一种基于大语言模型的智能搜索引擎构建方法与流程
- 国知局
- 2024-11-21 11:55:37
本发明涉及搜索引擎构建方法,具体的是一种基于大语言模型的智能搜索引擎构建方法。
背景技术:
1、查询改写(query rewriting)任务是指将用户输入的原始查询转换为检索引擎/数据库更容易理解的检索语句,本发明主要考虑检索引擎的查询改写任务。现有基于大语言模型的技术方案大多为直接使用prompt调用llm生成改写后的语句,例如hyde以llm直接回答用户查询的答案内容,作为查询改写的结果输入检索引擎,能够召回更加相关的文档。few-shot prompting也是常采用的用于增强改写效果的技术,但是所使用的示例通常是固定的。为了进一步提升效果,工程上常常采用动态few-shot方案,即prompt中所使用的示例是根据与当前输入的相关性动态获取的。
2、文档重排序任务是指,对检索引擎粗召回的文档列表根据与问题的相关性进行重新排序,以提升rag框架下大语言模型作答的准确性。使用最广泛的重排器(re-ranker)是基于经过有监督微调的bert模型,然而在实际业务场景下,我们常常无法获取足够的标注语料用于训练bert重排器;此外,若直接使用在其他通用语料上训练的模型,可能无法达到令人满意的业务效果。随着大语言模型的快速发展,研究者开始尝试使用大语言模型作为zero-shot场景下的re-ranker,例如使用了大语言模型解码时产生的查询似然度(qlm,query likelihood)作为文档与问题的相关度得分,以pointwize的方式获取所有文档的相对顺序。提出了一种大语言模型+listwise prompt的方案获得文档排序,并尝试以滑动窗口的方式、结合冒泡排序获得topk最相关的有序文档。
3、在查询改写任务上,现有方案通常没有考虑过滤器的自动规划问题,因此难以实现影响因子、期刊分区等复杂改写需求,本发明提出了一种过滤器自动规划和检索语句转换框架解决该问题。此外,在few-shot prompt的使用上,现有方案仅考虑了query之间的主题内容相似性,没有考虑ner骨架的相似性,本发明提出了一种基于ner的动态few-shot提示词策略,能够召回更具有参考价值的few-shot示例。
4、在基于大语言模型的文档重排序任务上,对于pointwise排序,现有方案都只使用了单一的相关性得分,即使llm能力再强,在zero-shot场景下直接打分仍然会出现较多错误。据此,本发明提出一种多元的评分体系方案,先对各个文档进行粗划分,再进行细划分,从而能够提升文档排序的准确性。
5、对于基于llm的listwise排序任务,现有基于滑动窗口与冒泡排序的方案只能获得topk个最相关的有序文档,而无法获得所有文档的顺序;此外,当topk大于llm一次最多排序的文档数目m时,无法使用该方案。据此,本发明提出了一种基于大语言模型和快速排序算法的方案,能够以较低的成本获得所有文档的顺序;而对于只需要取topk个最相关的有序文档的场景,本文也提出了一种结合部分快速排序算法的方案,当topk>m时也能够完成排序任务。
技术实现思路
1、为解决上述背景技术中提到的不足,本发明的目的在于提供一种基于大语言模型的智能搜索引擎构建方法,针对查询改写模块和重排序模块做出优化,检索改写的准确率以及召回文档重排序的合理性均得到显著提升。
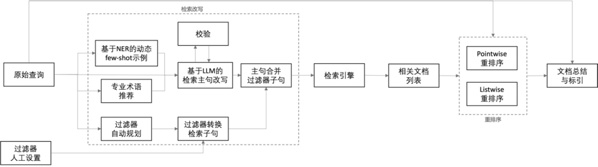
2、本发明采用的技术方案为:一种基于大语言模型的智能搜索引擎构建方法,包括以下步骤:
3、步骤1:原始查询(输入1)
4、原始查询是指用户以自然语言描述的检索语句。
5、步骤2:过滤器人工设置(输入2)
6、除了原始查询,用户还可通过设置过滤器约束召回的文档,以获取更符合需求的检索结果。
7、步骤3:检索改写
8、基于用户输入的原始查询和过滤器设置,检索改写模块负责将其转换为专业的检索语句,检索改写流程中涉及的各个模块包括:基于ner的动态few-shot示例、专业术语推荐、基于llm的检索主句改写、检索主句校验、过滤器自动规划模块、检索语句转换模块与检索主句合并过滤器子句。
9、步骤4:使用检索引擎检索相关文档
10、获取最终的检索改写语句后,将其输入检索引擎,即可获取与相关文档列表。
11、步骤5:文档重排序
12、召回相关文档后,需要对这些相关文档进行重排序,以获得顺序更合理的topk个文档。
13、步骤6:文档总结与标引
14、最后,基于用户原始查询、以及重排序后的文档列表,本发明使用大语言模型总结文档内容、回答用户问题,并在特定作答片段后标识引用来源,方便用户进行事实性校验,提升作答内容的可信度。
