一种预测分子性质的双通道对比模型
- 国知局
- 2024-07-12 10:26:48
本发明属于新型的分子性质预测,具体涉及一种预测分子性质的双通道对比模型。
背景技术:
1、随着生物技术和数据分析方法的不断进步,深度学习技术在计算机视觉和自然语言处理等领域已经取得了显著成就,这些进展激发了化学研究者们探索其在药物发现领域中的应用潜力,在药物发现领域,分子性质的准确预测是关键环节,它对分子的评估、选择和设计至关重要,深度学习技术通过提升预测准确性,有望实现更经济、更高效的药物研发。
2、计算机视觉和自然语言处理通常使用单一数据格式,而化学数据则呈现出多模态的特性,更全面地反映了分子的复杂性和多样性,在视觉和语言处理中,数据通常以一种特定的格式呈现,例如,图像是通过像素网格中的rgb值来定义的,而文本是通过序列中的单词或符号来定义的,相较之下,分子有多种表示形式,包括smiles序列、inchi编码、2d和3d结构,smiles(简化分子输入线性系统)和inchi(国际化学标识符)通过字符序列来描述分子中的原子、化学键和它们的连接方式,例如,水(h2o)的smiles表示为”o”或”[h]o[h]”,在二维结构表示中,分子被表示为平面图,原子和化学键分别作为节点和边,而三维结构通过提供原子在空间中的坐标,以及键角和二面角的信息,来展示分子的空间排列方式,序列和2d结构是最常用的分子表示方法,这些表示方法不仅易于获取和标准化,且计算效率高,除此之外,它们还能提供足够的信息以理解分子的化学性质,尽管如此,当前的大多数研究主要集中在基于序列或二维结构的单一神经网络模型上,很少有模型能够融合这两种表达形式的优势,尽管分子的序列和2d结构提供了丰富的信息,但单独使用任一种表示形式都不足以全面揭示分子的复杂特征,而且,分子的不同部分,无论是整体结构还是特定的子结构,都可能发挥关键作用,因此,为了更深入地理解分子的性质,需要一种方法,能够同时考虑分子的整体结构和其组成部分的细节;
3、基于上述问题,开发了一种新型的深度学习模型(bicl模型),旨在综合利用分子的序列、2d结构信息,以及整图和子图之间的关系,该模型使用了一个创新的双通道对比学习架构,它融合了分子的多模态特性,并进行了多层次分析,以深化对分子结构和功能的理解,这种综合性的方法不仅提高了预测的准确性,还为药物发现和化学研究开辟了新的视野,本发明的源代码可通过以下链接访问:https://github.com/cuidi1/bicl,本发明的主要贡献总结如下:
4、(1)本发明重点考察了整图与子图信息融合在分子性质预测中的重要性;
5、(2)提出的双通道对比学习模型(bicl)旨在融合整图与子图信息,及多模态数据(如序列和二维结构)的特征;
6、(3)在分子属性预测任务上评估了此模型,结果表明,此方法(bicl)与基准相比取得了更优越的性能。
技术实现思路
1、本发明提出了一种预测分子性质的双通道对比学习模型,旨在捕捉多维度信息,并且特别注重于局部信息的综合考虑,通过一系列广泛的实验验证,此模型在性能上显著超越了现有最先进的技术,计划探索结合生成式自监督学习和对比式自监督学习的方法,将其作为分子属性预测领域的一种双通道自监督任务,进一步提升预测精度和模型的泛化能力,这种方法的结合有望在捕捉复杂分子特性方面展现更高的效率和准确性。
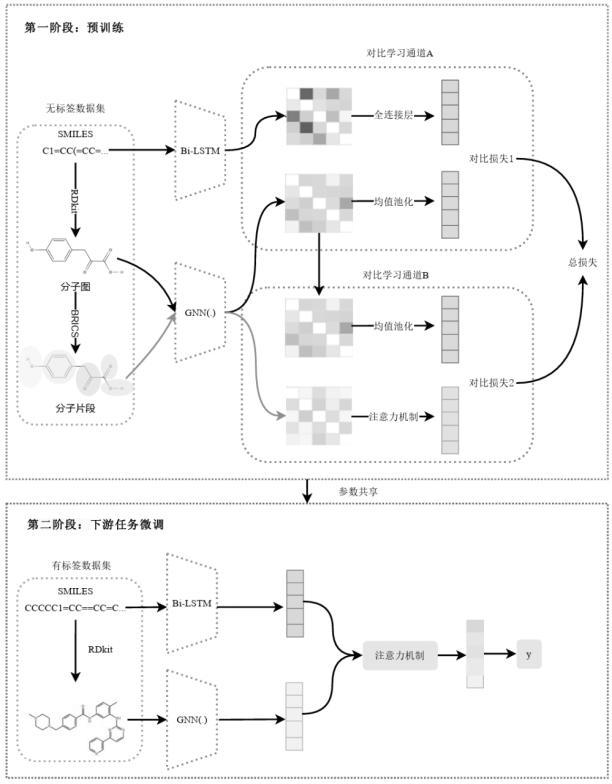
