基于差分隐私与多元特征处理的联邦学习方法、系统和设备
- 国知局
- 2024-12-06 12:29:53
本发明涉及一种联邦学习方法、系统和设备,尤其涉及一种基于差分隐私与多元特征处理的联邦学习方法、系统和设备,属于联邦学习。
背景技术:
1、随着大数据和人工智能技术的飞速发展,数据已成为驱动创新和业务增长的关键要素。然而,在大多数情况下,数据并非集中存储于某一中心,而是分散在各个企业、机构和个人手中。这种数据分布的特性,加之行业竞争、隐私安全、行政手续复杂等问题,使得数据整合变得异常困难。为了在不泄露数据隐私的前提下,实现数据的有效利用和共享,联邦学习技术应运而生。
2、在理想状态下,通过联邦学习,多个数据拥有方可以将各自的数据贡献到一个共同模型中进行学习,以实现数据的合作与共享,同时提高数据的利用效率。但在真实世界中客户的数据往往具有不同的分布和特性,如果数据未经过预处理,模型参数的传输量以及计算量会很大,从而影响整体学习效率。此外,模型参数可能会受到恶意客户端或服务器的攻击,导致敏感信息的泄露,传统的方法是使用差分隐私这样的技术保护数据。然而,这样的保护方法忽略掉了数据本身可能存在一定的问题,如:对模型训练起反作用或不起作用。因此还需一个兼具数据有效性处理和数据安全性的联邦学习方法。
技术实现思路
1、发明目的:本发明的目的是提供一种能够提高训练过程中的安全性和效率的基于差分隐私与多元特征处理的联邦学习方法、系统和设备。
2、技术方案:本发明所述的一种基于差分隐私与多元特征处理的联邦学习方法,包括:
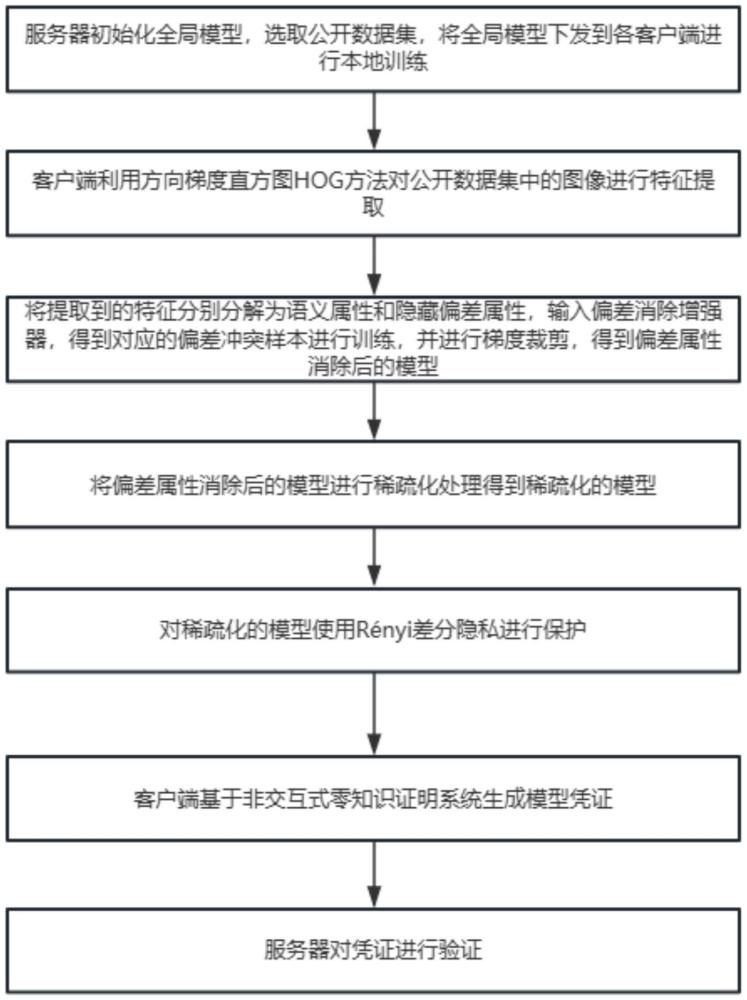
3、步骤1:服务器初始化全局模型ω0,选取公开数据集,将全局模型下发到各客户端进行本地训练;
4、步骤2:客户端利用方向梯度直方图hog方法对公开数据集中的图像进行特征提取;
5、步骤3:将提取到的特征分别分解为语义属性和隐藏偏差属性输入偏差消除增强器,得到对应的偏差冲突样本进行训练,并进行梯度裁剪,得到偏差属性消除后的模型;
6、步骤4:将偏差属性消除后的模型进行稀疏化处理得到稀疏化的模型||δω||;
7、步骤5:对稀疏化的模型||δω||使用rényi差分隐私进行保护;
8、步骤6:客户端基于非交互式零知识证明系统生成模型凭证;
9、步骤7:服务器对凭证进行验证。
10、进一步地,所述步骤1具体为服务器初始化全局模型ω0,设整数集合φ={1,1},以及签名值ρ=sign(ω0),sign()为签名函数,选取公开数据集用于训练,选取乘法循环群g,q是群g的生成元,选取s,,并将其下发到各客户端进行本地训练ωt-1为第t-1轮训练的模型,t为训练轮数,download()表示下发操作,为第i个客户端在第t轮训练的模型。
11、进一步地,所述步骤2具体包括:
12、步骤2.1:按预设的宽高比调整图像大小;通过下式,实现gamma矫正,将图像进行规范化处理,调节对比度以转化为灰度图:
13、i'(x,y)=i(x,y)γ
14、其中,表示gamma矫正,x表示像素点横坐标集合中的元素,y表示像素点纵坐标集合中的元素,i()为待调整图像,i'()为灰度图;
15、步骤2.2:使用梯度算子[-1,0,1]和[1,0,-1]计算图像横坐标方向的梯度gx和纵坐标方向的梯度gy;
16、gx(y,x)=i(y,x+1)-i(y,x-1)
17、gy(y,x)=i(y1,x)-i(y+1,x)
18、并以此计算每个像素位置的梯度方向值,像素点(x,y)处的梯度幅值g和梯度方向分别为:
19、
20、步骤2.3:构建cell级梯度方向直方图:将图像分为若干个单元格cell,采用9个bin的直方图来统计每个cell的梯度信息,将cell的梯度方向360度分为9个方向块,对cell内每个像素用梯度方向在直方图中进行加权投影,然后得到该cell的梯度方向直方图;
21、步骤2.4:将多个cell组合形成block,使用l2-norm,以block为单位进行归一化:
22、
23、其中,μ为cell的向量,λ为参数,μ'为归一化后的cell向量;
