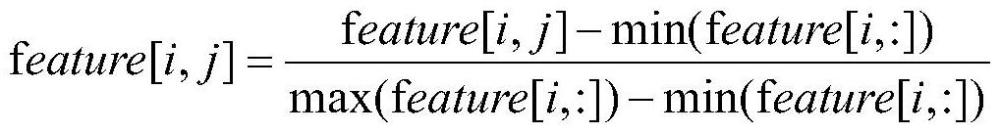
本发明属于特征提取,涉及一种基于改进的transformer结构的通用特征提取系统、提取方法及应用。
背景技术:
1、随着openai的chatgpt的横空出世,基于transformer结构的大语言模型在nlp领域被广泛得到应用。随着将业界将transformer结构应用到机器视觉(cv)领域,更是将之前不同领域模型统一到了transformer架构。
2、transformer是一种用于处理序列数据的深度学习模型,由vaswani等人在2017年提出[1]。与传统的循环神经网络(rnn)和长短期记忆网络(lstm)不同,transformer模型完全依赖于自注意力机制(self-attention mechanism)来捕捉输入数据中的长距离依赖关系。它的核心组件包括编码器(encoder)和解码器(decoder)两个部分,每个部分都由多个相同的层堆叠而成。这种架构的设计使得transformer在并行处理和长距离依赖关系建模方面具有显著优势。
3、在transformer模型中,编码器(encoder)和解码器(decoder)是两个主要组件,它们各自具有独特的结构和功能:
4、编码器(encoder):编码器的主要任务是接收输入序列,并将其转换为一组连续表示(continuous representation)。每个编码器层包含两个主要子层:多头自注意力机制(multi-head self-attention mechanism)和前馈神经网络(feed-forward neuralnetwork)。编码器层通过层归一化(layer normalization)和残差连接(residualconnection)来促进训练稳定性和信息流通。
5、解码器(decoder):解码器的任务是生成输出序列。每个解码器层也包含两个主要子层:多头自注意力机制和前馈神经网络,此外还包括一个额外的多头注意力子层,用于接收编码器的输出表示。解码器利用自回归机制(auto-regressive mechanism)逐步生成输出,并通过掩码机制(masking)确保每个位置只能访问到当前时刻之前的输出。
6、由于transformer模型不使用循环结构,无法隐式地捕捉序列的位置信息,因此需要显式地加入位置嵌入(position embedding)以表示输入数据中元素的位置。位置嵌入通过向输入序列中的每个元素添加位置信息,使得模型能够利用位置信息进行更有效的序列建模。常见的实现方法包括正弦和余弦函数以及可学习的位置嵌入参数。
7、除了位置编码,掩码(mask)在transformer模型中起到了重要的作用,主要用于以下两个方面:
8、1、自注意力掩码:在训练过程中,为了避免模型在生成某个位置的输出时访问到未来时刻的信息,使用自注意力掩码(self-attention mask)屏蔽掉未来时刻的输入。这种掩码通常称为“未来掩码”(future mask),确保模型只能访问当前时刻及之前的位置信息。
9、2、填充掩码:为了处理不同长度的输入序列,在进行批处理时需要对较短的序列进行填充(padding)。填充掩码(padding mask)用于屏蔽填充部分的数据,使得这些部分不会对模型的训练和预测产生影响。
10、综上所述,transformer模型通过其独特的架构设计、位置嵌入以及掩码机制,有效地解决了序列数据处理中的长距离依赖和并行计算问题,成为一种强大的特征提取器。
11、这些技术特点为各种自然语言处理(nlp)任务的应用提供了坚实的基础。但是由于transformer设计之初就是为了满足自然语言处理领域的处理,所以在模型结构中有很多结构是与自然语言特点紧密相关,这些结构导致transformer限制了在其他领域的应用。
12、目前的特征提取器在应对通用任务时存在的问题包括如下:
13、一、transformers更加关注邻近位置的特征的,而通用特征提取中往往特征相互关系并不是与相互位置强关联的;
14、二、传统机器学习的方法往往由于参数量限制,往往造成过拟合的现象以及泛化能力不强的问题;
15、三、卷积神经网络(cnn)模型由于卷积由于滑动窗(sliding windows)机制的影响会天然适合类似图像这一类特征在2d层面上有较强关联的问题,但是对于很多其他应用领域来讲,这种关联并不存在。
16、因此,在解决通用特征提取的相关问题时,现有的特征提取器效果相对较差。
技术实现思路
1、为了解决现有技术存在的不足,本发明的目的是提供一种基于改进的transformer结构的通用特征提取系统、提取方法及应用,使得改进后的transformer模型能够适用于更多的非自然语言领域的特征提取工作。
2、本发明提供了一种基于改进的transformer结构的通用特征提取系统,所述通用特征提取系统包括:输入及预处理模块、特征归一化模块、特征编码模块、改进的transformer模块、任务适配模块、结果输出模块;
3、所述输入及预处理模块接收输入的原始特征数据,并对原始特征数据进行预处理;所述预处理包括数据清洗、数据填充、数据转换等处理方式,使得获得的数据能够更好地适应后续模型的训练和使用;
4、所述特征归一化模块将预处理后的特征数据进行归一化处理,获得特征浮点数;
5、所述特征编码模块将归一化后的特征浮点数与预构建词表进行量化,并编码为唯一的token id;
6、所述改进的transformer模块对编码后的数据进行特征提取;
7、所述改进的transformer模块包括去除位置嵌入和自注意力掩码的注意力模块,用于对编码后的数据进行特征提取;
8、所述任务适配模块根据任务需求调整改进的transformer模块中线性层的结构;
9、所述结果输出模块输出最终的特征提取结果。
10、所述通用特征提取系统中包含预先构建的符合预定场景的词表,对transformer中的原词表进行替换;和/或,
11、预先构建的符合预定场景的所述词表存储了词表浮点数到token id的映射,将特征数据对应的特征浮点数量化为词表浮点数后,使特征浮点数与所述token id一一对应;和/或,
12、所述词表浮点数均匀和/或按照正态分布和/或动态树进行划分。