2、为实现上述技术目的,达到上述技术效果,本发明是通过以下技术方案实现:一种预测分子性质的双通道对比模型,该模型接受smiles序列、子图和整图作为输入,它通过分析这些输入数据来提取关键特征,从而预测分子的属性标签,核心思想是同时从smiles序列、分子图以及分子的子图和整图中学习特征,并将这些特征综合起来,以获得更全面的分子信息,模型采用双通道架构来有效地预测分子性质,第一个通道聚焦于综合smiles序列和分子图的特征,而第二个通道专注于理解子图与整图的关系,两个通道:
3、(1)smiles和分子图通道:以smiles序列和分子图作为输入,通过对比学习,评估smiles表示和分子图表示之间的差异;
4、(2)子图和整图通道:利用brics算法,将分子图分解成多个子图,以子图和整图作为输入,来学习它们的特征,使用注意力模块来强调子图中的关键特征,并赋予重要子图更大的权重,通过对比学习子图和整图表示,加强模型对于分子结构差异性的学习。
5、进一步地,上述新颖的分子性质预测模型中,为每个分子创建正样本对(同一分子的smiles序列和图表示)和负样本对(smiles序列和不同分子的图表示),使用之前的bi-lstm提取smiles序列特征s,使用另一个神经网络gnn提取分子图特征g,使用一个函数f(·)来计算特征向量之间的相似度得分,f(·)是基于两个向量的点积<g,s>的指数函数,对于每个正样本对(g,s),计算它们的相似度得分f(g,s),对于每个分子的smiles序列表示s,计算它与所有其他分子图表示g(j)的相似度得分,并求和,得到∑jf(g(j),s),同理,对于每个分子图表示g,计算它与所有其他分子的smiles序列s(j)的相似度得分,并求和,得到∑jf(g,s(j)),所以,通过这种方法可以得到所有负样本对的相似度得分,最后,结合所有正样本对和负样本对的相似度得分来计算损失,使得最小化正样本(g,s)之间的距离,并且最大化负样本(g,s′)之间的距离。
6、进一步地,上述分子性质预测模型中,本发明的目标是在不同的分子表示形式中学习特征,确保这些特征既具有一致性又有区分性,为了达到这个目的,本发明采用了infonce损失的一个变体,该损失函数通过最大化相同分子的smiles序列和分子图表示之间的相似性,同时最小化不同分子表示之间的相似性,从而有效地促进了模型在多模态数据上的自监督学习,具体来说,这个损失函数的形式如下:
7、
8、进一步地,上述分子性质预测模型中,本发明引入了一种创新的对比学习方法来改善分子的表征,不同于传统方法,这种方法通过分析分子子图来构建有效的正样本对,利用图神经网络(gnn)编码器,提取了两种视图下的节点嵌入:第一视图基于分子子图的平均节点嵌入,而第二视图则采用简单的平均池化,通过子图级自注意力机制,模型能够理解不同子结构间的联系。
9、进一步地,上述新颖的分子性质预测模型中,对比学习的目标函数来确保这两种视图嵌入之间的一致性,并使其能够与其他分子的嵌入区分开来,在框架中,使用brics算法将分子分解成多个子图,为了理解这些子图在整体分子结构中的重要性,模型采用了注意力机制,这种机制通过为每个子图学习并赋予一个权重,能够量化其相对重要性,基于这些权重,能够构建出一个加权的分子表示,更准确地捕捉分子的结构特征。
10、进一步地,上述新颖的分子性质预测模型中,使用brics算法将分子分解后,每个子图m表示为对于每个子图m,通过自注意力机制计算一个权重αm,这个权重反映了该子图相对于整个分子的重要性,权重计算公式为:
11、
12、
13、进一步地,上述新颖的分子预测模型中,其中score()是一个基于学习的打分函数,v、w和b是该函数的参数,结合这些权重,构建整个分子的加权表示:
14、
