一种基于生成式对抗网络的DNA存储纠错方法及系统
- 国知局
- 2024-07-11 17:41:59
本文件涉及dna存储,尤其涉及一种基于生成式对抗网络的dna存储纠错方法及系统。
背景技术:
1、随着分布式、云计算和物联网技术的不断发展,全球每天产生的数据总量呈指数级增长。据国际数据公司(idc)预测,到2025年,全球的数据信息总量将达到175zb。然而,传统的磁、光、电等存储技术已无法满足未来持续增长的数据存储需求。相比之下,脱氧核糖核酸(dna)分子作为生命信息存储介质,具有存储容量、稳定性和能耗方面的巨大优势。预计,dna分子的存储密度可达到约107gb/mm3,比传统存储介质提高了6个数量级。因此,dna分子有望成为一种极具潜力的存储介质,解决海量大数据存储的难题。
2、但是,现在的dna存储技术存在着一些问题。dna存储由五个阶段组成:dna合成、聚合酶链反应(pcr)、序列衰变、取样和测序。由于目前合成生物技术的限制,这些阶段最终输出一组无序的噪声序列(reads),这些序列可能会出现序列损失和插入-删除-替换(ids)错误。通常对测序文件进行聚类,将来自同一编码序列的噪声读取分组成簇。之后,进行纠错重构,这也是本专利的主题,旨在从一组噪声的读取中推断出编码序列。
3、在过去的十年中,dna存储中的测序重建问题引起了相当大的关注。现有的研究可以大致分为两组:纠错码(ecc)方法、多序列比对的方法。早期的研究工作主要采用ecc,如reed-solomon码、bch码、hamming码和ldpc码。这些方法通常包括逻辑冗余,并采用序列选择方法,首先选择正确长度的序列,并对错误进行校正。然而,当大量序列被消除时,这些方法的有效性显著下降,尤其是当错误率很高时,它们不适用于错误率超过5%的情况。第二种方法是多序列比对的方法,其中使用启发式算法将来自各个序列的信息合并,即隐藏马尔可夫模型(hmm)、a*算法和图搜索算法。这些算法能够容忍5-15%的错误率,因此超越了基于ecc技术的能力。
技术实现思路
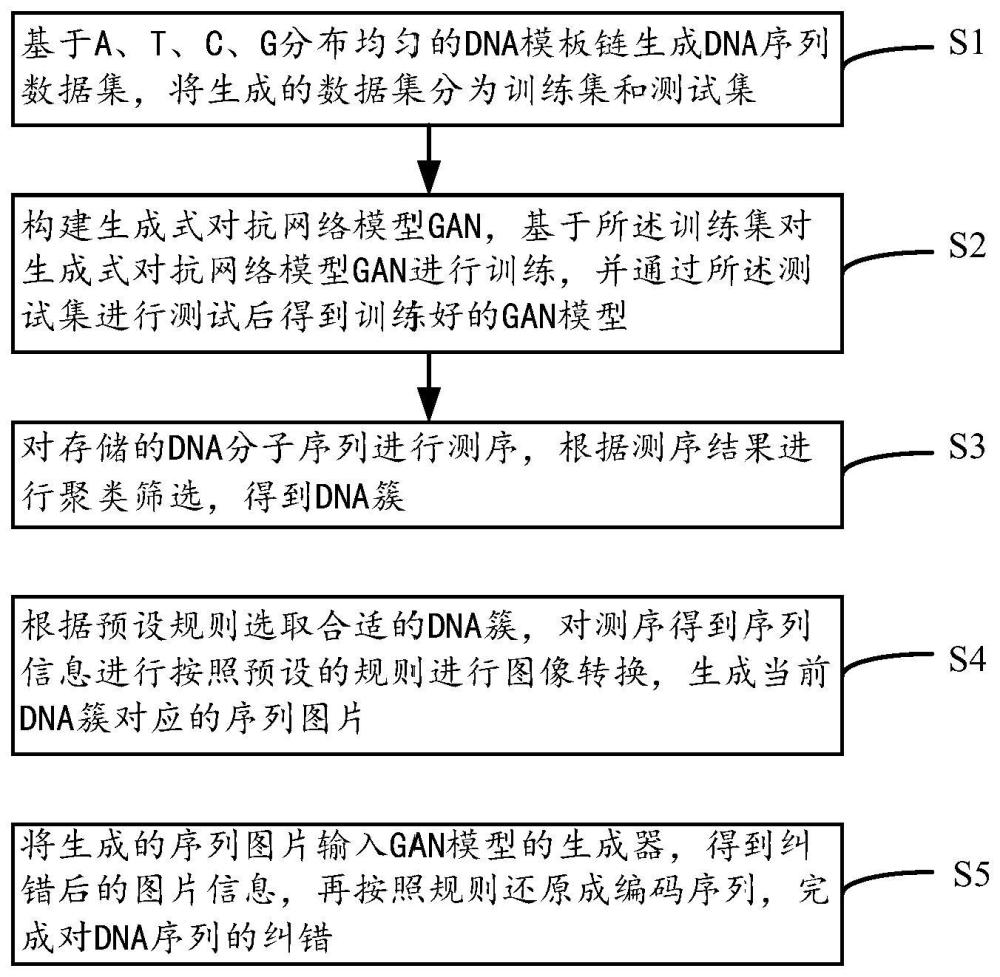
1、本说明书一个或多个实施例提供了一种基于生成式对抗网络的dna存储纠错方法,包括:
2、s1.基于a、t、c、g分布均匀的dna模板链生成dna序列数据集,将生成的数据集分为训练集和测试集;
3、s2.构建生成式对抗网络模型gan,基于所述训练集对生成式对抗网络模型gan进行训练,并通过所述测试集进行测试后得到训练好的gan模型;
4、s3.对存储的dna分子序列进行测序,根据测序结果进行聚类筛选,得到dna簇;
5、s4.根据预设规则选取合适的dna簇,对测序得到序列信息按照预设的规则进行图像转换,生成当前dna簇对应的序列图片;
