一种语音唤醒的方法及装置与流程
- 国知局
- 2024-06-21 10:40:58
本发明涉及语音处理,特别涉及一种语音唤醒的方法及装置。
背景技术:
1、随着社会和电子信息技术的发展,人工智能产品成为生活当中不可或缺的必需品,如智能音箱、智能汽车、智能电视、智能空调等。唤醒功能是大多数智能语音交互设备的一个重要入口,由于对计算资源、网络流量、系统复杂和稳定性等方面的平衡,在开始语音对话之前,都有一个作为入口的唤醒功能,如“嗨,siri”、“小度小度”、“天猫精灵”、“小爱小爱”等等。
2、衡量唤醒功能好坏的主要指标是唤醒率和误唤醒率。前者是在一定的唤醒输入中,唤醒的次数,如唤醒率95%,表示测试100次,唤醒了95次。后者一般使用误唤醒出现一次的时长,如8次/小时。
3、然而,唤醒功能在遇到口音、高噪声、语速等输入时,在保持一定的误唤醒水平时,可能会在口音、快语速、噪声时出现唤醒率不高的情况,此时唤醒词的声音会变调,从而导致唤醒率低。
4、例1:对唤醒上一首歌曲来说,词典中预制的标准唤醒发音是“shang4yi4 shou3”(拼音和声调),但由于口音等原因,发音可能会是“sang4yi4 sou3”。
5、例2:对唤醒词查看全程来说,词典中预制的标准唤醒发音是“cha2kan4 quan2cheng2”,而发音可能会是“ca2 ge4 quan2 cheng2”。
6、例3:唤醒词中可能存在多字的问题,如对唤醒词“打开导航”来说,录入为“打开不了导航”,此时可能会容易造成“打开导航”的误唤醒。
7、综上,唤醒系统的唤醒率和误唤率需要平衡,最终在可接受的误唤醒水平下提高唤醒率,以使系统体验最优。因此,需要改进现有技术,使得改善误唤醒率的同时,使唤醒率也能得到提升。
技术实现思路
1、鉴于现有技术中的上述缺陷或不足,本发明提供了一种语音唤醒的方法及装置,能够解决上述存在的技术问题。
2、本发明的一个方面,提供了一种语音唤醒的方法,包括如下步骤:
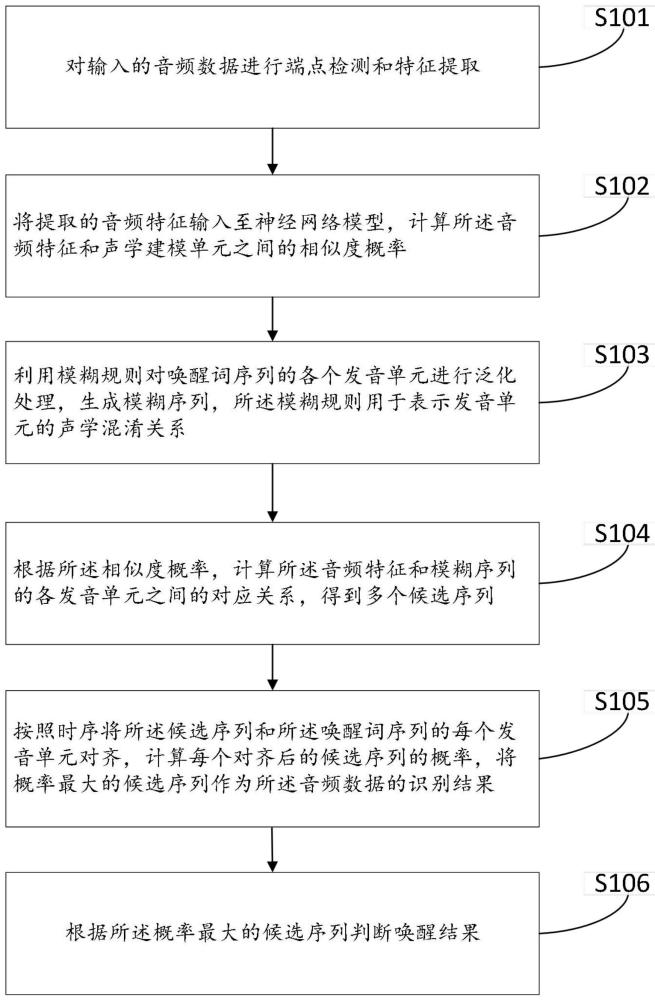
3、对输入的音频数据进行端点检测和特征提取;
4、将提取的音频特征输入至神经网络模型,计算所述音频特征和声学建模单元之间的相似度概率;
5、利用模糊规则对唤醒词序列的各个发音单元进行泛化处理,生成模糊序列,所述模糊规则用于表示发音单元的声学混淆关系;
6、根据所述相似度概率,计算所述音频特征和模糊序列的各发音单元之间的对应关系,得到多个候选序列;
7、按照时序将所述候选序列和所述唤醒词序列的每个发音单元对齐,计算每个对齐后的候选序列的概率,将概率最大的候选序列作为所述音频数据的识别结果;
8、根据所述概率最大的候选序列判断唤醒结果。
9、进一步的,所述利用模糊规则对唤醒词序列的各个发音单元进行泛化处理的步骤,包括:
10、通过模糊规则获取唤醒词序列的每个发音单元对应的易混淆发音,将混淆概率大于预设阈值的所述易混淆发音作为该发音单元对应的模糊集合;
11、根据每个发音单元对应的模糊集合,构建模糊序列。
12、进一步的,根据所述相似度概率,计算所述音频特征和模糊序列的各发音单元之间的对应关系,得到多个候选序列的步骤,包括:
13、将所述音频特征最有可能对应的声学建模单元的发音与模糊序列的每个发音单元进行比较,将发音相似度大于预设阈值的声学建模单元的发音作为模糊序列的发音单元对应的候选发音;
14、根据每个发音单元对应的候选发音,形成多个候选序列。
15、进一步的,按照时序将所述候选序列和所述唤醒词序列的每个发音单元对齐,计算每个对齐后的候选序列的概率的步骤,包括:
16、若候选序列与唤醒词序列相比缺失了发音单元,则将候选序列中缺失的发音单元的缺失概率和该缺失的发音单元的所述相似度概率的乘积作为缺失的发音单元的实际概率;将缺失的发音单元的实际概率和其它发音单元的所述相似度概率的乘积作为对齐后的该候选序列的概率。
17、进一步的,按照时序将所述候选序列和所述唤醒词序列的每个发音单元对齐,计算每个对齐后的候选序列的概率的步骤,包括:
18、若候选序列与唤醒词序列的发音单元数量相同,但发音单元的发音易于混淆,则将候选序列中每个要替换的发音单元的混淆概率和该发音单元对应的所述相似度概率的乘积,作为要替换的发音单元的实际概率;将要替换的每个发音单元的实际概率的乘积作为对齐后的该候选序列的概率。
19、进一步的,按照时序将所述候选序列和所述唤醒词序列的每个发音单元对齐,计算每个对齐后的候选序列的概率的步骤,包括:
20、若候选序列与唤醒词序列相比多出了发音单元,则将该候选序列多出的发音单元的删除概率和惩罚系数的乘积作为该多出的发音单元的实际概率;将所述多出的发音单元的实际概率和其它发音单元的所述相似度概率的乘积作为对齐后的该候选序列的概率。
21、进一步的,所述候选序列中多出的发音单元的删除概率越大,所述惩罚系数越小;候选序列中多出的发音单元对应的语音属性值越大,惩罚系数越大;候选序列中多出的发音单元与唤醒词序列中对齐的目标发音单元的混淆概率越大,惩罚系数越小。
22、进一步的,对齐后的候选序列的概率为候选序列中各发音单元的概率乘积的几何平均值。
23、本发明的另一方面,提供了一种语音唤醒的装置,包括:
24、特征提取模块,被配置为对输入的音频数据进行端点检测和特征提取;
25、相似度计算模块,被配置为将提取的音频特征输入至神经网络模型,计算所述音频特征和声学建模单元之间的相似度概率;
26、模糊泛化模块,被配置为利用模糊规则对唤醒词序列的各个发音单元进行泛化处理,生成模糊序列,所述模糊规则用于表示发音单元的声学混淆关系;
27、候选序列获取模块,被配置为根据所述相似度概率,计算所述音频特征和模糊序列的各发音单元之间的对应关系,得到多个候选序列;
28、候选序列筛选模块,被配置为按照时序将所述候选序列和所述唤醒词序列的每个发音单元对齐,计算每个对齐后的候选序列的概率,将概率最大的候选序列作为所述音频数据的识别结果;
29、唤醒模块,被配置为根据所述概率最大的候选序列判断唤醒结果。
30、进一步的,所述模糊泛化模块,被配置为通过模糊规则获取唤醒词序列的每个发音单元对应的易混淆发音,将混淆概率大于预设阈值的所述易混淆发音作为该发音单元对应的模糊集合;根据每个发音单元对应的模糊集合,构建模糊序列;
31、所述候选序列获取模块,被配置为将所述音频特征最有可能对应的声学建模单元的发音与模糊序列的每个发音单元进行比较,将发音相似度大于预设阈值的声学建模单元的发音作为模糊序列的发音单元对应的候选发音;
32、所述候选序列筛选模块,被配置为:
33、若候选序列与唤醒词序列相比缺失了发音单元,则将候选序列中缺失的发音单元的缺失概率和该缺失的发音单元的所述相似度概率的乘积作为缺失的发音单元的实际概率;将缺失的发音单元的实际概率和其它发音单元的所述相似度概率的乘积作为对齐后的该候选序列的概率;
34、若候选序列与唤醒词序列的发音单元数量相同,但发音单元的发音易于混淆,则将候选序列中每个要替换的发音单元的混淆概率和该发音单元对应的所述相似度概率的乘积,作为要替换的发音单元的实际概率;将要替换的每个发音单元的实际概率的乘积作为对齐后的该候选序列的概率;
35、若候选序列与唤醒词序列相比多出了发音单元,则将该候选序列多出的发音单元的删除概率和惩罚系数的乘积作为该多出的发音单元的实际概率;将所述多出的发音单元的实际概率和其它发音单元的所述相似度概率的乘积作为对齐后的该候选序列的概率。
36、综上所述,本发明提供的一种语音唤醒的方法及装置,能够在改善误唤醒率的同时,使唤醒率也得到提升。特别是通过对非模糊元素(实际唤醒词比预置的唤醒词序列多字)在对齐过程中增加干扰的方式(惩罚系数),来阻止此类误唤醒问题。
本文地址:https://www.jishuxx.com/zhuanli/20240618/21175.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表