15、进一步的,所述步骤2中使用时间过滤器,用户可指定召回文档的发布时间范围;使用出版方过滤器,用户可限制仅返回指定出版方的文档;使用文献影响因子(impactfactor)过滤器,用户可指定召回文档的影响因子范围;使用文档类型过滤器,用户可指定召回文档的类型(正式文章、时评)等。
16、进一步的,所述步骤3中基于ner的动态few-shot示例具体为:
17、大语言模型的few-shot示例技术,是指在prompt中提供任务相关的几个示例,从而提升llm完成任务的成功率。动态few-shot(dynamic few-shot)技术,是指prompt中的示例并不是固定的,而是根据当前的输入从示例库中查询相似的例子作为示例,这样的例子更具有参考性,能够进一步提升任务执行的准确率。
18、在智能检索引擎上线期间,系统将逐渐积累真实的原始用户查询和检索改写的结果,经过人工校对后即可作为“经验”,即动态few-shot的示例库来源。然而,若直接使用原始的用户查询搜索示例库,我们能够召回主题内容相近的示例,但难以召回结构类似的示例,而后者对于检索改写任务往往更具有参考价值。
19、一种既能召回主题内容相近、又能召回结构类似示例的方案。具体的流程主要分为两个步骤:命名实体识别、混合检索;
20、命名实体识别(ner,named entity recognition):
21、用户输入的原始查询首先经过命名实体识别模块,实体类型包括表型<phenotype>、时间范围<time_range>、出版方名称<publisher_name>、人名<person_name>、药品名<drug_name>等,提取原始查询中包含的实体类型及其位置后,将实体替换为实体类型标识,即可获得原始查询语句的“ner骨架”。
22、混合检索:
23、得到原始查询的ner骨架之后,同时使用原始查询与ner骨架进行混合检索,得到主题相近或结构类似的改写示例。检索方式采用bm25+dense embedding的混合检索方式,其中bm25用于衡量字面相似度、dense embedding用于评估语义相似度。
24、上述混合检索模块所对接的示例库检索引擎,本发明采用elastic search框架构建索引,每一条记录同时包括了原始查询字符串、原始查询embedding、ner骨架字符串、ner骨架embedding。其中,embedding模型基于bert和基于infonce损失函数的对比学习训练。值得注意的是,在构建ner骨架字符串的检索索引时,需要将表示实体类型的特殊字符串片段加入到tokenizer的词表中,例如“<phenotype>”、“<time_range>”等,避免在分词时错误地将该标记切分开。
25、进一步的,所述步骤3中对于命名实体识别模块,不同的阶段本发明将采用不同的构建策略。在系统的冷启动阶段,我们采用基于大语言模型的无监督ner;在系统积累了足够的真实用户查询作为训练语料后,将切换为基于bert的有监督ner。
26、1)基于大语言模型的无监督ner:
27、当历史查询量不足时,本文采用基于大语言模型的无监督ner方案,又进一步可细分为单阶段或两阶段策略。不同大语言模型由于指令对齐能力不同,适合不同的策略,根据效果进行选择即可。
28、单阶段策略,是指通过prompt指令让大语言模型直接输出所识别的实体,prompt中包含了ner任务说明、各个实体类型的说明、以及输出格式的定义。对于输出格式,本文设计了基于xml标记的和基于json的两种输出格式。基于xml标记的输出格式,是指让大语言模型在所识别的实体两侧分别插入xml开始标记与结束标记;
29、通过解析xml标签的位置和内容,即可获取所识别的实体类型、mention以及位置。
30、通过解析json字符串,可获取实体的mention和类型;与xml输出不同的是,为了进一步获取实体的位置,还需使用正则表达式或模式匹配算法在输入语句中匹配所识别的mention,本文使用了ac自动机多模匹配算法进行mention匹配。
31、两阶段策略,是指先让大语言模型输出查询语句中包含了哪些实体类型(阶段一),对于每一实体类型,再让大语言模型在查询语句中抽取指定类型的实体(阶段二)。这样做的目的是在于将一个任务拆分为多个子任务,从而降低难度,避免了在使用单阶段策略时由于实体类型过多、所使用的大语言模型较弱导致的ner效果不佳的问题。
32、2)基于bert的有监督ner:
33、为了节省计算资源以及提升实体识别的速度和准确率,当历史查询量足够时,本文将训练一个基于bert的有监督ner模型,训练语料使用大语言模型标注与人工校验得到,标注形式采用bio(b-begin,i-inside,o-outside)序列标注,模型架构采用bert+crf层的架构。
34、进一步的,所述步骤3中专业术语推荐具体为:
35、某些检索引擎除了收录相关文档,还会使用专业术语库中的术语标记文档的关键词、主题词,用户在检索时就可直接使用专业术语进行关键词/主题词检索。
36、具体而言,输入一条原始查询,本发明没有直接使用该查询召回相关的专业术语,而是先使用大语言模型(llm)自行总结关键词列表。若llm对指定的专业术语库有所了解,还可在提示词中直接让其尝试输出相关的专业术语作为关键词列表,但llm输出的专业术语并不一定与标准库中的术语完全一致。之后,使用关键词列表作为输入,在自建的elastic search术语检索引擎中检索,召回topk的相关术语列表,注意到此时召回专业术语的书写完全正确,可作为检索主句改写模块的参考来源,辅助进行更加精准的检索改写。
37、进一步的,所述步骤3中基于llm的检索主句改写具体为:
38、在得到与原始查询相似的few-shot示例、以及推荐的专业术语列表后,本发明构建prompt使用大语言模型完成检索主句的改写任务,其中prompt中包括改写任务说明、检索引擎相关信息、改写原则、few-shot示例、所推荐的专业术语列表、用户原始查询等,获取llm的输出后进行解析,得到改写的检索主句。
39、进一步的,所述步骤3中检索主句校验具体为:
40、llm改写的检索主句,可能存在语法错误、条件限制过多等问题,将导致后续检索错误或检索结果为空,因此本发明采用了多轮的“改写-校验”机制,在获取每一轮的检索主句改写结果后,尝试用其进行检索,若检索引擎报错,则将检索引擎的报错信息作为prompt,反馈给大语言模型,要求其修改现有的改写语句。通过该策略,可提高改写语句的准确率和检索执行的成功率。
41、进一步的,所述步骤3中过滤器自动规划模块、检索语句转换模块与检索主句合并过滤器子句具体为:
42、用户查询中往往包含较难处理的检索需求,而系统所对接的检索库,可能并不直接支持通过设置检索语句的标签(field)进行检索。
43、据此,本文提出了一种过滤器自动规划和检索语句转换框架,引入过滤器工具作为主改写流程的补充,能够实现更加精准检索改写。
44、具体而言,在“过滤器自动规划”模块,为了提高并行性和改写速度,我们没有采用诸如react的“贪心”型agent,而是先总体规划所需要的过滤器列表,再通过并行确定各个过滤器的参数、调用过滤器生成相应的检索子句。
45、在“过滤器规划”模块,我们通过大语言模型和提示词工程确定所需的过滤器列表,使用的prompt中应包含任务说明、原始查询、所有过滤器的使用说明等。对于每一个被选择的过滤器,在“过滤器参数确定”模块通过大语言模型和提示词工程进一步确定过滤器的参数;之后调用过滤器生成对应的检索子句,不同的过滤器有不同的生成逻辑。
46、除了自动规划所需要的过滤器,用户也可直接在系统中直接选择过滤器并设置参数,系统也将调用过滤器为其生成检索子句。最后,将所有过滤器产生的检索子句与检索主句合并后,即可得到最终的检索语句改写结果r。
47、进一步的,所述步骤5中在智能检索引擎的冷启动阶段,即无法获得足够的标注语料的场景下,我们无法使用基于语料训练的重排序模型(re-ranker);此外,若直接使用其他语料训练好的重排序模型,由于其训练语料的所在领域、语言风格等不一定与实际应用场景一致,可能将导致业务效果不佳。
48、据此,本文提出了两种基于大语言模型的zero-shot重排序方案,希望能够利用大语言模型强大的通用能力,在没有训练数据的zero-shot的场景下也能较好地完成重排序任务,为后续有监督重排序模型的构建逐渐积累训练语料。
49、根据技术路线的不同,可分为pointwise重排序与listwise重排序。所谓pointwise重排序,是指输入query和某个文档,通过评分模型计算文档与query的相关性得分,再根据每个文档的得分高低进行文档重排序。所谓listwise重排序,是指输入query和多个文档,通过排序模型直接确定各个文档的顺序。下面我们依次对两种方案进行阐述。
50、一、基于大语言模型的pointwise重排序:
51、大语言模型在zero-shot场景下直接给出文档相关性评分,常常存在评分不准确的现象,为了减小与真实评分的偏差,本文提出了一种多元评分框架,给每个文档赋予一个得分元组/向量(tuple/vector),而不仅仅是单一得分。得分元组的长度以及考察的内容,可根据不同的业务场景灵活设置。
