结合命名实体识别与差分隐私的病历敏感信息保护方法
- 国知局
- 2024-07-11 17:38:02
本发明涉及结合命名实体识别与差分隐私的病历敏感信息保护方法,属于自然语言处理及隐私保护。
背景技术:
1、随着智慧医疗的发展,电子病历(electronic health record,ehr)已经取代了传统的纸质病历成为主要医疗数据记录和方式。电子病历含了患者的个人身体健康信息、病历历史、诊断、处方等隐私的医疗数据。由于这些数据的敏感性,保护电子病历的隐私成为一项重要的任务。然而,传统的电子病历管理系统存在隐私泄露的风险。例如,未经授权的访问、非法的数据共享和数据泄露等问题都可能导致患者的隐私信息遭到侵犯。
技术实现思路
1、本发明所要解决的技术问题是克服现有技术的缺陷,提供结合命名实体识别与差分隐私的病历敏感信息保护方法,可以在一定程度上保护隐私,同时保持数据的可用性和准确性。
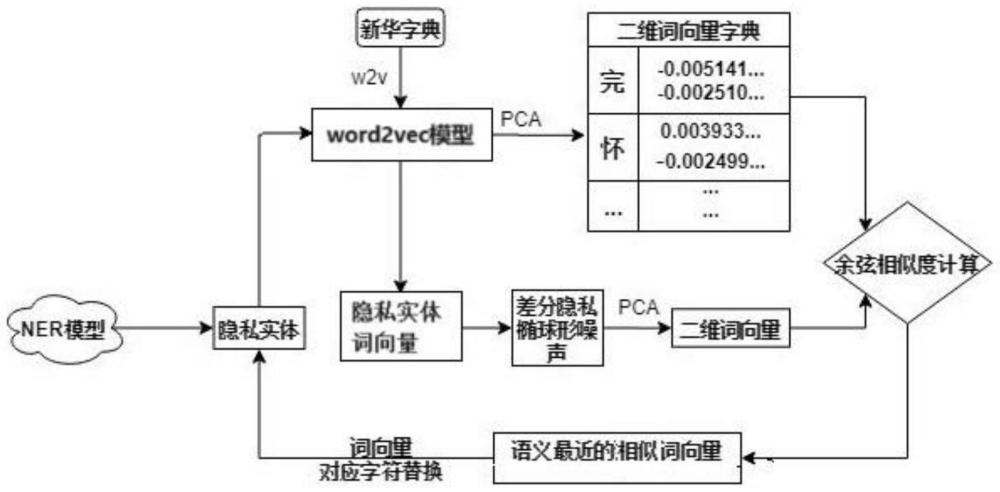
2、优先地,本发明提供结合命名实体识别与差分隐私的病历敏感信息保护方法,包括:
3、利用构建的基于bert-bilstm-bigru-crf的命名实体识别模型对预先获取的中文电子病历语料库进行识别与提取,获得隐私实体;
4、将新华字典数据集嵌入为词向量;
5、利用主成分分析方法压缩词向量为二维词向量字典;
6、利用预先训练获得的word2vec模型将隐私实体转化为隐私实体词向量;
7、利用差分隐私高斯机制对隐私实体词向量进行椭球形噪声处理并压缩至二维,获得二维词向量;
8、计算加噪后的二维词向量与词向量字典的余弦相似度,得到与其语义最近的相似词向量;
9、利用相似词向量对应的字符对中文电子病历的敏感信息进行替换。
10、优先地,预先训练获得word2vec模型,包括:
11、预先获取新华字典常用字数据集,新华字典常用字数据集包含单字、字义和拼音;
12、对新华字典常用字数据集进行提取单字,获得新华字典数据集;
13、利用新华字典数据集训练word2vec模型。
14、优先地,基于bert-bilstm-bigru-crf的命名实体识别模型包括依次连接的bert模型、双向lstm层、双向gru层和条件随机场crf。
15、优先地,word2vec模型包括输入层i、隐藏层h和输出层o。
16、优先地,输入层i与隐藏层h之间的权值设为m×n的矩阵m-n,矩阵m-n中每行表示n维向量,隐藏层h表示为:
17、
18、其中,mmni表示新华字典数据集在矩阵m-n中第i个特征词mni。
19、优先地,将新华字典数据集嵌入为词向量,包括:
20、计算得到概率为pc,k:
21、
22、其中,mnc,k为在矩阵m-n中第c个向量的第k个特征词,mnk为在矩阵m-n中所有向量的第k个特征词,exp()为指数函数,hc,k为第c个向量的第k个单元的线性和,输出层o中有c个n维向量,c为常数;
23、基于已知的隐藏层h和输出层o的共享权值(m-n)′,计算得到特征词mnk的输出向量
24、
25、计算获得新华字典数据集的输入序列的词向量r(di):
26、r(di)=∑t word2vec(t),t∈di,
27、其中,di={mn1,mn2,…,mni}表示新华字典数据集的输入序列,word2vec(t)为新华字典数据集的输入序列的第t个词向量。
28、优先地,利用差分隐私高斯机制对隐私实体词向量进行椭球形噪声处理并压缩至二维,获得二维词向量,包括:
29、隐私实体词向量为x={x1,x2,…,xn},其中xi表示第i个字符的词向量;
30、根据隐私实体词向量x的特征构建协方差矩阵σ,其中σ是n×n的对称正定矩阵;
31、生成服从多元高斯分布的随机向量z={z1,z2,…,zn},其中zi表示第i个维度上的随机变量;
32、利用下式将随机向量z转换为椭球形噪声向量e={e1,e2,…,en}:
33、
34、其中,ε表示差分隐私参数,s表示隐私实体词向量x的敏感度;
35、将椭球形噪声向量e加到隐私实体词向量x上,得到差分隐私保护后的词向量序列y={y1,y2,…,yn},其中,yi=xi+ei;
36、利用主成分分析方法将词向量序列y压缩至二维空间,获得二维词向量。
37、优先地,计算加噪后的二维词向量与词向量字典的余弦相似度,得到与其语义最近的相似词向量,包括:
38、计算加噪后的二维词向量与词向量字典的余弦相似度cos_similari:
39、
