结合LSTM改进AE的机器异常声音检测方法和装置
- 国知局
- 2024-06-21 10:40:54
本发明涉及异常声音检测,尤其涉及一种结合lstm改进ae的机器异常声音检测方法和装置。
背景技术:
1、随着声音信号高维度、非线性、多项混叠等问题的出现以及深度学习的发展,选择进行声音异常检测的方法已由机器学习转变为利用神经网络去对声音信号进行建模分析。如marchi等提出使用长短时记忆递归神经网络完成声音的建模任务。
2、由于工厂机器音频样本不平衡问题,采用无监督学习方式。无监督学习目前主流方式为离群值检测,比如自编码器(auto-encoder,ae)和变分自编码器(variationalauto-encoder,vae)。由于ae提取复杂数据潜在特征的能力不足、对噪音干扰敏感以及模型受训练数据体量大小的影响。先后有文献提出dae和ssfe-ae,dae通过改变ae结构和神经元分布状态去提高ae对正常声音的特征提取和重构能力。ssfe-ae首先通过对正常声音添加粉噪音构造异常数据,然后将人造的数据和原始数据混合后通过一种自监督提取器(ssfe)提取声音的特征用于训练ae。但是它们进行异常声音检测准确性和通用性仍不够理想,因此,我们基于多个工厂机器声音数据集提出一种分别改进ae和vae的方法,且将改进的vae作为生成正常声音的生成模型和改进的ae作为检测待检测声音的检测模型,将两者先后搭配使用从而提高机器异常声音检测的准确率和通用性。
技术实现思路
1、本发明的主要目的在于提供一种结合lstm改进ae的机器异常声音检测方法和装置,旨在解决现有技术中在无监督条件下进行机器异常声音检测准确性和通用性不理想的技术问题,该方法更充分地提取和还原正常声音特征,从而更准确地重构正常声音和检测正常与异常声音,能显著提高异常声音检测准确率。
2、为实现上述目的,本发明提供了一种结合lstm改进ae的机器异常声音检测方法。所述方法包括以下步骤:
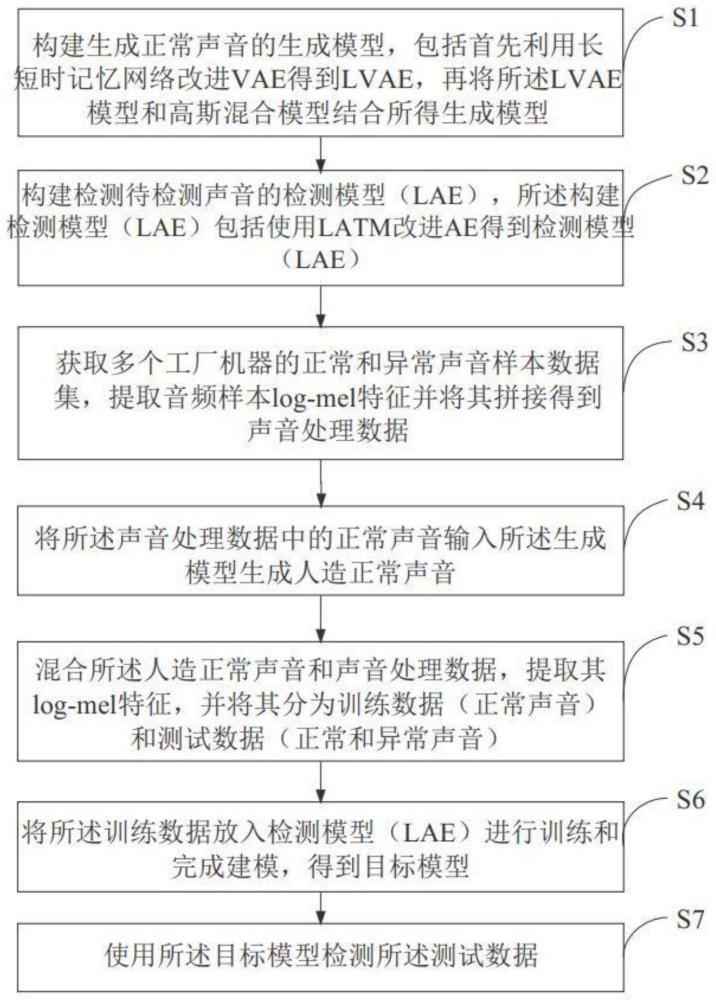
3、构建生成正常声音的生成模型,所述生成正常声音的生成模型包括首先利用长短时记忆网络(long short term memory,lstm)改进vae得到lvae,再将所述lvae模型和高斯混合模型(gaussianmixture model,gmm)结合所得生成模型;构建检测待检测声音的检测模型(lae),所述检测待检测声音的检测模型包括使用lstm改进ae得到检测模型(lae);获取多个工厂机器的正常和异常声音样本数据集,提取音频样本log-mel特征并将其拼接得到声音处理数据;将所述声音处理数据中的正常声音输入所述生成模型生成人造正常声音;混合所述人造正常声音和声音处理数据,提取其log-mel特征,并将其分为训练数据(正常声音)和测试数据(正常和异常声音);将所述训练数据放入检测模型(lae)进行训练和完成建模,得到目标模型;使用所述目标模型检测所述测试数据。
4、根据本发明的一个实施例,构建生成正常声音的生成模型,所述生成模型具体用于:扩充正常声音样本,以便于检测模型(lae)充分学习到正常声音的分布空间。包括以下步骤:先后利用lstm和gmm改进vae得到生成正常声音的生成模型。
5、步骤1,用lstm改进vae得到lvae模型,从而提高表征和重构正常声音信息的能力。具体的lstm改进vae分为如下几个步骤:
6、步骤11,结合原始vae的损失函数并修改lstm遗忘门f,使得人造数据分布更加均匀,lvae的损失函数如下
7、
8、其中,σ2为方差μ为均值。
9、步骤12,修改所述vae中隐变量的采样方式,由原来的线性采样改为非线性采样,lvae采样向量由如下公式计算得到
