基于热词特征向量自注意力机制的语音识别模型构建方法与流程
- 国知局
- 2024-06-21 10:41:05
本发明涉及语音识别,具体是涉及一种基于热词特征向量自注意力机制的语音识别模型构建方法。
背景技术:
1、语音识别(automatic speech recognition,asr),是使用机器自动将语音转写为文字的技术。随着大数据、算力以及算法的不断发展,语音识别算法由传统的基于混合高斯(gaussian mixture model, gmm)-隐马尔可夫模型(hidden markov model, hmm)逐渐发展为基于深度学习算法的模型,识别效果、解码速度均有了明显提升,已经在生活中得到了广泛的应用,例如语音输入、语音助手等功能,极大地提高了智能设备的推广应用,极大便利了人类生活。
2、然而,虽然当前语音识别系统的识别效果已经得到了较为明显的提升,但是个性化场景下的识别效果不佳,特别是和用户相关的某些关键词(后续简称“热词”)识别错误将极大地影响用户体验。因此为了适应不同场景的需要,满足用户个性化需求,多数asr提供热词输入接口,允许用户输入指定热词,通过热词增强技术提高热词识别准确率,防止热词识别错误,提高用户体验。
3、一般热词定制化工作大致可以分为以下步骤:1)用户传入多个指定热词;2)系统自动对这些热词进行分词操作,并以此为基础构建基于加权有限状态转录机(weightedfinite-state transducer/wfst)或者ac自动机(aho-corasick automaton)的热词词图;3)设计viterbi静态解码方案或者lattice静态解码方案对模型编码结果进行解码。
4、使用这种热词定制化方法可以一定程度上提高语音识别模型对热词的识别准确率,但是该方法存在下述问题:1)用户在传入热词进行热词词图构建,当传入热词数量过多时,将导致热词词图过大,极大影响到解码速度,同时提高热词误识别发生的可能性;2)设计解码逻辑的方案极大依赖于专家知识,且需要针对不同的语种需要设置不同的判定方案,设计耗时过长且成本过高,稳定性不高;3)热词机制的实现方案和模型训练割裂,在模型训练阶段未充分考虑热词的识别准确率问题,仅在解码阶段添加额外的热词加强策略,准确率不高误差传递较为明显。
技术实现思路
1、针对上述背景技术指出的问题,本发明创造性地提供了一种基于热词特征向量自注意力机制的语音识别模型构建方法。
2、本发明的技术方案: 基于热词特征向量自注意力机制的语音识别模型构建方法,包括如下步骤:
3、s1以decoder-only的方式训练预训练模型,对词嵌入层进行优化;
4、s2应用热词训练数据序列训练热词编码模型,提取热词特征向量;
5、s3训练接收以热词特征向量为背景信息的语音识别模型,使用热词编码模型对随机抽取的热词进行编码,在注意力机制计算过程中得到的候选热词特征向量与音频特征向量进行拼接,在编码过程中使用基于热词特征向量自注意力机制(self-attention basedhotword context)将热词信息与音频信息融合,得到融合特征向量作为最终的解码器输入。
6、所述步骤s1中预训练模型包括:词嵌入层、特征编码器、分类器;
7、所述词嵌入层由embedding层构成;
8、所述特征编码器是由若干层单向长短期记忆人工神经网络(lstm)构成;
9、所述分类器classic由全连接层构成,该全连接层和词嵌入层共享参数;
