一种面向软件供应链的高风险组件安全知识库构建方法
- 国知局
- 2024-12-06 12:26:52
本发明属于物联网安全,具体是一种面向软件供应链的高风险组件安全知识库构建方法。
背景技术:
1、物联网固件中蕴含的组件对设备的性能、功能及安全性起着决定性作用。鉴于物联网设备安全的重要性,对这些组件的深入研究变得尤为关键。在此背景下,有研究人员对不同软件生态系统中的第三方软件库进行了深入分析。abdalkareem等人研究了npm生态系统中轻量级库的影响(abdalkareem r, nourry o, wehaibi s. why do developers usetrivial packages? an empirical case study on npm, proceedings of the 201711th joint meeting on foundations of software engineering,2017),通过分析23万个软件包,揭示了这些库可能引发的安全漏洞和性能问题。ma等人则构建了一个基于github的框架(ma y, bogart c, amreen s. world of code: an infrastructure formining the universe of open source vcs data, ieee,2019),覆盖超过120万个git对象,为软件库的元数据和依赖关系分析提供了丰富的数据基础。decan等人从不同生态系统的依赖关系管理角度出发,指出了生态系统管理工具和策略对依赖关系的影响(decan a,mens t, constantinou e. on the evolution of technical lag in the npm packagedependency network, ieee,2018)。特别地,他们在npm生态系统中的一项研究表明,大量的依赖关系存在版本滞后现象,突显了依赖管理的重要性。针对不同软件生态系统的采集框架和分析模型,现有研究为软件库的元数据和依赖关系分析提供了技术和数据支持,然而缺乏一个“固件-组件-漏洞-补丁”全面关联的安全知识库,依赖关系管理等方面的研究也有待加强,需要进一步设计自动化工具来提升组件收集与依赖关系管理的效率,以实现物联网组件安全知识库的全面关联与高效管理。
2、根据《2023中国软件供应链安全分析报告》显示,2022年新增的开源软件漏洞数量为7682个,鉴于开源使用和安全研究的持续进行,已报告的开源漏洞数量仍会不断增加。利用现有公开漏洞库进行组件漏洞匹配是高效检测漏洞存在的重要手段,然而现有的公开漏洞库漏洞条目众多、描述复杂,不同的公开漏洞库中存在描述信息不一致、漏洞函数欠缺等问题,为此,现有研究主要从漏洞信息识别和漏洞函数收集两方面来开展工作。lv等人提出了利用nlp技术分析c语言库文档的工具advance(lv t, li r, yang y. rtfm! automaticassumption discovery and verification derivation from library document forapi misuse detection, proceedings of the 2020 acm sigsac conference oncomputer and communications security,2020),采用频繁子树挖掘并识别常用的代码描述,最后利用词法分析和语义分析进行参数的解析。nikitopoulos等人建立了一种带有提交数据的跨语言漏洞数据集(nikitopoulos g, dritsa k, louridas p. crossvul: across-language vulnerability dataset with commit data, proceedings of the29th acm joint meeting on european software engineering conference andsymposium on the foundations of software engineering,2021),每个文件存储信息包括它的原始存储库、提交标识符、文件名、关联的漏洞类型和cve标识符。bhandari等人提出了一种自动漏洞信息搜集方法,从nvd中的常见漏洞和暴露记录中自动收集和整理全面的漏洞数据集cvefixes(bhandari g, naseer a, moonen l. cvefixes: automatedcollection of vulnerabilities and their fixes from open-source software,proceedings of the 17th international conference on predictive models anddata analytics in software engineering, 2021)。cheng y等人提出了一个名为veri的漏洞检测系统(cheng y, yang s, lang z, shi z, sun l. veri: a large-scale open-source components vulnerability detection in iot firmware, computers&security,2023)。先从nvd中广泛收集漏洞描述,然后训练了一个实体-关系联合提取模型来识别漏洞的版本范围,最后将提取的信息转换为统一的版本范围,并维护一个版本-漏洞关系数据库。现有针对物联网固件中高风险组件漏洞的收集研究,大多基于官网文档中提供的漏洞信息来构建安全漏洞知识库,但仍存在文本信息语句描述模糊和漏洞信息收集不全面等问题,同时现有研究对漏洞函数的收集也不够充分。
