自适应语音唤醒和人脸唤醒方法、装置、设备及存储介质与流程
- 国知局
- 2024-06-21 10:40:28
[]本发明涉及人工智能,具体地说是一种自适应语音唤醒和人脸唤醒方法、装置、设备及存储介质。
背景技术:
0、[背景技术]
1、在人工智能的潮流推动下,针对语音和人脸的智能化技术不断发展,语音唤醒和人脸唤醒设备成为了大家日常生活中的重要组成部分,这些唤醒设备可以在无需用户手动操作的情况下,使得用户能够通过语音或人脸检测来与设备进行交互,实现便捷操作和个性化服务。
2、然而,现有智能设备的唤醒往往需要用户手动操作,如按下按钮或触摸屏幕才能做好唤醒准备,接下来才可以进行相应的唤醒。这种手动操作的方式不仅繁琐,还限制了设备的使用便捷性,从而给用户带来不好的体验,不够智能和自动化。
3、此外,目前在这个阶段的语音唤醒和人脸唤醒设备仍然存在很多问题。例如,语音检测和人脸检测的准确性非常不稳定,很容易受到外界因素的影响,如环境噪声、光照条件、偏转角度等的影响。
技术实现思路
0、[技术实现要素:]
1、本发明的目的就是要解决上述的不足而提供一种自适应语音唤醒和人脸唤醒方法,克服了传统方案中无法兼顾语音唤醒的实时性和唤醒效果的缺陷,能够保证语音和人脸检测的实时性和准确性,并实现智能自动化的唤醒过程,提升了用户体验。
2、本发明一方面,提供了一种自适应语音唤醒和人脸唤醒方法,包括以下步骤:
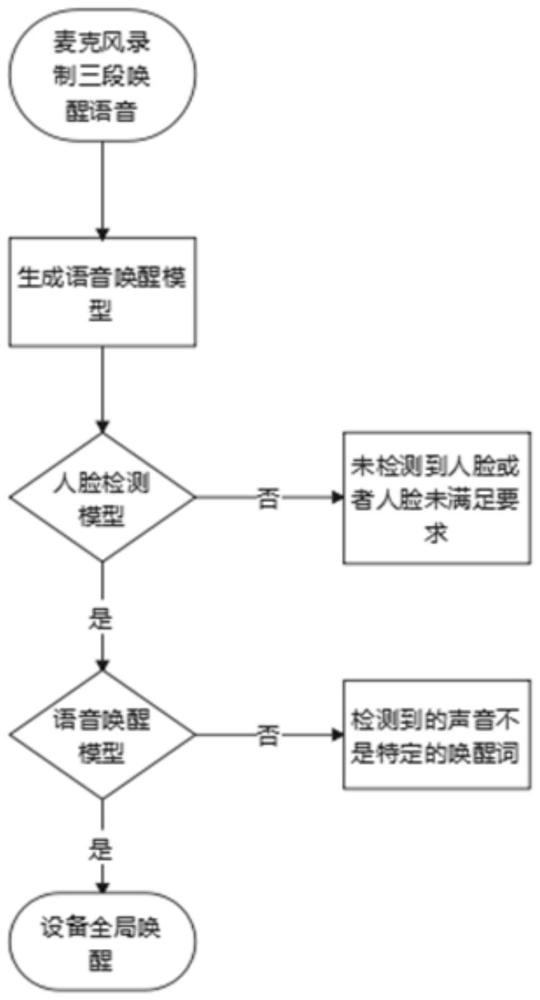
3、1)语音唤醒词定制:通过麦克风录制唤醒关键词语音,后台生成当前智能设备的唤醒信息;
4、2)人脸检测:摄像头检测到人脸,使用当前检测到的实时人脸和后台设置的人脸距离范围以及人脸出现的预设帧数做对比,如果比对失败,则设备返回待机模式;如果比对成功,设备进入人脸局部唤醒模式,接下来等待语音关键词的唤醒;
5、3)语音唤醒词检测:在人脸局部唤醒模式下,监测实时语音流,如果检测到语音唤醒词,则设备进入人脸+语音的全局唤醒模式;否则进入待机模式,继续重复以上步骤,直至进入全局唤醒模式。
6、作为一种实施例,语音唤醒词定制包括以下步骤:
7、(1)采集用户的唤醒语音:用户使用设备麦克风录制自己想要自定义的三段唤醒语音;
8、(2)自定义录制的唤醒语音会上传至设备,后台获取到唤醒语音合成专属的语音唤醒模型;
9、(3)根据唤醒模型以及当前智能设备的状态信息,生成当前智能设备的唤醒信息。
10、作为一种实施例,人脸检测包括以下步骤:
11、(1)基于dlib的resnet模型,摄像头后台检测应用获取摄像头拍摄的实时画面;
12、(2)如果从摄像头画面里面没有检测到人脸,则设备的人脸唤醒为关闭状态;
13、(3)如果检测到人脸,则从128d特征的维度对比前后两帧的人脸信息,利用ot跟踪画面中的人脸;
14、(4)如果人脸距离满足唤醒的距离要求并且满足预设的帧数,则使设备处于人脸唤醒状态,同时生成人脸唤醒指令;
15、(5)接下来等待语音唤醒方式关键词的唤醒。
16、作为一种实施例,语音唤醒词检测时,基于深度神经网络,直接将音频序列编码为固定长度向量进行kws-lstm对序列进行编码,最后直接计算距离即可。
17、作为一种实施例,语音唤醒词检测包括以下步骤:
18、(1)检测设备的工作状态;
19、(2)若设备在第一预设时长内无人脸唤醒交互,自动进入待机模式并且检测外部环境中的声音信号;
20、(3)当设备已经启动人脸唤醒时,通过麦克风获取实时的音频流;
21、(4)将音频流以时间窗口的方式切割成小的语音片段,对每个语音片段使用声学模型提取特征,并将其输入到分类器中进行分类,分类器将为每个语音片段输出一个置信度分数;
22、(5)如果某个语音片段的分数达到预先定义的阈值,则认为该片段包含唤醒词;