10、进一步地,所述步骤s1具体如下:
11、s1-1应用大量文本对预训练模型的词嵌入层进行预训练
12、s1-1-1随机初始化预训练模型参数;
13、s1-1-2通过词嵌入层对输入序列进行编码转换为词向量序列;
14、s1-1-3通过特征编码器对词向量序列进行编码和特征提取;
15、s1-1-4使用分类器计算逻辑回归评分,并通过归一化指数函数(softmax)进行归一化处理;
16、s1-1-5通过交叉熵损失函数(cross entropy)计算损失值并进行模型更新。
17、进一步地,所述预训练模型的计算公式为:
18、
19、
20、
21、
22、
23、式中,为序列起始符对应的字符索引,为真实字符索引序列,其中表示序列长度,字符索引的取值范围为之间的正整数个正整数,表示字典大小,表示与拼接得到的待编码的字符索引序列;
24、表示词嵌入层,为转换得到的词向量序列,表示词向量的维度;
25、表示单向 lstm构成的特征编码器,为特征编码器编码结果;
26、表示分类器,表示编码结果经过分类器后得到的逻辑回归值。表示归一化指数函数,表示经过归一化后的概率分布,表示下一个字符出现的概率;
27、为序列终止符对应的字符索引,表示与拼接得到的拟合目标,表示交叉熵损失函数,为标量,衡量预测的概率分布和真实序列之间的差异。
28、s1-2在完成模型预训练后,舍弃除词嵌入层外的其他层,仅保留词嵌入层参数,应用于步骤s2中热词编码模型的词嵌入层权重。
29、所述步骤s2中热词编码模型包括:词嵌入层,特征编码器和仅在训练过程中生效的特征解码器;
30、所述词嵌入层由embedding层构成,在训练阶段初始化为s1中预训练模型的词嵌入层的权重;
31、所述特征编码器是由若干层双向长短期记忆人工神经网络(bilstm)构成;
32、所述仅在训练过程中生效的特征解码器是由若干层单向长短期记忆人工神经网络(lstm)构成。
33、进一步地,所述步骤s2具体包括:
34、s2-1准备训练数据,具体为:
35、s2-1-1使用分词工具对大量文本进行分词处理,获取常见的词汇数据;
36、s2-1-2使用字典中的字符随机生成词汇,用于模拟用户可能输入的稀有词汇数据;
37、s2-1-3将s2-1-1与s2-1-2的数据组合去重,得到热词训练数据序列。
38、s2-2应用热词训练数据序列对热词编码模型进行训练,具体为:
39、s2-2-1通过词嵌入层对热词训练数据序列进行编码转换为词向量序列;
40、s2-2-2通过特征编码器对词向量序列进行编码和特征提取,获取热词特征向量;
41、s2-2-3特征解码器的初始状态初始化为热词特征向量,将热词特征向量作为输入,进行解码;
42、s2-2-4使用分类器计算逻辑回归评分,并通过归一化指数函数(softmax)进行归一化处理;
43、s2-2-5通过交叉熵损失函数(cross entropy)计算损失值并进行模型更新。
44、进一步地,所述热词编码模型训练以及提取热词特征向量的计算公式为:
45、
46、
47、
48、
49、
50、
51、
52、
53、式中,为待编码的热词字符索引序列,其中表示热词序列长度,字符索引的取值范围为之间的正整数个正整数,表示字典大小;
54、表示词嵌入层,为转换得到的词向量序列,表示词向量的维度;
