一种水声重叠目标源瞬时时频点分离重构方法与系统
- 国知局
- 2024-06-21 10:40:55
本发明涉及水声信号处理,特别涉及一种水声重叠目标源瞬时时频点分离重构方法与系统。
背景技术:
1、为保护海洋生物物种,海洋生物的被动声学监测系统需要检测和识别感兴趣物种的声音类别,提供了诸如水声信号分类、声音事件检测和重叠源分离等自动化功能。依据海洋水声信号时频特性,存在三种类型的信号:口哨声(音调分量)、咔哒声(脉冲分量)和背景噪声(噪声分量)。哨声是鲸类海洋生物语言,用于交流和互动。因此,多类型信号混合的哨声检测与分离对海洋生物的被动声学监测十分重要。
2、为了实现脉冲分量和音调分量混合的信号哨声检测,现有相关技术提出卡尔曼滤波器和自动脊线提取算法,但是在脉冲干扰下,影响音调分量的哨声检测性能,尤其脉冲和音调分量重叠的哨声检测。为了解决脉冲分量干扰的哨声检测,现有相关技术进一步提出图搜索、粒子滤波、高斯混合概率假设密度滤波器和顺序蒙特卡洛概率假设密度滤波器等。然而,这些方法对于时频表征中模糊不清的时频分量或非常接近的重叠时频分量,会产生一些随机性脊线追踪错误。一种方向性脊线预测追踪器能提取低分辨率时频表征的重叠分量,但其性能受到重叠脉冲分量的干扰。因此,混合多类型信号的分离仍是被动声学监测系统亟待解决的关键点。
技术实现思路
1、为解决上述现有技术中所存在的混合多类型时频分量的哨声检测技术精度不足的问题,本发明提供一种水声重叠目标源瞬时时频点分离重构方法与系统,用于分离具有音调重叠分量的多目标源,能够抑制脉冲分量和噪声分量干扰,得到能量增强的单目标源信号。
2、为了实现上述技术目的,本发明提供了如下技术方案:
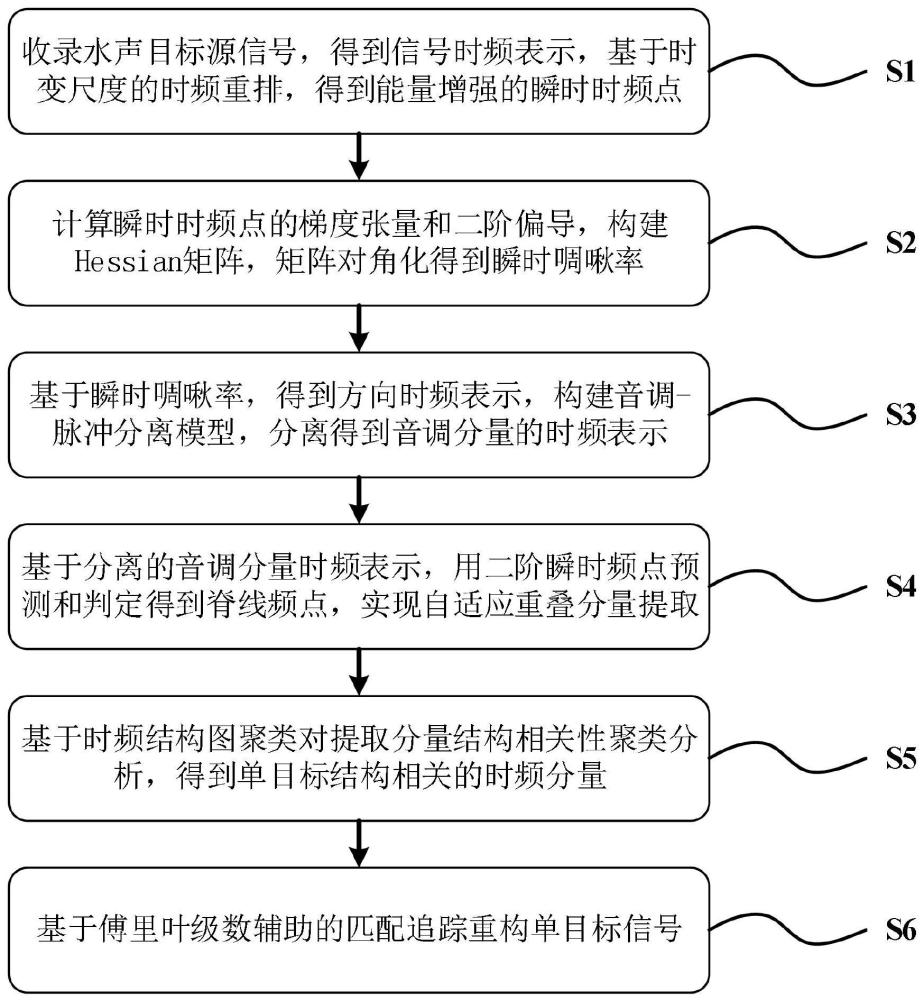
3、一种水声重叠目标源瞬时时频点分离重构方法,包括:
4、获取水下重叠目标源信号,通过时域变换对目标源信号进行处理,生成原始时频点,通过时域重排将所述原始时频点映射至瞬时时频点;
5、构建瞬时时频点的黑塞矩阵和旋转矩阵,基于黑塞矩阵和旋转矩阵,生成瞬时时频点的瞬时啁啾率;
6、根据瞬时啁啾率,生成方向时频表征,对方向时频表征进行滤波及掩码计算,生成音调分量的时频表征;
7、在音调分量的时频表征中,提取音调分量脊线;
8、基于所述音调分量脊线进行音调分量时频结构相似度度量,构建度量结构相似性矩阵,根据度量结构相似性矩阵,生成单目标的音调分量;
9、通过傅里叶级数辅助的匹配追踪方法,对所述单目标的音调分量进行重构,得到单目标信号。
10、可选的,所述时域重排的过程包括:
11、
