基于子类平衡对比学习的长尾行人轨迹预测方法
- 国知局
- 2024-12-06 12:13:05
本发明涉及轨迹预测领域,具体涉及一种基于子类平衡对比学习的长尾行人轨迹预测方法。
背景技术:
1、在自动驾驶领域,行人轨迹预测至关重要。当前主流的轨迹预测方法依赖公共数据集来训练预测模型,但是大多数方法对数据集中的每个样本进行平等对待,忽略了其中存在的长尾分布问题。在实际交通场景中,大多数轨迹表现为简单的运动模式,如直线匀速运动,而急转弯、掉头等复杂运动模式则较为罕见。因此,模型在简单运动模式的样本上学习较为充分,容易准确预测;然而,对于数量较少的复杂运动模式,模型则可能产生显著的预测误差,这种误差往往对自动驾驶的安全性构成威胁。
2、针对数据长尾分布(即少数类别拥有大量样本,而大多数类别只有很少的样本量)问题,常见方法包括重采样和损失重加权。重采样通过不同的采样策略来平衡数据分布,会影响模型整体性能。损失重加权方法对不同类别样本赋予不同的损失权重,以减少头部类的优势,但可能导致模型在头部样本上的性能下降。这两种方法都存在缺陷。
3、因此,如何有效缓解行人轨迹预测中的长尾分布问题具有重要意义。
技术实现思路
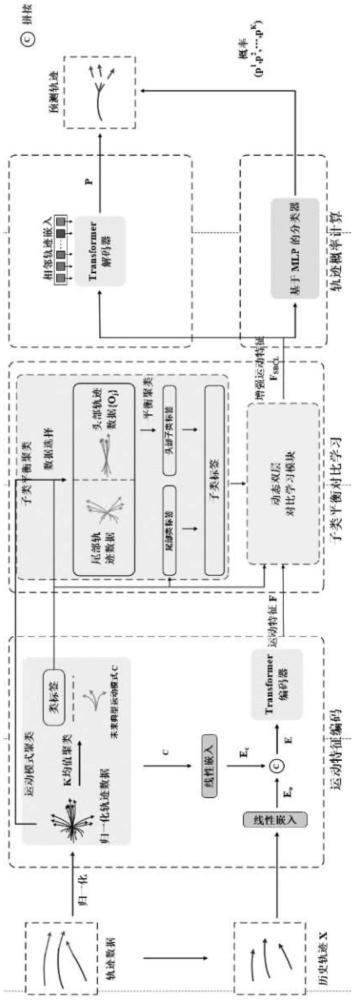
1、行人轨迹数据的长尾分布导致各个运动模式类之间的数量不平衡,即类别不平衡。类别不平衡会导致编码得到的轨迹特征空间被头部样本主导,尾部样本得不到充分建模而导致性能下降。本发明要解决的技术问题是克服现有技术的缺陷,提供一种基于子类平衡对比学习的长尾行人轨迹预测方法,它可以实现类别平衡和实例平衡,有效应对行人轨迹数据的长尾分布问题并提高在不同场景下的泛化性。
2、为了解决上述技术问题,本发明的技术方案是:一种基于子类平衡对比学习的长尾行人轨迹预测方法,方法包括:
3、构建训练数据集,所述训练数据集包括多组轨迹数据,每组轨迹数据包括历史轨迹x和未来真实轨迹y;
4、构建预测模型,所述预测模型包括运动特征编码模块、子类平衡对比学习模块、transformer解码器和分类器;
5、使用所述训练数据集训练所述预测模型,得到训练好的预测模型;
6、将当前历史轨迹输入训练好的预测模型,利用训练好的预测模型进行预测,输出未来预测轨迹;其中,
7、所述运动特征编码模块的工作过程包括:
8、对归一化后的多组轨迹数据进行k均值聚类,生成未来典型运动模式集c和类标签,c={c1,c2,...,cl},ci表示未来典型运动模式集c中第i个未来典型运动模式,l表示类别数量;
9、将历史轨迹x分别与未来典型运动模式集c中的各个未来典型运动模式嵌入拼接,并输入transformer编码器,得到运动特征f;
10、所述子类平衡学习模块的工作过程包括:
11、根据类标签从归一化后的多组轨迹数据中选择头部类轨迹数据和尾部类轨迹数据,使用平衡聚类将头部类分为样本量与尾部类样本量均值相近的多个子类,并从头部类轨迹数据中获取头部子类标签,对于尾部类轨迹数据,以其类标签作为子类标签;
12、利用动态双层对比学习模块对比轨迹数据的子类标签和类标签,对运动特征f进行对比学习,得到增强运动特征fsbcl;
13、所述transformer解码器,用于以增强运动特征fsbcl和相邻轨迹为输入,输出历史轨迹x的l条预测轨迹;
14、所述分类器用于以历史轨迹x的增强运动特征fsbcl为输入,输出l条预测轨迹的概率;
15、从l条预测轨迹中选取前k个概率最大的预测轨迹,作为未来预测轨迹。
16、进一步,将历史轨迹x分别与未来典型运动模式集c中的各个未来典型运动模式嵌入拼接;具体包括:
17、分别计算历史轨迹x的线性嵌入eo和未来典型运动模式的线性嵌入ec,对线性嵌入eo和ec进行拼接;公式为,
