面向兵棋推演的智能决策方法、装置及存储介质与流程
- 国知局
- 2024-07-11 16:24:35
本发明涉及多智能体强化学习和兵棋推演,特别是涉及一种面向兵棋推演的多智能体强化学习智能决策方法、装置及存储介质。
背景技术:
1、多智能体智能决策问题是多智能体系统领域的核心研究内容。兵棋推演作为多智能体智能决策问题的重要实例,在多智能体系统领域的研究中受到广泛关注。对于此类多智能体博弈问题,其具有大规模的离散决策空间和灵活多变的环境态势,如何让强化学习算法有效应对这些挑战从而应用于此类问题是一个重要的研究课题。
2、近年来,许多基于集中式训练分布式执行框架的多智能体强化学习的算法试图解决多智能体博弈问题,如基于联合动作值函数分解(qmix)的一系列值函数逼近算法。然而在兵棋推演的环境中,由于兵棋推演场景面临的如下挑战,所以各个智能体动作的协同关系很难直接通过值函数分解表示,直接基于所有动作的联合值函数分解的集中式训练算法效率较差;其中,兵棋推演场景面临的挑战包括:
3、大规模状态空间:兵棋推演场景一般包含近5000个六边网格,双方玩家各自有6个算子。每个算子与地图中的夺控点状态信息是不断变化的,大致估计,每个算子的状态空间为50006×2·36×2+2=1.1677e51,状态空间以及算子的观测空间都是高维的;
4、复杂的动作空间:一般的兵棋推演场景包括11种动作:空动作(null)、移动(move)、隐蔽(hide)、占领(occupy)、射击(shoot)、引导射击(guide-shoot)、间瞄射击(indirect-shoot)、上车(get-on)、下车(get-off)、解除压制(decompress)以及停止正在进行的动作(stop);一些动作有很多参数且参数大小可变,整个动作空间过于庞大;
5、长线决策:一般情况下,兵棋推演场景的每一局游戏持续至少1600个决策步骤,且许多非射击类动作促成的情景可能在动作执行很久以后才出现,因此长时间序列和动作延迟为强化学习模型的训练提供难度。
技术实现思路
1、本发明的实施例提供了一种面向兵棋推演的多智能体强化学习智能决策方法、装置及存储介质,以解决在针对具有高维状态空间、观测空间和动作空间的兵棋推演场景下直接基于所有动作的联合值函数分解的集中式训练算法效率较差的技术问题。
2、为了实现上述目的,一方面,提供了一种面向兵棋推演的多智能体强化学习智能决策方法,包括:
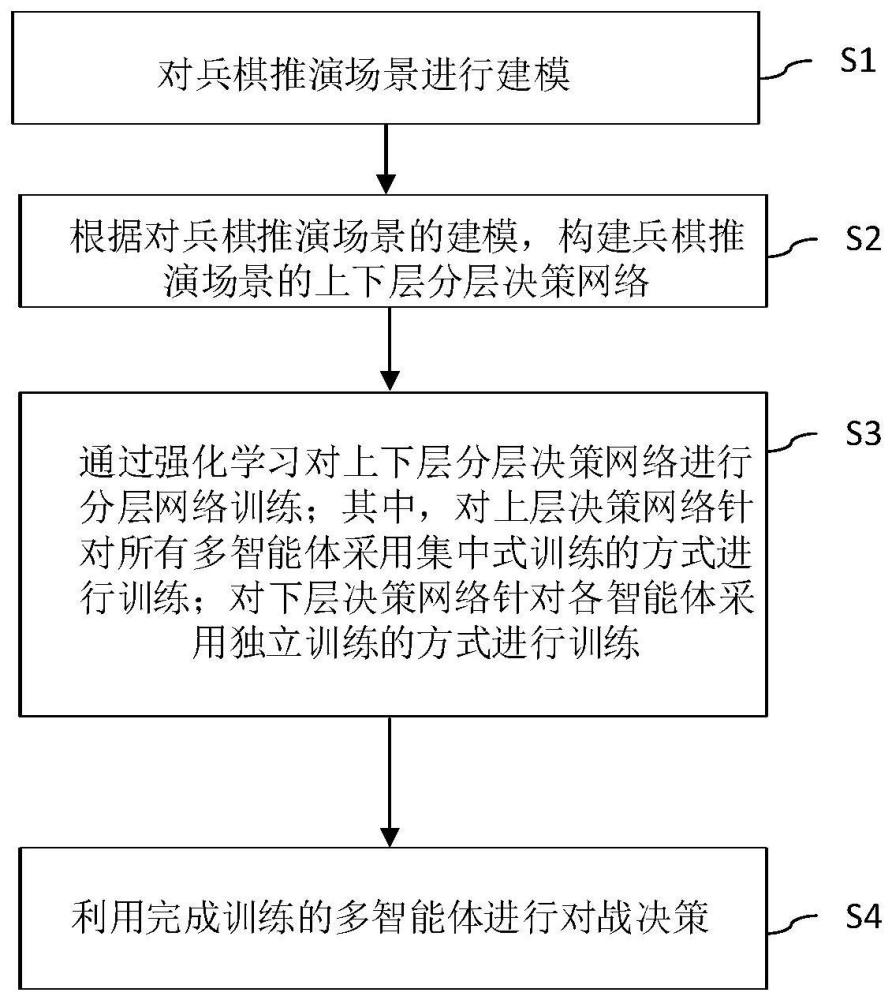
3、步骤s1,对兵棋推演场景进行建模,包括对兵棋推演场景的智能体集合进行定义及对状态空间、观测空间和动作空间进行建模;