技术实现思路
1、本发明为了能够精确地解析组件间的深层依赖关系,并有效地消除现有安全知识的模糊性,提供一种面向软件供应链的高风险组件安全知识库构建方法。
2、本发明采取以下技术方案:一种面向软件供应链的高风险组件安全知识库构建方法,包括:
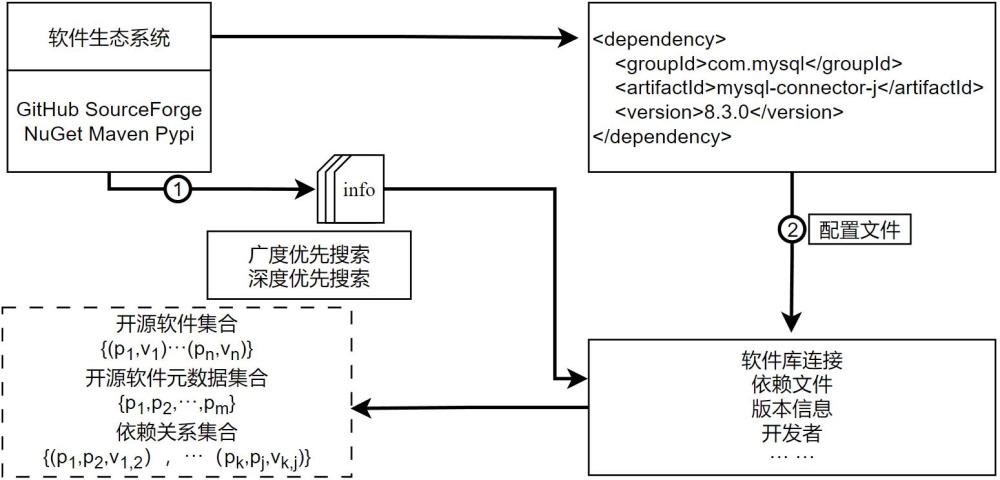
3、s100:对物联网领域中的组件信息的抓取和收集,采集二进制组件的基本信息;
4、s200:解析组件的配置文件,获得组件间的依赖关系,构建三个数据集合,分别是组件集合、元数据集合和依赖关系集合,来表示组件供应链知识库;
5、s300:使用公开漏洞数据库,结合实体-关系联合提取模型,从公开漏洞数据库描述信息中识别高风险组件名称和版本范围,得到漏洞-版本映射关系;
6、s400:从开源漏洞数据库中收集漏洞diff文件,逆向提取漏洞函数,将漏洞触发语句所在的函数作为漏洞函数添加到漏洞知识库中,建立高风险组件的漏洞-版本关系知识库;
7、s500:基于漏洞信息和代码提交信息的语义相关性,对高风险组件补丁提交范围中的提交代码进行搜索排名,从排名靠前位置确定安全补丁,并以此构建安全补丁知识库。
8、在一些实施例中,步骤s100中基本信息包括:名称、开发者、版本历史、更新日志、描述和代码仓库链接。
9、在一些实施例中,步骤s300包括:
10、s301:从公开的漏洞数据库中爬取数据,对爬取到的结果进行去重处理,得到完整的漏洞信息集,根据漏洞描述将信息分解成字符序列,并通过词嵌入技术将序列转换为词向量;
11、s302:利用结合实体-关系联合提取模型,提取出每个漏洞编号、相关的组件名称及版本范围,并以元组的形式输出信息;
12、s303:进行规范化处理,将漏洞编号、组件名称及版本范围进行统一表示。
13、在一些实施例中,步骤s302中的实体-关系联合提取模型包括:
14、bi-lstm层,输入嵌入向量到bi-lstm层,所述bi-lstm层获取前向和后向的隐状态序列;
15、自注意力层,所述自注意力层用于计算每个词的注意力权重,对bi-lstm层的输出进行加权求和,得到序列的全局表示;
16、全连接层,所述全连接层对bi-lstm和自注意力层的输出进行处理,提取出漏洞编号、组件名称及版本范围。
17、在一些实施例中,步骤s400包括:
18、s401:进行预处理,删除收集的漏洞diff文件补丁语句中的注释和空白代码,根据补丁语句的类型识别每个补丁语句的关键变量;
19、s402:解析源代码,获取程序的控制流图和数据流信息;然后识别数据依赖关系,确定每个变量的定义位置和使用位置;
20、s403:根据漏洞触发语句的特征来识别触发语句,将漏洞触发语句所在的函数作为漏洞函数添加到漏洞知识库中。
21、在一些实施例中,步骤s500包括:
22、s501:在诸多与补丁相关的语义信息中,筛选出三组不同权重的特征,提取得到三组不同权重的特征并加权转化为特征向量;
23、s502:将历史漏洞和对应的安全补丁作为训练数据,标记每个补丁的相关性得分,得分依据补丁与漏洞的匹配程度进行分配,使用lambdamart机器排序模型进行训练,训练过程优化模型参数,使得在训练数据上具有高相关性的补丁排名靠前;
24、s503:在实际应用中,输入新的漏洞信息,通过特征提取与向量化步骤得到待排序的补丁候选集合,使用训练好的lambdamart模型,对这些候选补丁进行相关性预测并生成排序列表,根据排序结果,选择排名靠前的补丁作为安全补丁,更新和构建安全补丁知识库。
25、在一些实施例中,步骤s501中,三组不同权重的特征包括:
26、漏洞特征,具体为描述漏洞的唯一标识符cve-id和描述软件特定漏洞的bug-id,以及特定指向的链接;
27、代码特征,具体为描述信息中所涉及到源码中的变量、函数、文件名、相对和绝对路径、代码修改行及位置;
28、语义特征:具体为漏洞信息和代码提交信息之间的语义相关性。
29、与现有技术相比,本发明具有以下有益效果:
30、1、本发明聚焦于如何精确地解析组件间的深层依赖关系,并有效地消除现有安全知识的模糊性,准确识别组件间的复杂依赖关系,从而自动构建一个全面的高风险组件安全知识库。
31、2、本发明针对漏洞信息描述不规范、漏洞函数欠缺等问题,利用自然语言处理方法构建漏洞与版本的映射关系,基于漏洞diff文件逆向提取漏洞函数,构建高风险组件漏洞知识库。
32、3、本发明将安全补丁的定位问题转化为源代码仓库代码提交中的筛选搜索问题,设计能够融合漏洞信息和代码提交信息的加权补丁搜索方法,构建安全补丁知识库。
33、4、本发明有效地融合来自不同软件生态系统的组件数据、公共漏洞数据库以及补丁源代码仓库,以构建一个面向软件供应链的高风险组件安全知识库。
本文地址:https://www.jishuxx.com/zhuanli/20241204/341456.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表