基于多模态学习的关系集群数据库优化方法与流程
- 国知局
- 2024-12-06 12:59:43
本发明涉及数据处理,特别涉及基于多模态学习的关系集群数据库优化方法。
背景技术:
1、随着信息技术的快速发展,数据库技术在现代信息管理系统中发挥着至关重要的作用。特别是在大数据、人工智能和多模态学习技术的推动下,数据的复杂性和多样性显著增加,传统的数据库优化方法在处理这些复杂数据时逐渐显露出局限性。多模态数据通常来源于不同的传感器、平台或信息源,其特征具有多样性、高维性和异构性。这使得现有的关系型数据库在面对这些复杂的数据集群时,面临着巨大的技术挑战。
2、目前,主流的数据库查询优化技术主要依赖于传统的索引方法,如b树、哈希索引等。这些方法在处理单一模态或低维数据时效果较好,但在处理高维、多模态数据时往往表现不佳。特别是在多模态学习背景下,不同模态的数据之间存在复杂的关联,传统索引无法有效处理这些关系,导致查询性能大幅下降。此外,随着数据量的增加,查询时间呈现指数增长,进一步限制了数据库的应用场景。一种常见的现有技术是基于b树或r树等索引结构的查询优化方法。这些方法在低维空间中表现较为优异,能够快速执行区间查询、点查询以及范围查询等操作。然而,b树或r树等结构在高维空间中会遇到所谓的“维度诅咒”问题,即随着维度的增加,索引结构的效率迅速下降。这是因为高维数据点之间的距离差异逐渐变小,导致查询性能和准确性严重受限。此外,在多模态学习场景下,不同模态的数据点特征往往分布在不同的特征空间中,使用单一索引结构难以充分捕捉数据点之间的复杂关系。
技术实现思路
1、本发明的目的是提供基于多模态学习的关系集群数据库优化方法,提高了数据分析的准确性和深度,还显著提升了数据库的查询效率和系统性能。该方法在保证数据结构和特征信息完整性的同时,降低了计算复杂度,为多模态学习中的关系集群数据库优化提供了有效的解决方案。
2、为解决上述技术问题,本发明提供基于多模态学习的关系集群数据库优化方法,所述方法包括:
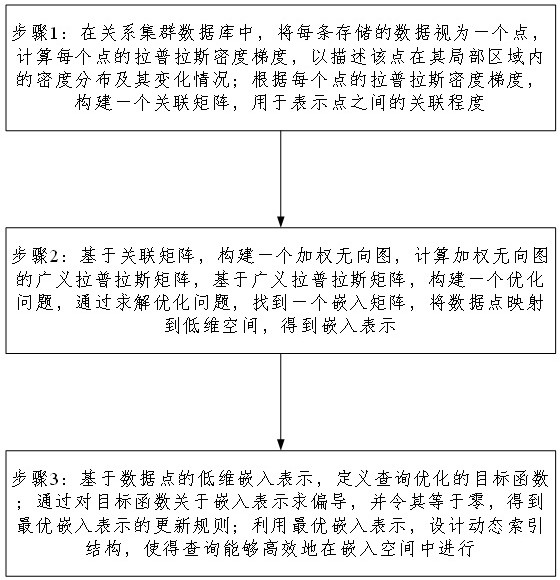
3、步骤1:在关系集群数据库中,将每条存储的数据视为一个数据点,计算每个数据点的拉普拉斯密度梯度,以描述该数据点在其局部区域内的密度分布及其变化情况;根据每个数据点的拉普拉斯密度梯度,构建一个关联矩阵,用于表示数据点之间的关联程度;
4、步骤2:基于关联矩阵,构建一个加权无向图,计算加权无向图的广义拉普拉斯矩阵,基于广义拉普拉斯矩阵,构建一个优化问题,通过求解优化问题,找到一个嵌入矩阵,将数据点映射到低维空间,得到嵌入表示;
5、步骤3:基于数据点的低维嵌入表示,定义查询优化的目标函数;通过对目标函数关于嵌入表示求偏导,并令其等于零,得到最优嵌入表示的更新规则;利用最优嵌入表示,设计动态索引结构,使得查询能够高效地在嵌入空间中进行。
6、进一步的,步骤1具体包括:确定每个数据点的邻域范围,从而确定数据点的邻域内数据点;计算每个数据点的局部密度梯度;对于每个数据点,通过高斯核函数对邻域内数据点的距离进行加权求和,得到该邻域内数据点对的影响;结合局部密度梯度和邻域贡献,计算该数据点的拉普拉斯密度梯度;局部密度梯度反映了数据点相对于其周围邻域的密度变化,如果,说明的密度高于其邻域,是聚类中心,如果,说明的密度较低,处于稀疏区域;根据每个数据点的拉普拉斯密度梯度,构建一个关联矩阵,用于表示数据点之间的关联程度。
7、进一步的,拉普拉斯密度梯度的计算公式如下:
8、;
9、其中,是对数据点的邻域密度进行求和,表示数据点的邻域,邻域范围由决定,表示半径为的区域内的所有数据点构成了邻域集合;表示数据点与邻域数据点之间的距离,这个距离用于衡量与了的相对位置,反映了了对的影响程度;是一个高斯核函数,用于将距离转换为一个权重,距离越小,权重越大,说明对的影响越大,是尺度参数,控制了邻域内的平滑程度;是密度调节参数,用于控制邻域内数据点对的影响强度,越大的值表示邻域内的数据点对的影响越大,而越小的则表示邻域的数据点对的影响越小。
10、进一步的,关联矩阵的第行,第列的元素定义为:
11、;
12、其中,为数据点和数据点之间的关联权重,数值越大表示关联越强;和分别为数据点和数据点的拉普拉斯密度梯度;为一阶l1范数,为二阶l1范数;为预设的放大参数,控制密度梯度方向相似性对关联权重的影响程度;为和之间的欧氏距离;为预设的梯度变化率平滑参数,控制密度梯度变化率差异对关联权重的影响程度;和分别为数据点和数据点的拉普拉斯密度梯度的梯度。