10、
11、其中,修改增大了σ项,即增大了采样向量z的采样值,同时,ε的标准差由原来的1改为1.5,均值不变。
12、步骤13,将所述vae的解码器和编码器由全连接结构替换为lstm结构;
13、具体地,所述改进的vae第n层编码器输出状态h、状态c和状态o,输出状态o传递给两个全连接层μ和σ层;z层采样向量通过对μ层和σ层输出做非线性变换得到。第n层解码器接受第n层编码器输出状态h与状态c和z层的输出状态o。
14、步骤2,用gmm改进lvae得到生成模型,从而减少所述lvae模型生成正常声音的重构误差。具体的gmm改进lvae分为如下几个步骤:
15、步骤21,结合gmm的em算法中的m步,模型中所述gmm的参数估计如下
16、
17、其中,
18、
19、
20、
21、zt为所述lvae产生的采样向量;γti为样本zt属于第i(i=1,2,…,m)个高斯分布的后验概率;k表示迭代的次数;t表示zt的维度。
22、步骤22,使用所述gmm学习所述lvae编码器生成的正常声音特征向量分布,从而生成人造的特征向量。再将所得人造的特征向量输入所述lvae的解码器得到与所述输入数据等量的人造正常声音。
23、根据本发明的一个实施例,构建检测待检测声音的检测模型(lae),所述检测模型具体用于:学习正常声音,检测待输入的正常和异常声音。包括以下步骤:利用lstm改进ae得到检测待检测声音的检测模型(lae)。
24、其中,所述用lstm改进ae具体用于:通过提高表征和重构正常声音信息的能力,更好地达到检测正常与异常声音的检测效果。包括以下步骤:将ae的解码器和编码器由全连接结构替换为lstm结构得到检测模型(lae)。
25、具体地,所述改进的ae第n层编码器输出状态h、状态c和状态o,状态o输入瓶颈层,第n层解码器接受状态h与状态c和瓶颈层输出的状态o,设置输出层输入为解码器第n层状态h的输出。
26、根据本发明的一个实施例,使用所述检测模型(lae)检测待检测声音,具体用于:将重构误差和检测阈值比较以检测正常和异常声音。包括以下步骤:将测试数据(正常和异常声音)输入检测模型完成检测。
27、具体地,检测模型完成检测包含以下步骤:
28、步骤1,所述检测模型(lae)特征提取和重构待检测声音;
29、步骤2,所述检测模型(lae)利用所述待检测声音与其重构声音数据的差异计算重构误差;
30、步骤3,所述检测模型(lae)将所述重构误差和检测阈值进行比较以检测正常和异常声音,当所述重构误差高于所述检测阈值时,将检测到的声音判别为异常声音,否则为正常声音。
31、本发明还提出了一种结合lstm改进ae的机器异常声音检测装置,包括构建模型模块:构建生成正常声音的生成模型和检测正常和异常声音的检测模型(lae);获取数据模块:用来获取用于生成的声音数据和用于检测的声音数据;数据生成模块:用来将所述正常声音处理数据输入所述生成模型生成人造正常声音;模型训练模块:用来基于所述lvae的参数,使用所述训练数据训练所述声音检测模型(lae)并完成建模,得到用于检测待检测声音的目标模型;异常检测模块:使用所述目标模型重构所述测试数据并计算重构误差,同时目标模型根据所述检测阈值检测输入声音是否为异常声音。
32、本发明具有能有效提取正常声音特征和重构正常声音的优点,进而有效提高检测多个机器的待检测正常和异常声音的检测准确率。
本文地址:https://www.jishuxx.com/zhuanli/20240618/21164.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
上一篇
音输出系统的制作方法
下一篇
返回列表