一种端网协同的针对分离式内存系统的数据驱逐策略
- 国知局
- 2024-12-06 12:31:23
本发明分布式系统领域,具体涉及一种端网协同的针对分离式内存系统的数据驱逐策略。
背景技术:
1、内存分解因其高内存利用率和灵活性而在数据中心越来越受欢迎。它利用高速网络技术打破了不同服务器之间内存的物理限制,使得应用程序可以利用远程服务器上的闲置内存,而不受本地内存容量的限制。目前,内存分解的主流实现方式是利用操作系统内核中的交换机制。在应用程序需要创建新数据或获取远程数据时,内核必须确保本地内存可用以分配页面来存储数据。当本地内存不足时,内核会执行数据驱逐,将使用频率较低的数据转移到远程服务器,以释放足够的内存。在发送被驱逐的数据后,主机需要等待数据流穿越网络到达远程服务器。在此过程中,应用程序将被阻塞,直到主机收到来自远端的ack回执。这种等待过程会显著延长应用程序的完成时间。
2、为了减轻应用程序因阻塞而造成的性能损失,infiniswap采用了守护进程定期驱逐数据,以防止数据驱逐直接在访问上发生,从而提高应用程序的访问吞吐量,另外,fastswap建议将驱逐过程异步卸载到专用的cpu内核上。aifm为驱逐线程分配更高的优先级,确保数据驱逐任务能够更及时地得到处理。kona通过使用新颖的硬件原语,最大限度地减少需要回写的数据量,降低了驱逐的开销。另一方面,dilos试图通过清理器和回收器的急切驱逐,以始终保持一定数量的空闲页面。当驱逐率低于内存增长率时,hermit会自适应地增加驱逐cpu的数量,以此来提高驱逐效率,就是以一定的cpu资源换取效率的提升。在这些研究中,人们考虑的仅有一个计算节点与单个内存节点相连的配置,而忽略了实际数据中心环境中应用内存分解节点部署的复杂性和规模,这样的规模会给网络基础设施带来相当大的压力,使得被驱逐数据流的网络拥塞成为影响应用性能的关键瓶颈,因此,目前的数据驱逐策略是不够的,要想有效地驱逐数据,就必须进行全面的协同设计,将主机和网络整合在一起。
技术实现思路
1、本发明的目的设计一个端网协同的数据驱逐器,能够根据内存使用情况自适应地调整数据驱逐的时机,并优先调度正处于阻塞状态的应用的驱逐数据流,从而降低应用的完成时间。
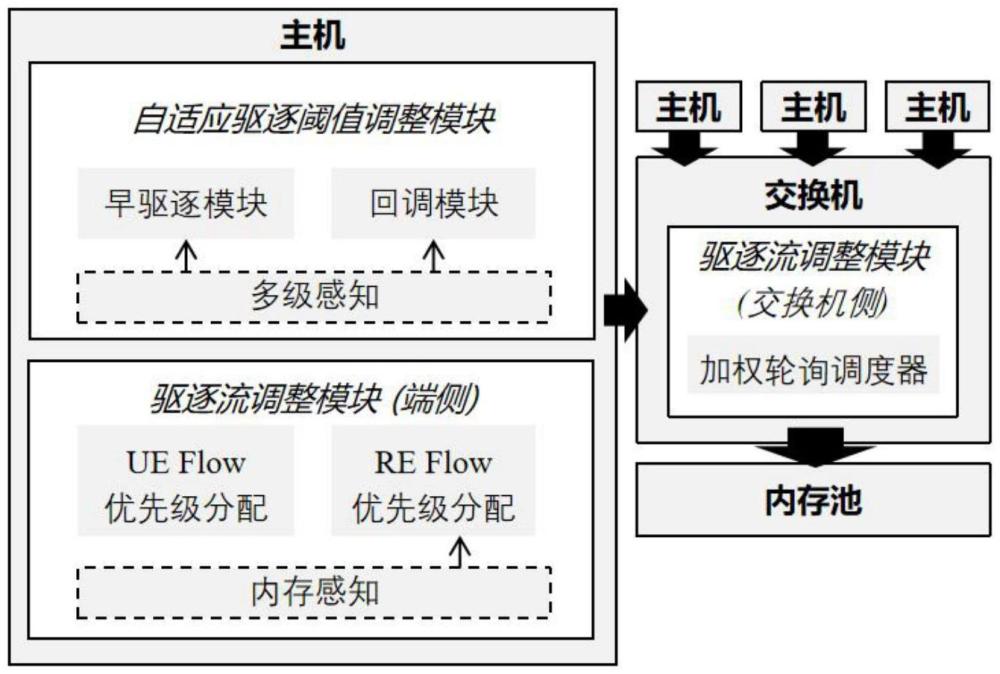
2、本发明的目的可以通过以下技术方案实现:一种端网协同的针对分离式内存系统的数据驱逐策略,包括自适应驱逐阈值调整模块a-etam和驱逐流调度模块efsm;
3、所述自适应驱逐阈值调整模块a-etam用于预测潜在的内存耗尽并执行早期数据驱逐来提前释放可用内存,减少应用程序阻塞的发生次数,所述驱逐流调度模块efsm用于提高受阻和易受阻应用程序的驱逐效率,增强应用程序整体吞吐量。
4、优选的,所述自适应驱逐阈值调整模块a-etam包括;
5、早驱逐模块:早驱逐模块建立在应用程序阻塞的根本原因之上,源于内存增长率超过了驱逐cpu的驱逐率,通过公式vevict/vapp=α得到监测感知参数α,其中vapp为内存增长率,vevict为驱逐率,根据监测感知参数α预测未来是否会发生阻塞,并作为为早期驱逐的驱逐阈值tupper;
6、回调模块:过低的驱逐阈值会导致激进的数据驱逐,降低内存利用率,将缓存未命中率cmcurrent定义为一个周期内非本地数据访问量nmiss与总访问量naccess之比,作为内存利用率的间接指标,通过公式cmlast/cmcurrent=β得到利用率感知参数β,其中cmlast表示上周期的缓存未命中率,cmcurrent表示本周期的缓存未命中率。
7、优选的,所述内存增长率vapp计算如下:
8、计算内存增长率vapp需要获得在特定时间段和经过的时间内的内存使用量的变化,在linux内核中,内存管理模块的try_charge()函数用于处理内存cgroup相关的内存分配和计费,早驱逐模块记录调用try_charge()函数的n个周期内内存使用量的变化和所用时间,以计算当前的内存增长率vapp。
9、优选的,所述驱逐率vevict计算如下;
10、在大规模场景下,由于网络拥塞的影响,驱逐率变得不稳定,早驱逐模块使用一个计数器,每次驱逐数据时递增,类似地使用n次try_charge()调用作为计算周期,对于基于页面的系统,被驱逐数据的粒度是固定的(通常是4kb),这使得计算一个周期中被驱逐数据的总量很容易,通过除以所经过的时间,就可以计算出驱逐率。
11、优选的,所述驱逐流调度模块efsm包括驱逐流优先级分配和交换机调度:
12、根据应用程序的状态将驱逐流分为两种类型:常规驱逐流ref和紧急驱逐流uef;
13、优选的,驱逐流优先级分配具体为:在驱逐流调度模块efsm中,最高优先级被分配给紧急驱逐流uef,因为uef的流完成时间的增加通过延长应用程序阻塞的持续时间直接影响应用程序性能,最终导致应用程序吞吐量的下降。考虑常规驱逐流ref,本地内存的可用性确保了在内存耗尽之前,常规驱逐流ref的延长的流完成时间仅会导致剩余内存的持续占用,而不会影响应用程序的吞吐量。因此,常规驱逐流ref将被赋予较低的优先级。然而,对于那些目前正在产生常规驱逐流ref,同时在可用内存较少或内存快速增长的情况下运行的应用,虽然它们目前没有被阻塞,但有可能被阻塞的趋势,因此,这些常规驱逐流ref的紧迫性更高,相反,对于本地内存相对充足的应用,特别是那些因a-etsm降低阈值而产生常规驱逐流ref流,但本地内存仍然充足的应用,其常规驱逐流ref的紧迫性会较低,因此,我们对常规驱逐流ref进行了细粒度的优先级区分,以便为容易受阻的应用提供更好的支持。
14、交换机调度具体为:启用加权轮循wrr调度算法,以有效缓解低优先级ref处于饥饿状态(即持续未调度)的问题,从而保护这些应用的性能,wrr作为一种标准流量调度方案,已在mellanox商业交换机(如dells4048-on)中得到广泛应用。
15、优选的,所述常规驱逐流ref由当前内存使用量超过驱逐阈值但仍低于最大内存容量的应用程序生成,紧急驱逐流uef由剩余内存接近最大容量且无法再容纳所需数据的应用程序生成。
16、优选的,驱逐流优先级中:引入了剩余内存耗尽时间texhausted这一指标,它被定义为剩余可用内存mremaining与内存增长率vapp之比,表示根据当前的内存消耗速度,估计剩余本地内存完全耗尽所需的时间,texhausted的值越小,表示常规驱逐流ref的优先级越高。
17、本发明的有益效果如下:
18、(1)本发明通过让应用增长速率快的应用提前执行数据驱逐a-etam模块,来缓解甚至消除未来可能产生的应用阻塞,其次,通过在网络中优先调度正处于或可能即将处于阻塞状态的应用所产生的驱逐流efsm模块,来降低单次应用阻塞的时间,这两种方式共同地降低应用阻塞带来的损害;
19、(2)本发明实现了在主机端,数据驱逐策略glitter基于多层次感知设计了驱逐阈值调整机制,使系统能够根据不同应用程序的内存增长率和利用率以及不同的网络条件,自适应地控制数据驱逐的时机以以优化吞吐量,在网络方面,数据驱逐策略glitter提出了于内存感知方法的新型流量调度策略,以缓解交换机上驱逐流之间的不公平竞争,从而减少受阻应用的等待时间并加速其完成。
本文地址:https://www.jishuxx.com/zhuanli/20241204/341896.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表