13、进一步的,步骤2中,基于关联矩阵,构建一个加权无向图,节数据点集包含所有数据对应的数据点;为数据点的总数;边集根据关联矩阵确定,边的权重为,表示数据点和之间的关联强度;加权无向图的度矩阵是一个对角矩阵,其元素定义为:
14、;
15、表示节数据点的度,即与其相连的边的权重之和;定义广义拉普拉斯矩阵为:
16、;
17、其中,为标准的图拉普拉斯矩阵;为拉普拉斯矩阵的平方,捕获二阶邻域信息;为预设的第一正则化参数;为度矩阵的逆平方根。
18、进一步的,步骤2中计算数据点的低维嵌入表示的过程具体包括:构建一个优化问题,其目标函数为:
19、;
20、该目标函数旨在找到一个嵌入矩阵,既能保留局部结构,又能与原始特征保持一致;为数据点的低维嵌入矩阵,是嵌入维度;将关系集群数据库视为一个矩阵,通过特征提取,得到关系集群数据库的原始特征矩阵,是原始特征的维度;为矩阵的迹运算,即对角元素之和;为一阶f范数;为预设的第二正则化参数,控制嵌入结果与原始特征的偏离程度;为单位矩阵;约束条件为:
21、;
22、保证嵌入后的数据在新的空间中正交,防止出现退化的嵌入结果。
23、进一步的,步骤2中,为了求解优化问题,构建拉格朗日函数为:
24、;
25、其中,是拉格朗日乘子矩阵;对求导并设导数为零:
26、;
27、通过如下公式化简求解:
28、;
29、其中,由于,得到;通过上述方程,求解以下广义特征值问题:
30、;
31、求解此方程,得到嵌入矩阵,其中每个元素是数据点的低维嵌入表示。
32、进一步的,步骤3中基于数据点的低维嵌入表示,定义查询优化的目标函数为:
33、;
34、其中,表示查询工作负载中涉及的数据点对集合;为数据点对的查询权重,反映了它们在查询中出现的频率;为预设的第三正则化参数。
35、进一步的,步骤3中,对目标函数关于求偏导,并令其等于零,得到;以此得到查询优化的目标函数的第一项的偏导数为:
36、;
37、其中,为查询相关的拉普拉斯矩阵,定义为:
38、;
39、其中,与和一样,均为下标索引;查询优化的目标函数的第二项的偏导数为;第三项的偏导数为;将查询优化的目标函数的第一项、第二项和第三项的偏导数相加得到以下方程:
40、;
41、化简方程后得到:
42、;
43、求解最优嵌入表示为:
44、。
45、进一步的,步骤3中,利用最优嵌入表示,设计一个动态索引结构的过程包括:由于嵌入空间是低维的,使用k-d树、球树或lsh作为索引结构;将嵌入表示中的每个数据点插入到索引结构中;当数据库中的数据发生变化时,相应地更新嵌入表示和索引结构。
46、本发明的基于多模态学习的关系集群数据库优化方法,具有以下有益效果:
47、本发明通过将高维数据嵌入到低维空间中,显著降低了数据的维度复杂性。多模态数据往往来自于不同的模态或信息源,每个模态的数据点可能具有不同的特征维度,直接处理这些高维数据会导致“维度诅咒”问题,即维度增加导致索引和查询的效率大幅下降。通过优化步骤,将数据点从高维空间映射到低维嵌入空间,在保留数据点结构和特征信息的同时,有效减小了维度,显著提高了数据库查询的速度和效率。低维嵌入不仅减少了数据处理的计算复杂度,还为后续的查询优化奠定了基础,使得系统能够以更高效的方式进行数据检索。
48、其次,本发明在嵌入空间中设计了一种动态索引结构,进一步提升了查询的响应速度和灵活性。传统的索引结构如b树、r树和lsh在处理高维数据时表现出较差的性能,尤其在面对多模态数据时难以有效处理数据点之间的复杂关系。通过采用k-d树、球树或局部敏感哈希(lsh)等适合低维空间的索引结构,本发明能够高效组织嵌入后的数据点,并支持快速的最近邻查询或相似度查询。动态索引结构的一个显著优势在于,它能够随数据库中的数据变化进行快速更新。随着数据库中数据的插入、删除或更新,嵌入表示和索引结构能够自动调整,从而保证查询结果的准确性和及时性。这种动态索引机制使得数据库能够适应数据的实时变化,提升了系统的灵活性和鲁棒性。
49、第三,本发明通过将查询工作负载中的数据点对关系融入到优化目标函数中,提升了查询的准确性和相关性。在实际的数据库应用中,某些数据点对在查询中频繁出现或具有较高的关联性。传统的索引结构通常无法动态识别和处理这些高频数据点对,从而在查询过程中忽略了数据点之间的重要关系。
本文地址:https://www.jishuxx.com/zhuanli/20241204/343111.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表