40、其中,yi·dictj表示加噪后的二维词向量的点积,∥yi∥和∥dictj∥表示加噪后的二维词向量的模,len(dict)表示词向量字典的长度值;
41、找到余弦相似度最大的二维词向量位置索引m,得到与其语义最近的相似词向量。
42、优先地,本发明提供一种电子设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述程序时实现第一方面任一项所述方法的步骤。
43、优先地,本发明提供一种计算机可读存储介质,其上存储有计算机程序,该计算机程序被处理器执行时实现第一方面中任一项所述方法的步骤。
44、本发明所达到的有益效果:
45、本发明利用构建的基于bert-bilstm-bigru-crf的命名实体识别模型对预先获取的中文电子病历语料库进行识别与提取,获得隐私实体;将新华字典数据集嵌入为词向量;利用主成分分析方法压缩词向量为二维词向量字典;利用预先训练获得的word2vec模型将隐私实体转化为隐私实体词向量;利用差分隐私高斯机制对隐私实体词向量进行椭球形噪声处理并压缩至二维,获得二维词向量;计算加噪后的二维词向量与词向量字典的余弦相似度,得到与其语义最近的相似词向量;利用相似词向量对应的字符对中文电子病历的敏感信息进行替换,使用基于命名实体识别模型精确的判定隐私实体,便于后续实现对病人的隐私保护。本发明在原始词向量序列上添加服从多元高斯分布的椭球形噪声,更优地实现了对隐私实体词向量序列的差分隐私保护,弥补了现有技术中对于医疗领域隐私保护的不足。
技术特征:1.结合命名实体识别与差分隐私的病历敏感信息保护方法,其特征在于,包括:
2.根据权利要求1所述的结合命名实体识别与差分隐私的病历敏感信息保护方法,其特征在于,预先训练获得word2vec模型,包括:
3.根据权利要求1所述的结合命名实体识别与差分隐私的病历敏感信息保护方法,其特征在于,基于bert-bilstm-bigru-crf的命名实体识别模型包括依次连接的bert模型、双向lstm层、双向gru层和条件随机场crf。
4.根据权利要求2所述的结合命名实体识别与差分隐私的病历敏感信息保护方法,其特征在于,word2vec模型包括输入层i、隐藏层h和输出层o。
5.根据权利要求4所述的结合命名实体识别与差分隐私的病历敏感信息保护方法,其特征在于,输入层i与隐藏层h之间的权值设为m×n的矩阵m-n,矩阵m-n中每行表示n维向量,隐藏层h为:
6.根据权利要求1所述的结合命名实体识别与差分隐私的病历敏感信息保护方法,其特征在于,将新华字典数据集嵌入为词向量,包括:
7.根据权利要求1所述的结合命名实体识别与差分隐私的病历敏感信息保护方法,其特征在于,利用差分隐私高斯机制对隐私实体词向量进行椭球形噪声处理并压缩至二维,获得二维词向量,包括:
8.根据权利要求1所述的结合命名实体识别与差分隐私的病历敏感信息保护方法,其特征在于,计算加噪后的二维词向量与词向量字典的余弦相似度,得到与其语义最近的相似词向量,包括:
9.一种电子设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,其特征在于,所述处理器执行所述程序时实现权利要求1至8中任一项所述方法的步骤。
10.一种计算机可读存储介质,其上存储有计算机程序,其特征在于,该计算机程序被处理器执行时实现权利要求1至8中任一项所述方法的步骤。
技术总结本发明公开了结合命名实体识别与差分隐私的病历敏感信息保护方法,包括:利用构命名实体识别模型对预先获取的中文电子病历语料库进行识别与提取,获得隐私实体;将新华字典数据集嵌入为词向量;利用主成分分析方法压缩词向量为二维词向量字典;利用预先训练获得的word2vec模型将隐私实体转化为隐私实体词向量;利用差分隐私高斯机制对隐私实体词向量进行椭球形噪声处理并压缩至二维,获得二维词向量;计算加噪后的二维词向量与词向量字典的余弦相似度,得到与其语义最近的相似词向量;利用相似词向量对应的字符对中文电子病历的敏感信息进行替换,对病历敏感信息进行隐藏。技术研发人员:许小龙,何天宇,程勇受保护的技术使用者:南京信息工程大学技术研发日:技术公布日:2024/6/11本文地址:https://www.jishuxx.com/zhuanli/20240615/85176.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表