语音合成方法及装置与流程
- 国知局
- 2024-06-21 10:40:56
本申请涉及语音处理,具体而言,涉及一种语音合成方法及装置。
背景技术:
1、当前的语音合成技术在模仿人类语音方面取得了巨大进展,这得益于深度学习模型的应用。深度学习模型通过神经网络学习声音特征和语音模式,使得合成语音在音色、语调和风格方面更接近于真实说话人。然而,尽管取得了显著进展,语音合成仍然面临着挑战,主要体现在合成语音的自然度问题上。
2、存在上述问题的主要原因在于模型尚未能够全面理解人类语音的复杂性。真实语音中蕴含着丰富的情感、语境、以及个体特有的说话习惯,而当前的模型难以准确捕捉到这些微妙之处。
3、针对上述的问题,目前尚未提出有效的解决方案。
技术实现思路
1、本申请实施例提供了一种语音合成方法及装置,以至少解决现有语音合成技术中自然度不够的技术问题。
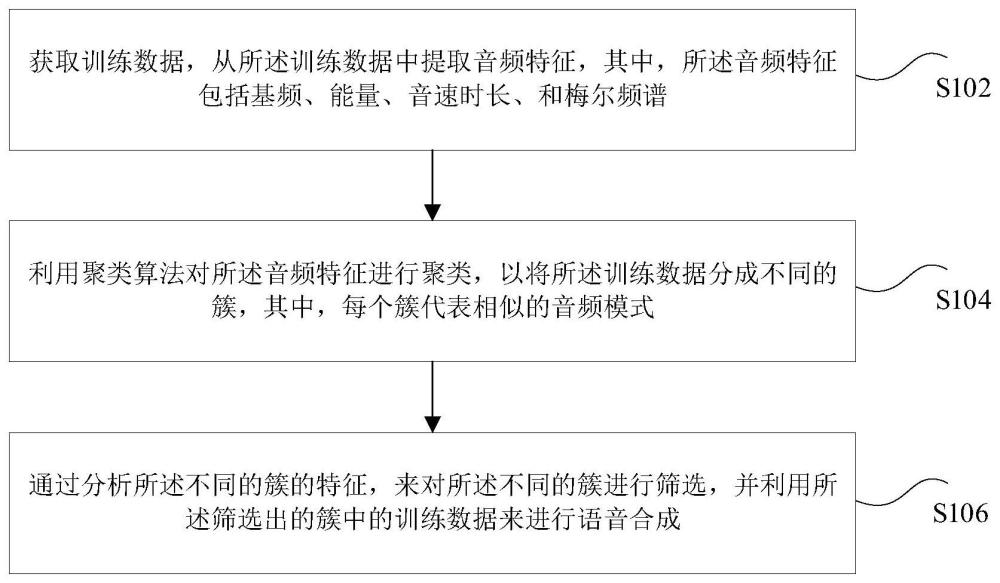
2、根据本申请实施例的一个方面,提供了一种语音合成方法,包括:获取训练数据,从所述训练数据中提取音频特征,其中,所述音频特征包括基频、能量、音速时长、和梅尔频谱;利用聚类算法对所述音频特征进行聚类,以将所述训练数据分成不同的簇,其中,每个簇代表相似的音频模式;通过分析所述不同的簇的特征,来对所述不同的簇进行筛选,并利用所述筛选出的簇中的训练数据来进行语音合成。
3、根据本申请实施例的另一方面,还提供了一种语音合成装置,包括:获取模块,被配置为获取训练数据,从所述训练数据中提取音频特征,其中,所述音频特征包括基频、能量、音速时长、和梅尔频谱;聚类模块,被配置为利用聚类算法对所述音频特征进行聚类,以将所述训练数据分成不同的簇,其中,每个簇代表相似的音频模式;合成模块,被配置为通过分析所述不同的簇的特征,来对所述不同的簇进行筛选,并利用所述筛选出的簇中的训练数据来进行语音合成。
4、在本申请实施例中,获取训练数据,从所述训练数据中提取音频特征,其中,所述音频特征包括基频、能量、音速时长、和梅尔频谱;利用聚类算法对所述音频特征进行聚类,以将所述训练数据分成不同的簇,其中,每个簇代表相似的音频模式;通过分析所述不同的簇的特征,来对所述不同的簇进行筛选,并利用所述筛选出的簇中的训练数据来进行语音合成。通过上述方案,解决了现有语音合成技术中自然度不够的技术问题。
技术特征:1.一种语音合成方法,其特征在于,包括:
2.根据权利要求1所述的方法,其特征在于,在从所述训练数据中提取音频特征之后,所述方法还包括:
3.根据权利要求1所述的方法,其特征在于,利用聚类算法对所述音频特征进行聚类,包括:
4.根据权利要求3所述的方法,其特征在于,分别计算所述音频特征中每一个未被归类的音频特征的特征向量到各个簇的聚类中心的距离,包括:
5.根据权利要求3所述的方法,其特征在于,在将该未被归类的音频特征归属为与各个所述距离中最小的距离相应的簇之后,所述方法还包括:
6.根据权利要求1所述的方法,其特征在于,通过分析所述不同的簇的特征,来对所述不同的簇进行筛选,包括:
7.根据权利要求1所述的方法,其特征在于,利用所述筛选出的簇中的训练数据来进行语音合成,包括:
8.一种语音合成装置,其特征在于,包括:
9.一种电子设备,其特征在于,包括:
10.一种计算机可读存储介质,其上存储有程序,其特征在于,在所述程序运行时,使得计算机执行如权利要求1至7中任一项所述的方法。
技术总结本申请提供了一种语音合成方法及装置,其中,该方法包括:获取训练数据,从所述训练数据中提取音频特征,其中,所述音频特征包括基频、能量、音速时长、和梅尔频谱;利用聚类算法对所述音频特征进行聚类,以将所述训练数据分成不同的簇,其中,每个簇代表相似的音频模式;通过分析所述不同的簇的特征,来对所述不同的簇进行筛选,并利用所述筛选出的簇中的训练数据来进行语音合成。本申请解决了现有语音合成技术中自然度不够的技术问题。技术研发人员:蒋正浩,王建成受保护的技术使用者:世优(北京)科技有限公司技术研发日:技术公布日:2024/1/25本文地址:https://www.jishuxx.com/zhuanli/20240618/21170.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表