18、
19、其中是线性变换,|表示分隔符号;||表示拼接;wo和wc分别表示可学习参数;v表示历史轨迹x中相邻两帧之间的相对位移;vref表示未来典型运动模式中相邻两帧之间的相对位移。
20、进一步,动态双层对比学习模块的损失函数为,
21、
22、其中fi表示样本特征,di表示一个批次内与fi的同一子类的样本特征集,pi表示一个批次内与fi同一类别的样本特征集,b表示批次内的所有样本特征,|·|表示集合中的样本数,r是批量大小,γ是超参数,用于平衡两个损失项;fi和分别表示样本i及其正样本i+的运动特征;fj表示当前批次中任意样本的特征;τ1和τ2表示子类级别和类级别温度参数,类级温度参数τ2大于子类级温度参数τ1。
23、4、根据权利要求3所述的基于子类平衡对比学习的长尾行人轨迹预测方法,其特征在于,
24、根据密度调整τ1和τ2的相对大小的公式为:
25、
26、其中,fi表示类claj中的某个样本特征,claj表示类别,nc表示claj类别中的样本数,mc表示claj类别中样本特征的平均值,μ是超参数,l表示类别样本;τ1的计算公式为:
27、τ1=τmin+0.5×(τmax-τmin)×(1+cos(π(1+s)))
28、其中s表示样本对之间的余弦相似度,τmin和τmax分别表示τ1的下限和上限。
29、进一步,所述分类器为具有tanh激活函数的三层mlp。
30、进一步,分类器的损失函数为:
31、
32、其中,表示l个预测轨迹的概率,crossetropy表示交叉熵损失,y表示未来真实轨迹。
33、采用上述技术方案后,本发明通过子类平衡对比学习将头部类分为样本量与尾部类样本量均值相近的多个子类,依据子类标签进行对比学习,从而更好地区分和识别头、尾部运动模式,并实现类别平衡和实例平衡,以降低长尾问题对编码器的影响,并提高对尾部样本的建模能力,提高在各种场景下预测的准确性,有效应对行人轨迹数据的长尾分布问题并提高模型在不同场景下的泛化性。
技术特征:1.一种基于子类平衡对比学习的长尾行人轨迹预测方法,其特征在于,
2.根据权利要求1所述的基于子类平衡对比学习的长尾行人轨迹预测方法,其特征在于,
3.根据权利要求1所述的基于子类平衡对比学习的长尾行人轨迹预测方法,其特征在于,
4.根据权利要求3所述的基于子类平衡对比学习的长尾行人轨迹预测方法,其特征在于,
5.根据权利要求1所述的基于子类平衡对比学习的长尾行人轨迹预测方法,其特征在于,
6.根据权利要求5所述的基于子类平衡对比学习的长尾行人轨迹预测方法,其特征在于,
技术总结本发明涉及轨迹预测领域,具体涉及一种基于子类平衡对比学习的长尾行人轨迹预测方法。方法包括:构建训练数据集,训练数据集包括多组轨迹数据,每组轨迹数据包括历史轨迹X和未来真实轨迹Y;构建预测模型,预测模型包括运动特征编码模块、子类平衡对比学习模块、transformer编码器和分类器;子类平衡对比学习模块将头部类分为样本量与尾部类样本量均值相近的多个子类,依据子类标签进行对比学习;使用训练数据集训练预测模型,得到训练好的预测模型;将当前历史轨迹输入训练好的预测模型,利用训练好的预测模型进行预测,输出未来预测轨迹。本发明可以实现类别平衡和实例平衡,有效应对行人轨迹数据的长尾分布问题并提高在不同场景下的泛化性。技术研发人员:杨彪,房磊,严凯,倪蓉蓉,王睿受保护的技术使用者:常州大学技术研发日:技术公布日:2024/12/2本文地址:https://www.jishuxx.com/zhuanli/20241204/340018.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表