55、表示双向 lstm构成的特征编码器,为特征编码器编码结果;为计算均值函数,对在时间维度上求均值,为获取的热词特征向量;
56、为序列起始符对应的字符索引,为真实字符索引序列,其中表示序列长度,字符索引的取值范围为之间的正整数个正整数,表示字典大小,表示与拼接得到的待编码的字符索引序列,表示词嵌入层,为转换得到的词向量序列,表示词向量的维度;
57、表示单向 lstm构成的特征解码器,表示将特征解码器状态初始化为,为特征编码器编码结果;
58、表示分类器,表示编码结果经过分类器后得到的逻辑回归值。表示归一化指数函数,表示经过归一化后的概率分布,表示下一个字符出现的概率;为序列终止符对应的字符索引,表示与拼接得到的拟合目标,表示交叉熵损失函数,为标量,衡量预测的概率分布和真实序列之间的差异。
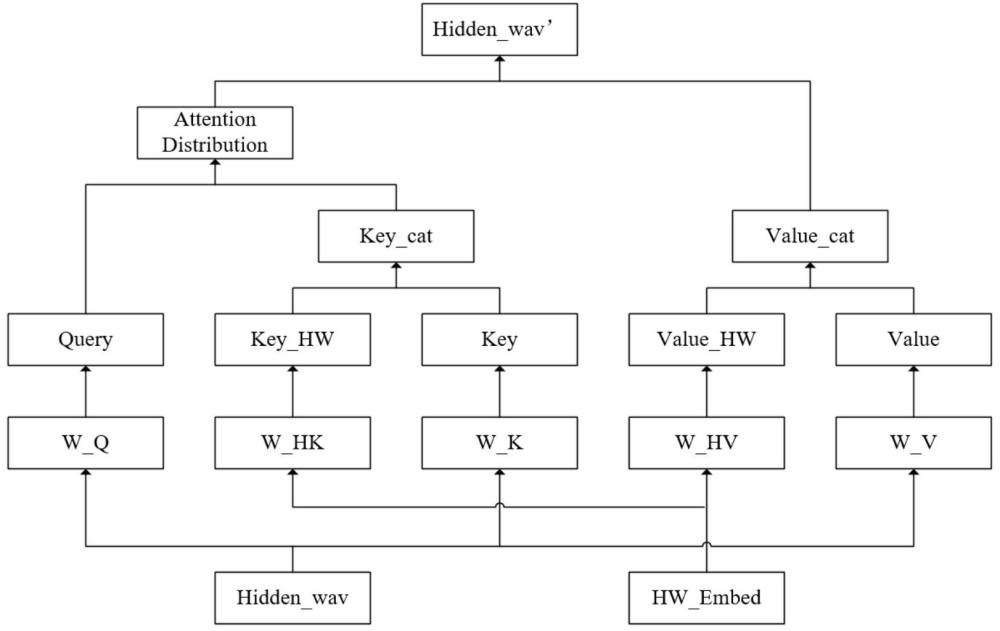
59、所述步骤s3中,接收以热词特征向量为背景信息的语音识别模型采用的是连接时序分类(connectionist temporal classification,ctc)/编码器-解码器(encoder-decoder)联合结构的变压器模型(transformer),其中编码器(encoder)为使用基于热词特征向量自注意力机制(self-attention based hotword context)的卷积增强变压器模块(conformer blocks),解码器(decoder)为一般变压器模型(transformer)的解码器(decoder)。
60、进一步地,所述步骤s3具体包括:
61、s3-1准备训练数据
62、s3-1-1使用分词工具对当前待使用的音频-文本对中的文本进行分词处理,随机抽取m个词作为热词;
63、s3-1-2随机组合生成n个热词,前述的随机抽取m个热词拼接形成音频-文本-候选热词组数据;
64、s3-2应用音频-文本-候选热词组数据对语音识别模型进行训练
65、s3-2-1对音频提取音频特征,使用热词编码模型将候选热词组转换为热词特征向量;
66、s3-2-2使用卷积降采样层对音频进行降采样,并初步提取音频特征向量;
67、s3-2-3将热词特征向量与音频特征向量输入到若干个基于热词特征向量自注意力机制(self-attention based hotword context)的卷积增强变压器模块(conformerblocks)中进一步提取特征,使得热词信息与音频信息有效融合得到融合特征向量;
68、s3-2-4将融合特征向量和真实文本输入到连接时序分类层(connectionisttemporal classification,ctc)和解码器(decoder)中计算损失值。
69、进一步地,所述热词特征向量自注意力机制(self-attention based hotwordcontext)的计算公式为:
70、
71、
72、
73、
74、
75、
76、
77、
78、
79、