12、其中,和分别为时频点(t,f)映射的瞬时频率和瞬时时间,t表示时间,f表示频率,σ为窗函数的尺度,表示取虚部,表示取实部,窗函数为h(t)的stft,为具有时移窗函数的辅助stft,为:
13、
14、其中,为实数符合,s(τ)为解析信号,i为虚数单位,(τ-t)为时移。
15、可选的,所述瞬时时频点的黑塞矩阵构建过程为:
16、计算瞬时时频点的梯度张量包括:
17、
18、其中,梯度元素和
19、通过计算瞬时时频点的二阶偏导,得到黑塞矩阵h为:
20、
21、其中,κtt(t,f)和κft(t,f)分别为梯度元素κt(t,f)和κf(t,f)关于时间的偏导,κtf(t,f)和κff(t,f)分别为梯度κt(t,f)和κf(t,f)关于频率的偏导,矩阵参数矩阵参数为具有窗函数t2h(t)的辅助stft。
22、可选的,所述瞬时时频点的旋转矩阵r构建过程包括:
23、
24、其中,矩阵元素c=cosθ(t,f)和s=sinθ(t,f),θ(t,f)为每个瞬时时频点的方向角。
25、可选的,瞬时时频点的瞬时啁啾率的生成过程包括:
26、基于旋转矩阵对黑塞矩阵对角化,当非对角元素为零时,生成瞬时啁啾率tan(θ(t,f):
27、
28、其中,生成参数μ=(κff(t,f)-κtt(t,f))/(κft(t,f)+κtf(t,f))。
29、可选的,音调分量的时频表征的生成过程包括:
30、所方向时频表征为:
31、
32、通过水平和垂直双向中值滤波器对方向时频表征进行滤波,得到音调分量和脉冲分量的滤波增强时频表征和为:
33、
34、其中,median()表示中值滤波函数,lτ,2lτ+1和2lp+1分别为不同的中值滤波器的核大小。
35、基于滤波增强时频表征,计算音调和脉冲分量掩码tτ(t,f)和tp(t,f),根据分量掩码,得到音调分量的时频表征sτ(t,f)和脉冲分量的时频表征sp(t,f)为:
36、
37、可选的,音调分量脊线提取过程包括:
38、在音调分量的时频表征中,通过依次二阶瞬时时频点预测、索引计算及判断,生成音调分量脊线,其中:
39、二阶瞬时时频点即脊线频点预测包括:
40、
41、自适应方向脊线提取包括脊线频点预测,第m脊线τ时刻预测频点的索引计算为
42、
43、其中,pm(τ-1)为第m脊线上τ-1时刻已确定的频点,θm(τ-1,f)为第m脊线上τ-1时刻的瞬时频点方向角,[·]表示四舍五入取整。
44、对预测的脊线频点进行判定,
45、
46、
47、其中,δω∈[δω-,δω+]为频变带宽,δω-为下边界,δω+为上边界,δs为时频幅度阈值,为脊线频点索引pm(τ)所对应的时频幅度值。为对预测脊线频点判断后的索引项,如果索引项在一半频变带宽范围内,则说明预测脊线频点存在,否则当前脊线频点不存在,值为能量极小的时频幅值,近似为零。