15、这里,整个分子的综合表示hg通过计算子图表示与其对应的注意力权重am的加权和来获得,对比学习的目标是将基于子图的分子嵌入与基于原子的分子嵌入进行对齐,这种方法旨在加强分子结构表示的一致性,确保分子的不同层次表示(即子图层次和原子层次)能够相互协调,对于每个分子gi,得到两种类型的嵌入:基于子图的嵌入和基于原子的嵌入将基于子图的嵌入作为锚点,对应的基于原子的嵌入视为正样本,同一批次中其他分子的嵌入(无论是基于子图还是基于原子)被视为负样本,使用信息噪声对比估计(infonce)作为目标函数,可以表示为:
16、
17、其中,是计算基于子图的嵌入与基于原子的嵌入之间相似度的函数,τ是一个温度参数,控制softmax函数的平滑度,b是批次中的样本数量,通过最大化基于子图嵌入与其对应的基于原子嵌入之间的相似度,并最小化与其他分子的嵌入之间的相似度,模型能够学习区分不同分子的细微特征。在预训练阶段,模型的损失函数是两个通道对比损失的总和,具体表示为:
18、l=λ1lcons1+λ2lcons2#(6)
19、其中,λ1和λ2是两部分损失的权重系数,用于平衡两种对比学习在总损失中的贡献。
20、进一步地,上述新颖的分子性质预测模型中,在为了处理和分析化学分子,网络通过软注意力机制结合smiles序列特征和二维图特征来生成一个综合特征,这么做的主要目的是从这两种模态中提取和融合关键特征,以便进行有效的分子分析,首先,模型从smiles序列和分子的二维图中分别提取特征,设smiles序列的特征为fsmiles,二维图的特征为fgraph,接着为这两种特征计算一个注意力得分,smiles序列特征的得分记为asmiles,二维图特征的得分记为agraph,这些得分反映了每种特征对预测任务的相对重要性,将得分进行标准化,使得模型可以根据得分的大小,为smiles序列特征和二维图特征分配不同的权重,最后,根据它们的权重将这两种特征进行加权求和,生成一个综合特征,这个融合特征结合了smiles序列和二维图的信息,公式可以表示为:
21、
22、
23、
24、
25、ffused=asmiles×fsmiles+αgraph×fgraph#(11)
26、在这里,v∈rd是可学习的向量,tanh(·)是双曲正切激活函数,w∈rd×d表示参数矩阵,b是偏置项,αsmiles和αgraph是标准化后的权重,ffused是最终的“序列-二维图”融合特征,其通过考虑smiles序列和二维图特征的重要性,并对它们进行加权结合而得到,标签损失llabel是根据多个预测任务t中正确预测标签的负对数似然来定义的,本文考虑m个不同的预测任务,那么每个任务t对应的标签损失可以通过交叉熵损失来计算,其公式如下所示:
27、
28、具体来说,m代表考虑的所有分子的总数,t代表每个分子具有性质的总数,wt和bt分别是与任务t相关的可学习参数,分别代表权重和偏置,是模型为分子m学习到的表示,这个表示是对应于任务t的。
29、本发明的有益效果是:
30、(1)本发明重点考察了整图与子图信息融合在分子性质预测中的重要性;
31、(2)提出的双通道对比学习模型(bicl)旨在融合整图与子图信息,及多模态数据(如序列和二维结构)的特征;
32、(3)在分子属性预测任务上评估了此模型,结果表明,此方法(bicl)与基准相比取得了更优越的性能。
33、当然,实施本发明的任一产品并不一定需要同时达到以上的所有优点。
本文地址:https://www.jishuxx.com/zhuanli/20240614/86974.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表