24、步骤2.5:收集所有block的hog特征,并结合成最终的特征向量。
25、进一步地,所述步骤3具体包括:
26、随机选取两个特征样本xα和xβ,xα的语义属性和偏差属性表示为和xβ的语义属性与偏差属性表示为和通过混合样本数据增强器ms得到xα和xβ的偏差冲突样本⊙表示乘积,的语义属性和偏差属性表示为和利用下式计算基于全局模型和第k个客户端本地模型各自的偏差冲突样本与原特征样本的差距:
27、
28、其中,dkl()为kl散度的分布距离函数,计算偏差消除增强器的结果ltotal=lg+lk,通过最小化lg和lk优化偏差消除增强器;在本地客户端部署偏差消除增强器:bk为本地模型偏差消除增强器,η为学习率,为ltotal的梯度;得到相应地偏差冲突样本yα,yα和yβ为另一组特征样本,然后通过交叉熵损失函数计算梯度定义裁剪界限ct,对梯度使用l2-norm裁剪进行本地模型更新
29、进一步地,所述步骤4具体包括:
30、计算模型权重与模型的差值:
31、
32、其中,fi()为泰勒公式,表示求导,w为模型参数,w0随机初始化时模型参数,定义γ为清除无意义的模型更新的损失;
33、
34、其中,δw为模型参数的更新,将模型划分为j层,为第j层的权重,为实数集,d为维度,且γs(δωj)为集合{γ(δw;ω)|w∈ωj}中第s大的值;通过掩码函数生成第j层的0-1掩码矩阵,
35、
36、将m(δω,s)表示为整体模型更新δω的掩码矩阵,通过调整s的大小,控制模型更新的稀疏度;随后进行稀疏化操作得到。
37、进一步地,所述步骤5具体为对任意的松弛项δ(0,1),定义噪声尺度参数其中f'为敏感度,ε为隐私预算,向模型添加噪声第i个客户端在第t-1轮训练的加噪后的模型,ct为第t轮的裁剪界限。
38、进一步地,所述步骤6具体为客户端选取随机数为模p的同余类集合,令u=qv,并通过加噪后的模型和签名值ρ,生成哈希值h()为哈希函数,计算凭证z=ve,随后将模型以及凭证上传至服务器。
39、进一步地,所述步骤7具体为根据客户端上传的服务器利用s计算哈希判断是否qz=qvqe,若判断成功,保留客户端模型并将其用于全局模型更新,否则丢弃,即该局部模型不参与更新,随后服务器开启下一轮训练。
40、基于相同的发明构思,本发明还提供了一种基于差分隐私与多元特征处理的联邦学习系统,包括:
41、初始化模块,用于服务器初始化全局模型ω0,选取公开数据集,将全局模型下发到各客户端进行本地训练;
42、特征提取模块,用于客户端利用方向梯度直方图hog方法对公开数据集中的图像进行特征提取;
43、偏差消除模块,用于将提取到的特征分别分解为语义属性和隐藏偏差属性输入偏差消除增强器,得到对应的偏差冲突样本进行训练,并进行梯度裁剪,得到偏差属性消除后的模型;
44、稀疏化模块,用于将偏差属性消除后的模型进行稀疏化处理得到稀疏化的模型||δω||;
45、差分隐私保护模块,用于对稀疏化的模型||δω||使用rényi差分隐私进行保护;
46、凭证生成模块,用于客户端基于非交互式零知识证明系统生成模型凭证;
47、验证模块,用于服务器对凭证进行验证。
48、基于相同的发明构思,本发明还提供了一种计算设备,包括:一个或多个处理器、一个或多个存储器以及一个或多个程序,所述程序存储在存储器中并被配置为由处理器执行,所述程序被加载至处理器时实现根据上述任一项所述的基于差分隐私与多元特征处理的联邦学习方法的步骤。
49、有益效果:与现有技术相比,本发明采用偏差消除增强器、本地更新稀疏化处理,从而优化整体计算复杂度;针对隐私数据易受攻击的问题,采用rényi差分隐私技术在模型数据中加入噪声,并通过零知识证明生成数据有效性凭证,使得服务器可以根据凭证对数据进行相应的处理;本发明在保证模型正常训练的前提下,提高了计算效率和安全性,对于现实环境应用具有重要价值。
本文地址:https://www.jishuxx.com/zhuanli/20241204/341740.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表