推荐理由生成方法、装置、电子设备及存储介质与流程
- 国知局
- 2024-12-06 12:25:26
本技术涉及人工智能,具体涉及一种推荐理由生成方法、装置、电子设备及存储介质。
背景技术:
1、随着互联网的发展,线上诊疗业务应运而生,核心的环节之一就是医生推荐,即如何给患者推荐合适的医生。在医疗场景,患者由于缺乏医疗方面的专业知识,往往对平台推荐的医生缺少判断力,就需要平台给出医生推荐理由,来辅助患者进行判断合理性,从而提升医、患之间的匹配度。在相关技术中,平台给出医生的推荐理由仅仅是从医生侧出发,给出医生的聚合信息,但往往忽略患者与医生匹配信息,即推荐理由与患者的主诉不相关;相关技术中采用的大模型仍是基于概率统计的方法,如果大模型在训练时未能学习到相关语料或专业知识,就可能会基于不完整的或错误的数据生成推荐理由,因此相关技术中的大模型所生成的推荐理由,往往会出现幻觉的情况,存在胡编乱造、无事实依据的问题,导致患者误判,影响问诊体验。
技术实现思路
1、为了解决上述技术问题,本技术提供了一种推荐理由生成方法、装置、电子设备及存储介质。
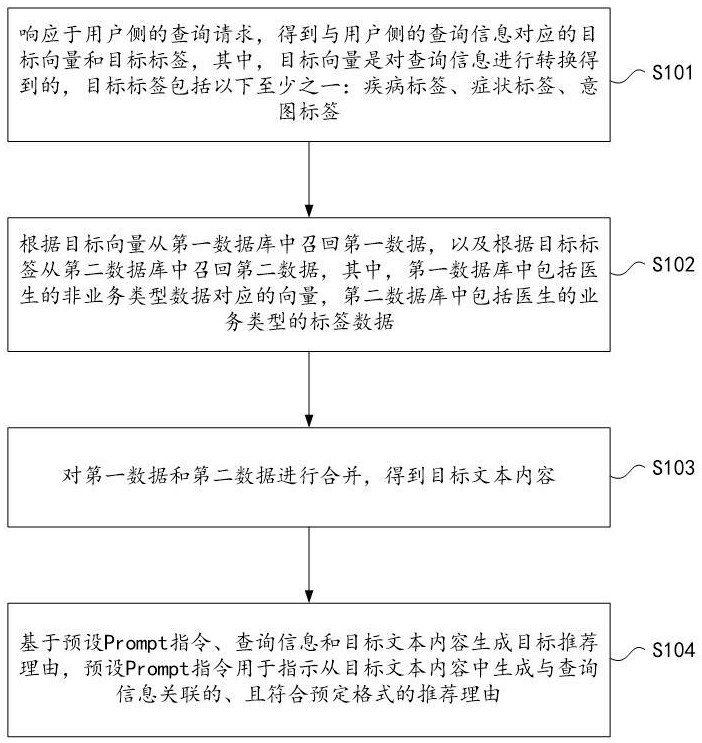
2、第一方面,本技术提供了一种推荐理由生成方法,包括:响应于用户侧的查询请求,得到与用户侧的查询信息对应的目标向量和目标标签,其中,目标向量是对查询信息进行转换得到的,目标标签包括以下至少之一:疾病标签、症状标签、意图标签;根据目标向量从第一数据库中召回第一数据,以及根据目标标签从第二数据库中召回第二数据,其中,第一数据库中包括医生的非业务类型数据对应的向量,第二数据库中包括医生的业务类型的标签数据;对第一数据和第二数据进行合并,得到目标文本内容;基于预设prompt指令、查询信息和目标文本内容生成目标推荐理由,预设prompt指令用于指示从目标文本内容中生成与查询信息关联的、且符合预定格式的推荐理由。
3、通过采用上述技术方案,目标向量和目标标签均是与查询信息相关的,保证生成的目标推荐理由与查询信息的相关性,避免了相关技术中的推荐理由与用户的主诉相关性差的问题;通过第一数据库和第二数据库分别获取第一数据和第二数据,避免了相关技术中仅对医生的几个简单维度进行拼凑导致生成的推荐理由不够全面的问题;目标文本内容是对第一数据和第二数据进行合并得到,目标推荐理由是按照预设prompt指令从目标文本内容中生成的与查询信息关联的,且生成的目标推荐理由是符合预定格式的,避免了相关技术中利用大模型预测的方法容易出现胡编乱造、无事实依据的问题。通过本技术方案,实现了提高推荐理由的相关性和准确性的目的,达到了提升用户的问诊体验的效果。相关技术中基于概率统计的大模型在生成推荐理由时,容易出现无事实依据、胡编乱造的情况,影响患者的判断,本技术方案通过从数据库中召回与查询信息紧密相关的医生数据(包括非业务类型和业务类型的数据),确保了推荐理由的准确性和事实依据;通过结合用户侧的查询信息和医生的多维度数据,生成与患者实际情况高度相关的推荐理由,有效提升了推荐理由的匹配度,帮助患者更快找到适合自己的医生,达到了提升用户的问诊体验的效果。
4、可选的,在基于预设prompt指令、查询信息和目标文本内容生成目标推荐理由之后,上述方法还包括:将目标推荐理由返回给用户侧。
5、通过采用上述技术方案,在生成目标推荐理由之后,将目标推荐理由返回给用户侧,这样用户可以及时查看医生的目标推荐理由,可以满足线上诊疗业务对于实时性的要求,提升了线上诊疗业务的用户体验和满意度。
6、可选的,在基于预设prompt指令、查询信息和目标文本内容生成目标推荐理由之后,上述方法还包括:对目标推荐理由进行预定处理,得到处理后的推荐理由,其中,预定处理包括以下至少之一:过滤处理、修正处理;将处理后的推荐理由返回给用户侧。