4、步骤s2,根据对兵棋推演场景的建模,构建兵棋推演场景的上下层分层决策网络,其中,将上下层分层决策分别视为马尔可夫决策过程,上下层分层决策网络的决策结果一起用于形成环境所需的复合操作;其中,上层决策网络用于从任务集中为智能体选择可用的任务;下层决策网络用于根据上层决策网络选择的任务来选择智能体要执行的动作;
5、步骤s3,通过强化学习对上下层分层决策网络进行分层网络训练;其中,对上层决策网络针对所有多智能体采用集中式训练的方式进行训练;对下层决策网络针对各智能体采用独立训练的方式进行训练;
6、步骤s4,利用完成训练的多智能体进行对战决策。
7、优选地,所述的多智能体强化学习智能决策方法,步骤s1中对动作空间进行建模包括:
8、基于任务和行为上下两层的分层动作对兵棋推演场景中的动作进行重定义;其中,上层动作为任务,任务包括:基于六角格的任务和基于敌方算子的任务;下层动作为行为,行为是离散动作,示出了智能体当前时刻的移动方向,包括:代表周围六角格的六个方向和停止。
9、优选地,所述的多智能体强化学习智能决策方法,基于六角格的任务包括:智能体在候选六角格集合中选中一个格子,然后执行与所选中的格子相关的任务;其中,与所选中格子相关的任务包括:在所选择的格子处上车、下车、夺控或隐蔽;基于敌方算子的任务包括:移动到与敌方算子间的距离在预定距离范围内的格子,进行停止、射击或隐蔽。
10、优选地,所述的多智能体强化学习智能决策方法,其中,通过与环境交互来构建上下层分层决策网络,其中:
11、在环境输出当前时刻t的全局系统状态st后,控制方从st中获取其可见的原始观测信息,并对原始观测信息进行结构化提取后将每个智能体的观测信息和可选任务集合传给每个智能体的上层决策网络;然后,上层决策网络再将每个智能体的观测信息与每个智能体的上层决策网络所选择的任务一起传给下层决策网络;最后根据智能体的上层决策网络所选择的任务以及下层决策网络所选择的行为得到相应智能体的最终动作;控制方将其所有智能体的联合动作一起传回环境,以由环境根据双方动作推进并给出下一时刻t+1的全局系统状态st+1,并将当前步控制方的联合回报rt传回上下层分层决策网络。
12、优选地,所述的多智能体强化学习智能决策方法,其中,上下层分层决策网络通过rnn网络实现。
13、优选地,所述的多智能体强化学习智能决策方法,其中,步骤s3中,对上层决策网络采用值分解方式进行训练。
14、优选地,所述的多智能体强化学习智能决策方法,其中,对上层决策网络采用值分解方式进行训练时,使用如下第一损失函数:
15、
16、其中,第一损失函数根据上层经验池缓冲b1∑中的样本对上层决策网络进行更新,每个样本b1∑的内容为<s,o,g,rσ,s′,o′,g′>,其中o={o1,o2,…,on}为所有智能体当前时刻的观测向量,o′为所有智能体下一时刻的观测向量,n为智能体的个数,g={g1,g2,…,gn}为所有智能体当前时刻的上层联合动作,g′为所有智能体下一时刻的上层联合动作,s为当前时刻全局系统状态,s′为下一时刻的全局系统状态,r∑为联合回报,g为所有智能体当前时刻的联合可选任务集,g′为所有智能体下一时刻的联合可选任务集,第一损失函数中的θ为上层联合值函数的估计网络需训练的参数,第一损失函数中的为用于更新估计网络的对应目标网络的参数;γ为折扣因子;其中,采用贝尔曼更新方式更新上层决策网络。