6、s5.将生成的序列图片输入gan模型的生成器,得到纠错后的图片信息,再按照规则还原成编码序列,完成对dna序列的纠错。
7、进一步地,所述基于a、t、c、g分布均匀的dna模板链生成dna序列数据集具体方法为:
8、生成11000个dna模板链,每个所述dna模板链中碱基a、t、c、g含量相等且分布均匀;
9、对于每个所述dna模板链,生成50个测序序列;每个所述测序序列中的每个碱基发生各种错误的概率相等,所述错误包括碱基插入、删除和替换;
10、把50个测序序列按照预设规则进行图像转换,生成当前50个测序序列对应的序列图片;
11、将模板链复制50次,也通过按照预设规则转为序列图片,得到11000个样本,所述样本为一条dna模板链生成的50条测序dna。
12、进一步地,所述替换错误中,当前碱基替换成其他三种碱基的概率也是相等的。
13、进一步地,所述构建生成式对抗网络模型gan,基于所述训练集对生成式对抗网络模型gan进行训练,并通过所述测试集进行测试后得到训练好的gan模型具体方法为:
14、根据预设规则对训练集样本进行图像转换,将所得到的两个不同方向的图片,进行通道叠加,得到一个6通道的张量x;
15、将x放入生成器模型,通过生成器模型产生纠错后的结果图片g(x);
16、将g(x)和x的其中一张图片进行通道叠加后,放入判别器,或将正确的编码序列图片y和x的其中一张图片进行通道叠加后,放入判别器;
17、将判别器得到的结果分别与0,1计算均方差损失mse,记为如下所示:
18、
19、将g(x)与y计算平均绝对误差mae,记为如下所示:
20、
21、基于所述均方差损失mse和平均绝对误差mae权重计算总损失,如下所示:
22、
23、其中λ为超参数;
24、通过总损失进行后向传播,重新调整模型参数,重复以上步骤n个轮次,得到训练好的gan模型。
25、进一步地,所述对存储的dna分子序列进行测序,根据测序结果进行聚类筛选,得到dna簇具体方法为:
26、用测序仪测序dna分子序列,读取后记为测序序列;
27、对所述测序序列进行聚类处理,具体的:
28、选择初始化的k个样本作为初始聚类中心;
29、针对数据集中每个样本计算它到k个聚类中心的编辑距离并将其分到距离最小的聚类中心所对应的类中;
30、针对每个类别,重新计算它的聚类中心,新的聚类中心为该类的所有样本的质心;
31、重复以上两步操作,直到达到预设的中止条件,得到多个dna簇。
32、进一步地,所述根据预设规则选取合适的dna簇,对测序得到序列信息按照预设的规则进行图像转换,生成当前dna簇对应的序列图片具体方法为:
33、选取合适的dna簇,选取的dna簇中,测序序列数量不少于50个;