23、(6)在连续的音频流中,如果连续的语音片段都被判断为唤醒词,设备进入唤醒模式;否则进入待机模式,继续重复以上步骤,直至设备进入唤醒模式。
24、本发明另一方面,提供了一种自适应语音唤醒和人脸唤醒装置,包括:
25、1)语音唤醒词定制模块:用于通过麦克风录制唤醒关键词语音,后台生成当前智能设备的唤醒信息;
26、2)人脸检测模块:用于通过摄像头检测到人脸,使用当前检测到的实时人脸和后台设置的人脸距离范围以及人脸出现的预设帧数做对比,如果比对失败,则设备返回待机模式;如果比对成功,设备进入人脸局部唤醒模式,接下来等待语音关键词的唤醒;
27、3)语音唤醒词检测模块:用于在人脸局部唤醒模式下,监测实时语音流,如果检测到语音唤醒词,则设备进入人脸+语音的全局唤醒模式;否则进入待机模式。
28、作为一种实施例,所述语音唤醒词定制模块中,用户使用设备麦克风录制自己想要自定义的三段唤醒语音,自定义录制的唤醒语音会上传至设备,后台获取到唤醒语音合成专属的语音唤醒模型,并根据唤醒模型以及当前智能设备的状态信息,生成当前智能设备的唤醒信息;所述人脸检测模块中,摄像头后台检测应用获取摄像头拍摄的实时画面;如果从摄像头画面里面没有检测到人脸,则设备的人脸唤醒为关闭状态;如果检测到人脸,则从128d特征的维度对比前后两帧的人脸信息,利用ot跟踪画面中的人脸;若如果人脸距离满足唤醒的距离要求并且满足预设的帧数,则使设备处于人脸唤醒状态,同时生成人脸唤醒指令。
29、作为一种实施例,所述语音唤醒词检测模块中,检测设备的工作状态,若设备在第一预设时长内无人脸唤醒交互,自动进入待机模式并且检测外部环境中的声音信号;当设备已经启动人脸唤醒时,通过麦克风获取实时的音频流;将音频流以时间窗口的方式切割成小的语音片段,对每个语音片段使用声学模型提取特征,并将其输入到分类器中进行分类,分类器将为每个语音片段输出一个置信度分数;如果某个语音片段的分数达到预先定义的阈值,则认为该片段包含唤醒词;在连续的音频流中,如果连续的语音片段都被判断为唤醒词,设备进入唤醒模式,否则进入待机模式。
30、本发明第三方面,提出了一种计算机设备,包括:处理器、存储器和总线;所述处理器与所述存储器通过所述总线连接;所述存储器用于存储程序,所述处理器用于运行程序,所述程序运行时执行上述方法。
31、本发明第四方面,提出了一种计算机可读存储介质,所述计算机可读存储介质包括存储的程序,所述程序执行上述方法。
32、本发明同现有技术相比,具有如下优点:
33、(1)高度可定制:基于本发明方法,针对不同的用户,可以自由定义自己的唤醒关键词;
34、(2)使用便捷,提升用户体验:用户只需通过自己预设的语音关键词信息就可实现设备的自动唤醒,自动唤醒功能提升了用户对智能设备的使用体验,操作更加便捷,减少了操作上的麻烦;
35、(3)安全性增强:本发明设备只有在人脸出现的距离在预设范围内,并且时长达到预设的帧数情况下才会进入人脸唤醒的局部模式一直监听,但是出于保护用户的隐私,不会将用户的人脸信息和声音上传到任何地方,只有在满足人脸唤醒的局部模式开启的条件下,才会进行之后语音唤醒相关的一系列操作,以及只有语音关键词和人脸同时满足条件的情况下,全局唤醒模式才会启动;
36、(4)本发明克服了传统方案中无法兼顾语音唤醒的实时性和唤醒效果的缺陷,能够在无损唤醒效果的前提下,缩短响应时延,从而实现语音唤醒的唤醒效果与实时性的兼顾,使得对于实时语音流的唤醒检测能够平滑有序;
37、综上,本发明提供了一种自适应语音唤醒和人脸唤醒设备,以解决现有技术中存在的问题,能够保证语音和人脸检测的实时性和准确性,并实现智能自动化的唤醒过程,提升用户体验,值得推广应用。
本文地址:https://www.jishuxx.com/zhuanli/20240618/21105.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表