17、优选地,所述的多智能体强化学习智能决策方法,步骤s3中,使用深度q网络对下层决策网络进行训练;其中,对下层决策网络进行训练采用如下第二损失函数:
18、
19、其中,第二损失函数根据下层经验池缓冲b2l中的样本对网络做更新,其中每个样本b2l的内容为<o,g,d,rl,o′>,其中,样本b2l中的o为单个智能体当前时刻的观测信息,o′为单个智能体下一时刻的观测信息,g为对应的单个智能体上层决策网络选择的当前时刻要求完成的任务,g′为对应的单个智能体上层决策网络下一时刻要求完成的任务,d代表下层决策对应的当前时刻的动作,d′代表下层决策对应的下一时刻的动作,rl为对对应的单个智能体的下层回报,其中,rl中增加了对上层决策网络任务完成度的评估,根据上传决策网络任务的完成度的不同,给予不同的权重奖励;第二损失函数中的θ是估计网络的参数,第二损失函数中的是目标网络的参数;γ为折扣因子。
20、另一方面,提供了一种面向兵棋推演的多智能体强化学习智能决策的装置,包括存储器和处理器,存储器存储有至少一段程序,至少一段程序由处理器执行以实现如上文任一所述的方法。
21、又一方面,提供了一种计算机可读存储介质,存储介质中存储有至少一段程序,至少一段程序由处理器执行以实现如上文任一所述的方法。
22、上述技术方案具有如下技术效果:
23、本发明实施例的技术方案提出了一种基于任务-行为的强化学习分层训练方法(task-behavior hierarchical reinforcement learning,tbhrl),通过对上层策略采用基于联合动作值分解的集中式训练,对下层采用结合专家知识的独立训练,针对兵棋推演这种大规模决策空间场景,可以选择性地对状态特征进行提取,并显式地将整体决策划分成任务和行为两层决策;使用本发明实施例的方案,对于某一场景下的决策,网络框架首先决策应该执行何种任务,而后决策在该场景下执行某任务需要的具体行为动作;上下层的决策各自皆看成一个markov决策过程;从而,针对兵棋推演这类具有高维状态空间、观测空间和动作空间的复杂训练场景,本发明实施例的技术方案提高了整体训练的效率,可以实现特定兵棋推演想定下的有效决策。
本文地址:https://www.jishuxx.com/zhuanli/20240615/79157.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表