34、将剩余的dna簇,每个簇分别按照左右两个方向进行对齐,并按照dna模板链的长度用无碱基n进行填充补齐,剪掉大于模板链长度的部分;
35、将每个簇按照一一对应的规则进行转换,一个碱基对应一种颜色,无碱基n的地方对应白色,一个簇得到2张图片。
36、进一步地,所述将生成的序列图片输入gan模型的生成器,得到纠错后的图片信息,再按照规则还原成编码序列,完成对dna序列的纠错具体方法为:
37、将测序序列的序列图片放入训练好的gan模型的生成器中;
38、对得到的纠错后序列,替换原本测序序列类中质量较差的测序序列,按照预设规则再次生成序列图片,再次放入训练好的gan模型中;
39、重复n次以上步骤;
40、将得到的最后一次的图片信息为纠错后的信息,按照预设规则还原成碱基序列,找到测序序列对应的dna模板链,完成纠错。
41、本说明书一个或多个实施例提供了一种基于生成式对抗网络的dna存储纠错系统,包括:
42、数据生成模块:用于基于a、t、c、g分布均匀的dna模板链生成dna序列数据集,将生成的数据集分为训练集和测试集;
43、模型训练模块:用于构建生成式对抗网络模型gan,基于所述训练集对生成式对抗网络模型gan进行训练,并通过所述测试集进行测试后得到训练好的gan模型;
44、第一处理模块:用于对存储的dna分子序列进行测序,根据测序结果进行聚类筛选,得到dna簇;
45、第二处理模块:用于根据预设规则选取合适的dna簇,对测序得到序列信息按照预设的规则进行图像转换,生成当前dna簇对应的序列图片;
46、数据纠错模块:用于将生成的序列图片输入gan模型的生成器,得到纠错后的图片信息,再按照规则还原成编码序列,完成对dna序列的纠错。
47、本说明书一个或多个实施例提供了一种电子设备,包括:
48、处理器;以及,
49、被安排成存储计算机可执行指令的存储器,所述计算机可执行指令在被执行时使所述处理器实现上述的基于生成式对抗网络的dna存储纠错方法的步骤。
50、本说明书一个或多个实施例提供了一种存储介质,用于存储计算机可执行指令,所述计算机可执行指令在被执行时实现上述的基于生成式对抗网络的dna存储纠错方法的步骤。
51、采用本发明实施例,通过多条读取序列组成的图片,透过模型来实现对序列的纠错,还原成真实的存储在dna中的编码序列,能够获得到准确和可信的dna序列,复现率较高。
52、上述说明仅是本发明技术方案的概述,为了能够更清楚了解本发明的技术手段,而可依照说明书的内容予以实施,并且为了让本发明的上述和其它目的、特征和优点能够更明显易懂,以下特举本发明的具体实施方式。
本文地址:https://www.jishuxx.com/zhuanli/20240615/85688.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。