80、式中,为第i层提取到的音频特征向量,t为经过下采样后的特征序列长度,d为特征维度;和为自注意力层中将输入转换为查询向量的线性层所使用的权重和偏置,为查询向量;和为自注意力层中将输入转换为键向量的线性层所使用的权重和偏置,为键向量;和为自注意力层中将输入转换为值向量的线性层所使用的权重和偏置,为值向量;为候选热词组通过热词编码器编码得到的热词特征向量,其中为文本中真实存在的热词的数量,为随机构造的不存在于文本的伪热词数量,在不同的层中共享该矩阵,和自注意力层中将输入转换为热词键向量的线性层所使用的权重和偏置,为热词键向量;表示按顺序在时间维度上的拼接操作,为音频特征向量编码得到的键向量和热词键向量在时间维度上拼接得到的融合键向量,和自注意力层中将输入转换为热词值向量的线性层所使用的权重和偏置,表示按顺序在时间维度上的拼接操作为热词值向量;表示按顺序在时间维度上的拼接操作,为音频特征向量编码得到的值向量和热词值向量在时间维度上拼接得到的融合值向量,为转置时间维度和特征维度得到的矩阵,为特征维度大小的平方根,用于对注意力评分进行放缩降低方差大小,为注意力评分,为注意力评分使用进行归一化处理得到的注意力分布矩阵,为注意力机制的计算结果。
81、在用户使用过程中,可以主动指定多个热词,初始化语音识别引擎时将会使用热词编码模型对热词进行编码得到热词特征向量序列。在用户使用过程中,该热词特征序列将会作为模型输入与用户每次输入的声学特征进行拼接并进行解码。用户调用s2步骤中训练好的热词编码模型对输入的热词进行编码,并调用s3步骤中训练好的语音识别模型对音频进行解码,在该过程中首先使用ctc束解码机制获取k个评分最高的序列,之后使用decoder进行二次重打分,最后根据选择综合评分最高的序列作为最终的识别结果。
82、与现有技术相比,本发明的有益效果体现在:使用预训练的方式训练热词编码模型,不需要额外采集大量的文本数据和额外的音频-文本对数据,有效降低了训练成本。同时在训练过程中即将热词信息与音频特征融合,由模型自动学习热词识别的能力,不需要依赖专家知识设计额外的解码逻辑,可以快速应用于不同领域不同语种,在提高模型识别准确率的同时极大降低了设计成本。
83、本发明通过使用大量文本以decoder-only的方式对模型进行预训练,可以以近似无监督的方式使模型学习到大量文本之间的知识,克服数据量不足导致的性能不佳的问题。
84、本发明通过特征编码器对词向量序列进行编码和特征提取,可以将任意长度的热词转换为固定大小的热词特征向量,通过特征编码器对该热词特征向量进行解码拟合,可以在降低维度的同时使热词特征向量包含该热词的语言学信息。
85、本发明将在注意力机制计算过程中得到的候选热词向量特征与语音识别模型声学特征进行拼接,语音识别模型在编码过程中使用基于热词特征向量自注意力机制将热词信息与声学特征信息融合,得到编码向量并作为最终的解码器输入,使得热词信息与声学模型信息联系更紧密,得到对热词识别准确率更好的语音识别模型。该模型训练过程中,不需要特别标注的热词文本,仅需要从音频-文本对中随机抽取部分热词即可进行模型训练,对训练数据要求低。在用户使用过程中,不需要再进行额外的模型微调或者训练工作,仅使用热词编码模型对用户指定热词进行编码即可,有效降低了模型训练和实际应用的难度。
86、本发明通过随机构建候选热词组,拟合用户在使用过程中待识别目标中不一定包含全部热词的情况。将候选热词组编码为热词特征向量,在注意力机制计算过程中即与音频特征进行融合,不需要手动设计额外的解码逻辑,因此识别率和准确度均可以得到明显提升,可以有效应用于不同领域。
本文地址:https://www.jishuxx.com/zhuanli/20240618/21187.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表