13、所述改进的transformer模块中不包含位置嵌入和自注意力掩码;
14、所述改进的transformer模块直接使用输入的不添加任何位置信息的特征向量,后续处理的特征向量不包含任何位置编码;和/或,
15、所述改进的transformer模块在多头自注意力机制中不使用任何形式的掩码,允许每个位置的特征向量与其他所有位置的特征向量自由交互,充分利用输入特征之间的全局信息。
16、所述改进的transformer模块中的线性层为任务适配层,通过改变所述线性层的维度,适配不同的任务;和/或,
17、所述任务的适配包括回归或分类任务;
18、当适配回归任务时,将所述线性层的维度从[feature_size,hidden_dim]x[hidden_dim,vocab_size]转化为[feature_size,hidden_dim]x[hidden_dim,1],其中,feature_size表示特征大小(或特征维度),hidden_dim表示隐藏层维度,vocab_size表示词表大小;
19、当适配分类任务时,将所述线性层的维度从[feature_size,hidden_dim]x[hidden_dim,vocab_size]转化为[feature_size,hidden_dim]x[hidden_dim,label_nums],其中,feature_size表示特征大小(或特征维度),hidden_dim表示隐藏层维度,label_nums表示需要分类的类别数,vocab_size表示词表大小。
20、本发明还提供了一种利用上述通用特征提取系统实现的通用特征提取方法,所述特征提取方法包括:
21、步骤一、将输入的特征数据按照每一个特征维度进行归一化处理,获得特征浮点数;
22、步骤二、将归一化后的特征浮点数量化为预构建词表中已存储的浮点数,并与token id一一对应;
23、步骤三、将步骤二中完成量化的数据输入到改进的transformer模块中;
24、步骤四、经特征提取后得到最终的特征提取结果。
25、所述步骤一前还包括对输入的原始特征数据进行预处理,包括进行数据清洗、数据填充和数据转换等处理;
26、所述数据清洗是指去除所述原始特征数据中的噪声数据和异常值;所述数据填充是指处理填充所述原始特征数据中的缺失数据;所述数据转换是指将输入的原始特征数据根据需要进行格式转换和单位统一。
27、步骤一中,将特征数据归一化为[0,1]的特征浮点数;所述归一化公式如下式所示:
28、
29、其中,feature[i,j]表示第i个特征维度的第j个样本值,min(feature[i,:])表示第i个特征维度的样本最小值,max(feature[i,:])表示第i个特征维度的样本最大值;和/或,
30、步骤二中,所述预构建词表中包含[0,1]的浮点数对应的字符串,进而能够映射为token id,将归一化的特征浮点数按照就近原则和/或先映射成正态分布数据,进而量化为预构建词表中的词表浮点数,获取token id。
31、步骤三中,所述改进的transformer模块中包含一个或多个由注意力模块和前馈网络组成的块;
32、所述注意力模块中去除位置嵌入模块和自注意力掩码模块;
33、所述改进的transformer模块中将输入数据通过嵌入层转换为高维向量表示;计算输入数据中每个位置与其他所有位置之间的注意力权重;通过两个线性变换和一个激活函数,对自注意力机制输出的特征进行非线性映射,经层归一化和残差连接后,获得经多层处理后的高维特征表示。
34、步骤三中,对transformer模块中最后的线性层的维度进行修改,适配包括回归和分类等在内的任务;
35、当适配回归任务时,将所述线性层的维度从[feature_size,hidden_dim]x[hidden_dim,vocab_size]转化为[feature_size,hidden_dim]x[hidden_dim,1],其中,feature_size表示特征大小(或特征维度),hidden_dim表示隐藏层维度,vocab_size表示词表大小;
36、当适配分类任务时,将所述线性层的维度从[feature_size,hidden_dim]x[hidden_dim,vocab_size]转化为[feature_size,hidden_dim]x[hidden_dim,label_nums],其中,feature_size表示特征大小(或特征维度),hidden_dim表示隐藏层维度,label_nums表示需要分类的类别数,vocab_size表示词表大小。
37、本发明还提供了一种实现上述通用特征提取方法的硬件系统,所述硬件系统包括:存储器和处理器;所述存储器上存储有计算机程序,当所述计算机程序被所述处理器执行时,实现上述通用特征提取方法。
38、本发明还提供了一种计算机可读存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时,实现上述通用特征提取方法。
39、本发明还提供了上述通用特征提取系统,上述通用特征提取方法,上述硬件系统或上述计算机可读存储介质在非自然语言处理领域的特征提取中的应用。
40、本发明的有益效果包括:
41、本发明方法使用类transformer结构,针对各种需要进行特征提取领域(如金融,房产,医药等等),给出一种通用的大模型解决方案,极大改变了使用传统建模方法容易过拟合,泛化能力差等缺点,同时降低了建模难度;
42、本发明通过改造transformer模型结构,去除了位置嵌入和掩码,使得模型从原理上能够适用于更多的非nlp任务;
43、本发明根据不同的使用场景,通过预构建适用于对应场景的更大的词表,对transformer中的原词表进行替换,使得归一化后的特征数据能够转化成唯一的token,保证token与特征的一一对应性;
44、本发明还通过改变transformer模块最后一层的算子维度,能够适用于不同的特征提取任务,具有广泛应用场景。
本文地址:https://www.jishuxx.com/zhuanli/20241120/331702.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。