一种故障处理方法、装置、设备及介质与流程
- 国知局
- 2024-11-21 11:36:41
本技术涉及测试,特别涉及一种故障处理方法、装置、设备及介质。
背景技术:
1、无论是x86系统还是arm平台,不同严重程度的故障处理采用了不同的实现方案,其中核心实现方案是通过智能平台管理接口(ipmi协议)将ras(reliability,availability,and serviceability)信息上报给外部的基板管理控制器(bmc,baseboardmanagement controller),其中根据不同平台的硬件差异,分别采用不同的实现方式;但是无论上述哪种实现方案都受到平台自身硬件设计的限制,同时依赖机器上的bmc芯片;而处理ras相关任务只是基板管理控制器整体工作负载的一部分,bmc还需要负责大量系统监控工作,基板管理控制器信息本身性能孱弱,无法对ras信息进行更加详细的进一步处理。
2、即当前不同平台对于ras方案的实现,依赖平台自身的硬件设计以及外部bmc芯片的实现,同时受到了外部bmc信息性能瓶颈的限制;无论是kcs、bt、smic接口还是ssif接口实现方案,都不够通用,不同硬件平台需要根据自身支持的接口类型选择支持的某种ras处理方案;例如x86平台通常采用kcs接口上报ras信息,而arm平台通常采用ssif接口上报信息,受限于上述通道性能限制和资源冲突,某些平台还会自定义实现ras处理方案,例如采用共享内存方式。
技术实现思路
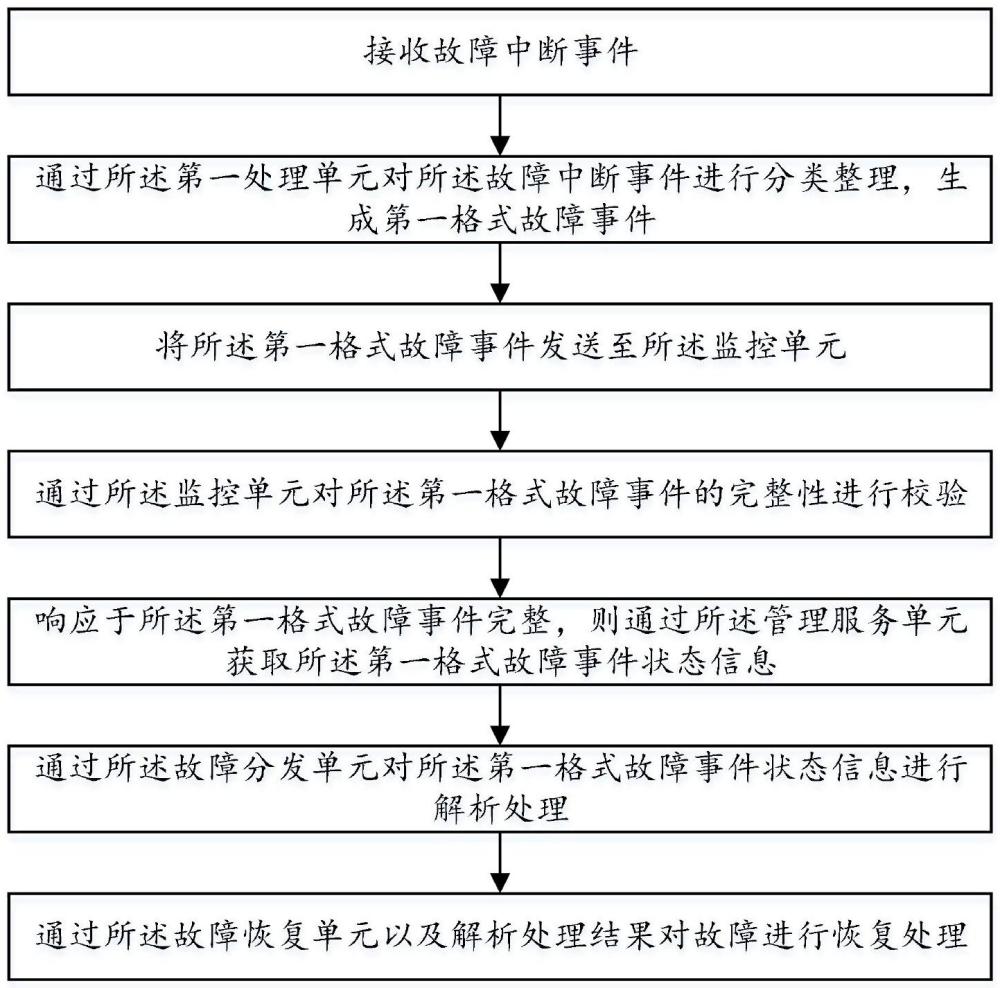
1、为了克服上述技术缺陷,本技术的目的在于提供一种故障处理方法、装置、设备及介质,所述方法包括:接收故障中断事件;通过所述第一处理单元对所述故障中断事件进行分类整理,生成第一格式故障事件;将所述第一格式故障事件发送至所述监控单元;通过所述监控单元对所述第一格式故障事件的完整性进行校验;响应于所述第一格式故障事件完整,则通过所述管理服务单元获取所述第一格式故障事件状态信息;通过所述故障分发单元对所述第一格式故障事件状态信息进行解析处理;通过所述故障恢复单元以及解析处理结果对故障进行恢复处理。本技术可以释放bmc端计算资源,大大提高了ras处理算力,减轻ras的管理成本。
2、本技术实施例提供的具体技术方案如下:
3、第一方面,本技术提供了一种故障处理方法,所述方法应用于故障处理系统,所述系统包括客户端与服务端,所述客户端的输出端与所述服务端的输入端连接,所述客户端包括第一处理单元,所述服务端包括监控单元、管理服务单元、故障分发单元以及故障恢复单元,所述方法包括:
4、接收故障中断事件;
5、通过所述第一处理单元对所述故障中断事件进行分类整理,生成第一格式故障事件;
6、将所述第一格式故障事件发送至所述监控单元;
7、通过所述监控单元对所述第一格式故障事件的完整性进行校验;
8、响应于所述第一格式故障事件完整,则通过所述管理服务单元获取所述第一格式故障事件状态信息,其中,所述第一格式故障事件状态信息包括:故障硬件配置信息和/或系统运行状态信息和/或故障地址信息;
9、通过所述故障分发单元对所述第一格式故障事件状态信息进行解析处理;
10、通过所述故障恢复单元以及解析处理结果对故障进行恢复处理。
11、在其中一个实施例中,所述服务端包括基板管理控制器控制单元以及日志单元,所述通过所述管理服务单元获取所述第一格式故障事件状态信息,包括:
12、通过所述管理服务单元获取出现故障事件的客户端设备ip地址以及mac地址;
13、通过所述管理服务单元以及客户端设备ip地址获取所述基板管理控制器的ip地址;
14、通过所述基板管理控制器的ip地址获取基板管理控制器控制单元;