48、并依赖频变带宽及索引计算结果,对预测的脊线频点进行判定,根据符合判定结果的脊线频点,生成音调分量脊线。
49、可选的,单目标的音调分量的生成过程包括:
50、音调分量时频结构相似度度量为:
51、
52、其中,和分别为提取的第i和j音调分量相应的时频脊线,nm表示两音调分量零对齐后的长度,记为nm=max{ni,nj},t表示时间,t为音调分量等周期截断的长度,和为遍历第i和j音调分量上的第t时刻的频点;
53、根据度量结果,构建度量结构相似性矩阵,对度量结构相似性矩阵进行聚类分析,提取音调分量结构相关性,获得单目标的音调分量。
54、可选的,对所述单目标的音调分量进行重构的过程包括:
55、基于单目标的所有音调分量,求取重构稀疏系数,并基于重构稀疏系数,通过傅里叶级数辅助的匹配追踪方法,重构单目标信号源;
56、第m音调分量的信号sm为:
57、
58、其中,为第m音调分量的瞬时相位,为瞬时相位的2c+1阶傅里叶级数,cm为2c+1阶傅里叶序列的系数,diag{·}为对角化函数,κm为所提取音调分量脊线的2c+1阶傅里叶级数,υm为重构稀疏系数,zm为待重构的信号,η为信号中的噪声。
59、通过傅里叶级数辅助的匹配追踪过程为:
60、
61、其中,||·||0为计算非零条目数量的l0伪范数,||·||2为l2伪范数,m为从单位矩阵丢弃相应p行的截断矩阵,阈值ε与噪声的标准方差成正比。
62、为了更好的实现上述技术目的,本发明还提供了一种水声重叠目标源瞬时时频点分离重构系统,所述系统用于执行上述的水声重叠目标源瞬时时频点分离重构方法。
63、本发明具有如下技术效果:
64、(1)本技术结合时变尺度的时频重排、瞬时时频点的梯度张量、音调-脉冲分离、二阶瞬时时频点预测与判定,能够对多类型时频分量混合的脊线提取,尤其在强脉冲分量和噪声分量干扰下仍具有较好的重叠音调分量脊线提取性能;
65、(2)本技术时频结构图聚类实现音调分量时频结构相似度度量,能够对多目标时频结构音调分量进行分离,得到单目标结构相关性高的音调分量。
66、(3)本技术傅里叶级数辅助的匹配追踪实现单音调分量的傅里叶级数展开,能对变时频结构的音调分量进行重构,得到单目标信号。
67、(4)本技术在强脉冲和背景噪声干扰下,能够实现水声重叠多目标源的脊线提取和分离,重构能量增强的单目标信号。
本文地址:https://www.jishuxx.com/zhuanli/20240618/21167.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表