7、通过采用上述技术方案,在生成目标推荐理由之后,还可对目标推荐理由进行预定处理,以得到处理后的推荐理由,再将处理后的推荐理由返回给用户侧。通过对目标推荐理由进行过滤处理和修正处理,可以去除冗余信息、纠正错误表述,并根据用户的具体需求和上下文环境对推荐理由进行优化,使返回的推荐理由更加准确、全面和适用,提高了用户对推荐结果的信任度和满意度。
8、可选的,对目标推荐理由进行预定处理,得到处理后的推荐理由,包括以下之一:按照预设过滤规则对目标推荐理由进行过滤处理,得到处理后的推荐理由;按照预设优先级规则调整目标推荐理由中不同维度理由的顺序,得到处理后的推荐理由,其中,目标推荐理由包括多个维度的理由;按照预设过滤规则对目标推荐理由进行过滤处理,得到第一推荐理由,按照预设优先级规则调整第一推荐理由中不同维度理由的顺序,得到处理后的推荐理由,其中,目标推荐理由包括多个维度的理由。
9、通过采用上述技术方案,通过预设的过滤规则,可以剔除一些与用户无关、冗余或可能产生负面影响的推荐理由,确保剩余的推荐理由更加准确、相关,从而提升用户对推荐内容的接受度和信任度;根据预设的优先级规则,对多个维度的推荐理由进行排序,确保最重要的理由优先展示给用户,帮助用户快速理解推荐的核心价值,提高推荐的转化率;通过对推荐理由的优化处理,不仅可以提升单个推荐的质量,还能通过提升用户满意度和转化率,可以显著提升推荐系统的用户体验和推荐效果。
10、可选的,响应于用户侧的查询请求,得到与用户侧的查询信息对应的目标向量和目标标签,包括:响应于用户侧的查询请求,利用大模型的embedding能力生成与查询信息对应的目标向量,以及,利用大模型从查询信息中提取与病情和/或意图关联的标签,得到目标标签。
11、通过采用上述技术方案,利用平台中的大模型的embedding能力生成与查询信息对应的目标向量,即,将用户的查询信息(或称为query)转换为高维空间中的一个向量,该向量能够捕捉query的语义信息,以用于后续的召回操作;还可利用平台中的大模型从查询信息中提取与病情和/或意图关联的标签,例如,可以是疾病标签、症状标签和意图标签中的至少之一的标签。利用大模型的embedding能力,可以将用户查询中的文本信息(即查询信息)转化为高维向量表示,这种向量表示能够更准确地捕捉文本的语义和上下文信息,从而提升系统对用户查询的理解和表达能力;大模型通过预训练学习到了丰富的知识和模式,能够从用户查询信息中自动提取出与病情和/或意图紧密相关的标签,这些标签不仅准确率高,而且覆盖面广,为后续的推荐、诊断等处理提供了有力的支持。
12、可选的,在根据目标向量从第一数据库中召回第一数据,以及根据目标标签从第二数据库中召回第二数据之前,上述方法还包括:构建第一数据库和第二数据库,其中,第一数据库是按照以下方式得到的:获取医生的非结构化数据,其中,非结构化数据是通过全网搜索抓取的医生的非业务类型的数据;对非结构化数据进行切片处理,得到切片数据;将切片数据转化为向量;将向量存储至第一数据库中;第二数据库是按照以下方式得到的:获取医生的结构化数据,其中,结构化数据包括医生的历史业务数据;对结构化数据进行加工处理,得到业务类型的标签数据;将标签数据存储至第二数据库中。
13、通过采用上述技术方案,在医疗健康领域,医生的数据往往分散在多个来源,包括非结构化数据和结构化数据,这些数据在格式、结构和内容上存在较大差异,未经加工和整理的原始数据在查询和检索时效率低下,难以满足快速响应和精准匹配的需求。通过构建两个专门设计的数据库(第一数据库和第二数据库),解决了医疗健康领域数据整合与处理的复杂性、数据利用效率低下以及数据标签缺失与不准确等问题,实现了数据的精准检索和高效利用,为用户提供了更加个性化、智能化的医疗服务体验。