15、通过所述基板管理控制器控制单元获取客户端设备的故障硬件配置信息、系统运行电源状态信息以及故障地址信息;
16、通过所述日志单元记录客户端设备的故障硬件配置信息、系统运行电源状态信息以及故障地址信息。
17、在其中一个实施例中,所述服务端还包括第二处理单元,所述通过所述故障分发单元对所述第一格式故障事件状态信息进行解析处理,包括:
18、根据所述第一格式故障事件状态信息的标头信息确定出现故障的硬件设备以及故障错误类型,其中,所述故障错误类型包括可修复错误和不可修复错误;
19、获取所述第一格式故障事件状态信息的数据段;
20、根据所述第一格式故障事件状态信息的数据段生成第二格式故障事件状态信息;
21、将所述第二格式故障事件状态信息发送至所述第二处理单元;
22、通过所述第二处理单元对所述第二格式故障事件状态信息进行判断处理。
23、在其中一个实施例中,所述服务端包括告警单元,所述通过所述第二处理单元对所述第二格式故障事件状态信息进行判断处理,包括:
24、判断所述第二格式故障事件状态信息的故障错误类型;
25、当故障错误类型是可修复错误时,则对当前可修复错误的计数值是否大于第一阈值进行判断;
26、所述对当前可修复错误的计数值是否大于第一阈值进行判断,包括:
27、判断当前可修复错误的计数值是否大于第一阈值;
28、若是,则通过所述告警单元以及故障恢复单元对故障进行恢复处理;若否,则结束流程;
29、当故障错误类型是不可修复错误时,则通过所述告警单元以及故障恢复单元对故障进行恢复处理。
30、在其中一个实施例中,所述通过所述故障恢复单元以及解析处理结果对故障进行恢复处理,包括:
31、当故障错误类型是可修复错误时,则通过所述告警单元向管理员预警,并通过所述基板管理控制器控制单元关闭出现故障的硬件设备,开启备用硬件设备资源;
32、响应于没有冗余硬件配件资源,则开启备份服务器;
33、当故障错误类型是不可修复错误时,则通过所述告警单元向管理员预警,并重启出现故障的硬件设备;
34、响应于重启设备失败,则通过备用硬件设备资源重新恢复出现故障的硬件设备;
35、响应于通过备用硬件设备资源重新恢复出现故障的硬件设备失败,则开启备份服务器。
36、在其中一个实施例中,所述接收故障中断事件之前,包括:
37、在所述客户端的第一处理单元配置网络驱动以及网络协议栈,其中,所述网络协议栈包括应用层、传输层、网络接口层、数据链路层以及物理层。
38、在其中一个实施例中,所述方法,包括:
39、获取故障事件;
40、通过自动化响应工具以及故障处理组件对故障进行恢复;
41、所述通过自动化响应工具以及故障处理组件对故障进行恢复,包括:
42、通过自动化响应工具以及故障处理组件重启服务、切换备用路径以及通知运维人员;
43、通过自动化响应工具动态调整资源,根据负载扩展故障服务实例;
44、所述通过自动化响应工具以及故障处理组件对故障进行恢复之后,包括:
45、通过应用容器引擎对故障事件服务进行容器化,在微服务架构中部署;
46、所述通过应用容器引擎对故障事件服务进行容器化,在微服务架构中部署,包括:
47、创建应用容器镜像文本文件;
48、使用应用容器命令行工具运行镜像命令;
49、通过docker run命令启动容器并进行初步测试;
50、创建标言文件,定义服务的配置信息,其中,配置信息包括容器镜像、副本数、资源限制;
51、定义服务与负载均衡配置;
52、根据应用容器引擎登录并创建命名项目;
53、上传所述应用容器镜像文本文件到仓库,在容器引擎平台导入镜像,应用服务的配置信息;
54、应用所述标言文件配置创建资源对象和服务资源;