52、以3维元组为例,基于得分元组进行文档排序时,将依次比较r1、r2、r3,其准则为:
53、di>dj当且仅当以下任一情况出现其中di>dj表示文档i(更相关)排在文档j之前,rn(i)表示第i篇文档的rn得分(n=1,2,3)。
54、本发明设计了一种3维得分元组(r1,r2,r3),其中前2维得分通过让大语言模型回答判断题或单项选择题得出,不同的答案将映射至不同的得分,其目的为将文档初步划分为不同的等级。具体如下表所示,r1为第一层级的评分,用于评估文档内容是否具有偏见或毒性;r2为第二层级的评分,用于初步划分文档的相关性。
55、
56、多元评分体系示例
57、最后一个层级的评分为0-1之间的浮点数,表示更为精细的相关性评分,其作用是将已被划分到各个等级中(根据r1和r2)的文档做进一步排序。对于无法获取到大语言模型输出token的概率分布的场景,我们将使用黑盒评分sblack;反之,我们将使用白盒评分swhite。
58、对于黑盒评分sblack,本发明使用prompt直接让大语言模型评估query与文档之间的相关性,以自然语言的形式输出一个0-1之间的相关性得分,同时要求一步步阐述评分的理由(cot,chain of thought),阐述理由有助于得到更准确的相关性评分。
59、对于白盒评分swhite,如果能够控制大语言模型的解码过程,本文将使用查询似然得分(qlm,query likelihood)作为文档的相关性得分;否则,本文将直接使用p(true)得分作为文档的相关性得分。
60、二、基于大语言模型的listwise重排序:
61、除了使用pointwise的方式依次赋予每个文档得分,再基于得分进行排序,还可以使用listwise的方式,让大语言模型直接评估多个文档之间的相对顺序。然而,当待排序的文档数目较多时,常常无法采用一次性的输入输出完成排序,一者是因为受限于大语言模型的上下文窗口大小,二者则是一次性排序太多文档时大语言模型无法很好地判断,效果相较于仅排序少量文档时下降过多。
62、据此,本文提出了一种基于快速排序算法和大语言模型listwiseprompt的方案,在一次只能使用大语言模型排序部分文档的场景下,能够快速获得全部文档之间的相对顺序。
63、快速排序(quick sort)算法是一种基于两两比较的排序算法,采用分治策略,时间复杂度为o(nlogn),n为待排序元素的个数。本文将算法中的“两两比较”改为了“多元素批量比较”,并且当分治子数组的长度小于m时能够提前终止递归,其中m为大语言模型单次最多能够排序的元素个数。
64、此外,除了对所有召回的文档进行重排序,我们更常遇到的场景其实是,只需要从n个文档中获取最相关的topk(<n)个文档列表,且这topk个文档按照相关性由高到底排序。在这一场景下,本文通过对部分快速排序(partial quicksort)算法进行相应的调整实现。
65、llm_partial_qsort算法与llm_qsort算法的区别并不大,区别仅在于右区间的递归分治并不总是调用。
66、本发明的有益效果:
67、一、大语言模型的发展给搜索引擎领域带来了深刻的变革,通过在检索改写、文档重排序、检索结果总结等检索流程中引入大语言模型,搜索引擎的智能化程度得到极大提升,从而降低了用户书写专业检索语句的门槛、缩减了用户阅读搜索结果的时间。
68、二、在检索改写模块:
69、1.提出了一种过滤器自动规划和检索语句转换框架,作为主改写流程的补充,能够有效实现复杂场景下的高难度改写。
70、2.提出了一种基于命名实体识别的动态few-shot提示词策略,有效提升了召回示例的可参考性,从而提升检索语句改写的准确率;
71、三、在文档重排序模块,本发明提出了两种基于大语言模型的zero-shot文档重排序方案,能够有效解决冷启动阶段由于语料不足无法使用有监督模型的问题:
72、1.提出了一种基于大语言模型pointwise重排序方案,使用多元评分框架将文档相关性拆解为多层评分,使得最终的文档排序更加准确合理;
73、2.结合快速排序算法/部分快速排序算法,提出了一种基于大语言模型的listwise重排序方案,解决大语言模型无法通过listwise prompt一次性给出完整排序的问题。
本文地址:https://www.jishuxx.com/zhuanli/20241120/333436.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表