14、可选的,根据目标向量从第一数据库中召回第一数据,以及根据目标标签从第二数据库中召回第二数据,包括:根据目标向量和目标医生id从第一数据库中召回第一数据,其中,目标医生id是由推荐系统在响应于查询请求时所推荐的医生的id,第一数据包括与目标医生id匹配、且与目标向量的相似度大于预设相似度阈值的向量;根据目标标签和目标医生id从第二数据库中召回第二数据,其中,第二数据包括与目标医生id匹配、且与目标标签匹配的标签数据。
15、通过采用上述技术方案,第一数据库中包括多个医生id的非业务类型数据对应的向量,每个向量对应一个医生id,第二数据库中包括多个医生id的业务类型的标签数据,每个标签数据对应一个医生id;在第一数据库中查找与目标向量的相似度大于预设相似度阈值、医生id为目标医生id的向量,得到第一数据,以及在第二数据库中查找与目标标签匹配的、且医生id为目标医生id的数据,得到第二数据,即第一数据和第二数据均为目标医生id对应的数据。从第一数据库中筛选出与目标向量相似度较高的向量,从而确保召回的第一数据与用户查询高度相关;同时,基于标签的精确匹配确保了从第二数据库中召回的第二数据也是与用户查询紧密相关的;实现了从两个不同数据库中精准召回相关数据的目的,不仅提高了数据检索的精准性和效率,还实现了多源数据的有效融合和个性化推荐服务,为用户提供了更加优质、高效的医疗健康服务体验。
16、在本技术的第二方面,还提供了一种推荐理由生成装置,包括:响应模块,用于响应于用户侧的查询请求,得到与用户侧的查询信息对应的目标向量和目标标签,其中,目标向量是对查询信息进行转换得到的,目标标签包括以下至少之一:疾病标签、症状标签、意图标签;召回模块,用于根据目标向量从第一数据库中召回第一数据,以及根据目标标签从第二数据库中召回第二数据,其中,第一数据库中包括医生的非业务类型数据对应的向量,第二数据库中包括医生的业务类型的标签数据;合并模块,用于对第一数据和第二数据进行合并,得到目标文本内容;生成模块,用于基于预设prompt指令、查询信息和目标文本内容生成目标推荐理由,预设prompt指令用于指示从目标文本内容中生成与查询信息关联的、且符合预定格式的推荐理由。
17、在本技术的第三方面,还提供了一种电子设备,包括存储器和处理器,存储器上存储有计算机程序,处理器执行程序时实现上述任一项的方法步骤。
18、在本技术的第四方面,还提供了一种计算机可读存储介质,计算机可读存储介质存储有指令,当指令被执行时,执行上述任一项的方法步骤。
19、综上所述,本技术中提供的一个或多个技术方案,至少具有如下技术效果或优点:
20、1、通过从第一数据库和第二数据库中召回与查询信息紧密相关的医生数据,确保了推荐理由的准确性和事实依据;通过结合用户侧的查询信息和医生的多维度数据,生成与患者实际情况高度相关的推荐理由,有效提升了推荐理由的匹配度,帮助患者更快找到适合自己的医生,达到了提升用户的问诊体验的效果;
21、2、用户可以及时查看医生的目标推荐理由,可以满足线上诊疗业务对于实时性的要求,提升了线上诊疗业务的用户体验和满意度;
22、3、通过对目标推荐理由进行过滤处理和修正处理,可以去除冗余信息、纠正错误表述,并根据用户的具体需求和上下文环境对推荐理由进行优化,使返回的推荐理由更加准确、全面和适用;
23、4、通过构建第一数据库和第二数据库,解决了医疗健康领域数据整合与处理的复杂性、数据利用效率低下以及数据标签缺失与不准确等问题,实现了数据的精准检索和高效利用,为用户提供了更加个性化、智能化的医疗服务体验。
本文地址:https://www.jishuxx.com/zhuanli/20241204/341318.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表