55、在容器化环境中配置监控工具,收集服务的性能指标和日志;
56、基于所述服务的性能指标和日志设置告警提示;
57、根据就绪探针和存活探针自动重启错误的服务实例;
58、通过容器编排引擎的滚动更新特性对微服务架构进行无停机更新;
59、将持续集成、持续交付、持续部署、自动构建镜像流程及测试部署到微服务架构。
60、第二方面,本技术还提供了一种故障处理装置,所述装置包括:
61、接收模块,用于接收故障中断事件;
62、合成模块,用于通过所述第一处理单元对所述故障中断事件进行分类整理,生成第一格式故障事件;
63、发送模块,用于将所述第一格式故障事件发送至所述监控单元;
64、校验模块,用于通过所述监控单元对所述第一格式故障事件的完整性进行校验;
65、获取模块,用于响应于所述第一格式故障事件完整,则通过所述管理服务单元获取所述第一格式故障事件状态信息,其中,所述第一格式故障事件状态信息包括:故障硬件配置信息和/或系统运行状态信息和/或故障地址信息;
66、解析模块,用于通过所述故障分发单元对所述第一格式故障事件状态信息进行解析处理;
67、处理模块,用于通过所述故障恢复单元以及解析处理结果对故障进行恢复处理。
68、第三方面,还提供了一种故障处理装置,包括:
69、一个或多个处理器;
70、存储装置,用于存储一个或多个程序;
71、当所述一个或多个程序被所述一个或多个处理器执行,使得所述一个或多个处理器实现如第一方面任一所述的故障处理方法。
72、第四方面,本技术还提供了一种计算机设备,所述设备包括:
73、存储器、处理器及存储在存储器上的计算机程序,所述处理器执行所述计算机程序以实现如第一方面任一所述的故障处理方法的步骤。
74、第五方面,本技术还提供了一种计算机程序产品,包括计算机程序,该计算机程序被处理器执行时实现第一方面任一所述的故障处理方法的步骤。
75、第六方面,本技术还提供了一种计算机存储介质,所述介质包括:
76、其上存储有计算机程序,该计算机程序被处理器执行时实现第一方面任一所述的故障处理方法的步骤。
77、与现有技术相比,本技术实施例提供的技术方案所述方法包括:接收故障中断事件;通过所述第一处理单元对所述故障中断事件进行分类整理,生成第一格式故障事件;将所述第一格式故障事件发送至所述监控单元;通过所述监控单元对所述第一格式故障事件的完整性进行校验;响应于所述第一格式故障事件完整,则通过所述管理服务单元获取所述第一格式故障事件状态信息;通过所述故障分发单元对所述第一格式故障事件状态信息进行解析处理;通过所述故障恢复单元以及解析处理结果对故障进行恢复处理。本技术可以释放bmc端的计算资源,利用专用硬件提供更加强大的计算能力,支持ras功能的拓展;同时,可以将整个云服务中心的服务器进行集中管理,大大降低了现代大型云服务中心的管理成本,提高故障处理的可靠性,减轻ras管理成本。
78、本技术实施例提供的技术方案通过基于通用型网络协议栈的方式,屏蔽了硬件设计上的差异,从而实现跨平台处理;将ras功能从基板管理控制器中剥离出来,采用专用ras服务器统一处理整个云服务中心的ras事件,从而解决了bmc带来的性能瓶颈,提供完善的ras服务,释放了bmc的算力,也有利于bmc专注于其他管理功能。
79、本技术实施例提供的技术方案采用了更为通用的网络接口作为ras信息传递的物理通道,利用网络通信中的仲裁机制,可以很好的规避资源冲突问题,同时网络通道是云服中心必备接口,通用性更强。
本文地址:https://www.jishuxx.com/zhuanli/20241120/332006.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表