基于音频处理优化唇形迁移效果的驱动方法和系统与流程
- 国知局
- 2024-06-21 10:44:07
本发明属于数字人视频的,具体涉及一种基于音频处理优化唇形迁移效果的驱动方法和系统。
背景技术:
1、随着数字人合成技术的发展以及元宇宙概念的繁荣,虚拟主播、视频客服、大屏互动数字人逐渐成为新兴业务形态。产品形态不断扩充的同时,人们对虚拟数字形象的真实度有了更高的要求,其中,虚拟形象的嘴型能否与播报的文字完美对应,虚拟形象嘴型效果是否符合真人说话习惯,也成为虚拟数字形象合成效果的直观衡量标准。
2、目前主流的唇形迁移算法,存在两类问题,1.在输入静音片段用做驱动音频,或是驱动音频中出现长的静音停顿时,无法对原始唇形做静默状态拟合,会使得唇形展示出形象素材原本的唇形效果;2.在非静音片段驱动下,针对唇形合成效果的优化,目前已知的是采用大量中文人脸嘴型对照数据对唇形迁移模型做进一步的训练,使训练后的模型更贴合中文发音习惯,但训练速度慢,对训练样本的处理要求高,受样本语速、唇形大小等不同因素影响,训练结果导向未知,训练调参对普通应用的门槛过高,不适用于广泛的迅速提升唇形贴合效果的需求。
技术实现思路
1、本发明的目的在于克服现有技术中的不足,提供一种基于音频处理优化唇形迁移效果的驱动方法和系统,能够将静音片段进行流畅拟合处理,降低重训练的时间与试错成本,更方便简单地对现有产品中唇形的逼真需求进行应急式满足。
2、本发明提供了如下的技术方案:
3、第一方面,提供了一种基于音频处理优化唇形迁移效果的驱动方法,包括:
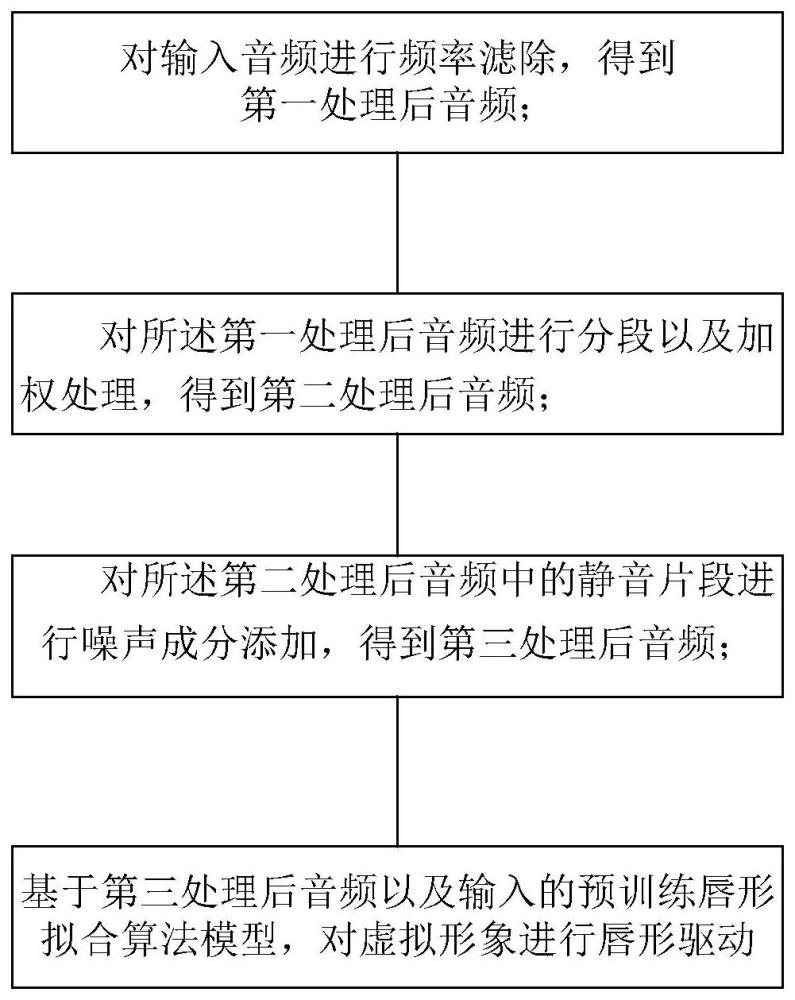
4、对输入音频进行频率滤除,得到第一处理后音频;
5、对所述第一处理后音频进行分段以及加权处理,得到第二处理后音频;
6、对所述第二处理后音频中的静音片段进行噪声成分添加,得到第三处理后音频;
7、基于第三处理后音频以及输入的预训练唇形拟合算法模型,对虚拟形象进行唇形驱动。
8、优选地,所述对输入音频进行频率滤除包括:在输入音频的音频频谱分布图中,去除超低频和超高频的频谱宽度;所述超低频频谱宽度范围为以最小值开始计量的10%频谱总宽度;所述超高频频谱宽度范围为以最大值开始计量的15%频谱总宽度。
9、优选地,在对所述输入音频进行频率滤除前,对输入音频进行采样频率的调整。
10、优选地,所述对第一处理后音频进行分段以及加权处理,包括:
11、以设定的频率区间为单位对第一处理后音频的频谱进行分段,并对分段后的音频依据音频的能量谱系,进行权重拟合;
12、所述进行权重拟合包括:
13、确定每一单位频谱的能量;
14、对确定的所述每一单位频谱的能量进行求和,得到所有单位频谱的总能量;
15、基于确定的所述每一单位频谱的能量和得到的所述所有单位频谱的总能量,确定每一单位频谱的能量权重值;
16、基于确定的权重值,对每一单位频谱的能量进行加权处理。
17、优选地,任一单位频谱的能量为:
18、
19、其中,ei表示第i单位频谱的能量,ρ表示介质密度,ν表示声波速度,a表示第i单位频谱的声波振幅;
20、v=λf
21、其中,v表示声波速度,λ表示波长,f表示声音频率;
22、所述所有单位频谱的总能量e为:
23、
24、其中,ei表示第i单位频谱的能量,n表示为第一处理后音频分段后的段数;
25、所述确定每一单位频谱的能量权重值,包括:
26、
27、其中,wi表示第i单位频谱的权重,ei表示第i单位频谱的能量,e表示所有单位频谱的总能量。
28、优选地,所述噪声成分添加包括:对所述第二处理后音频进行检测,并标记出所有时长超过设定时长且波幅为0的静音片段;采用白噪声音频对标记出的静音片段进行底噪添加。
29、优选地,所述对虚拟形象进行唇形驱动,包括:获取虚拟形象视频文件,截取其中一帧进行人脸检测,并判断是否检测到人脸五官;如果检测到人脸五官,则输出当前帧对应图片中关于人脸五官关键特征点构成的特征向量;如果没有检测到人脸五官,则终止唇形驱动;
30、利用输出的所述特征向量和获取的第三处理后音频,调用预训练的唇形拟合算法模型,对虚拟形象视频的所有帧进行面部向量修改。
31、第二方面,提供了一种基于音频处理优化唇形迁移效果的驱动系统,包括:
32、第一处理单元,用于对输入音频进行频率滤除,得到第一处理后音频,以及对所述第一处理后音频进行分段以及加权处理,得到第二处理后音频;
33、第二处理单元,用于对所述第二处理后音频中的静音片段进行噪声成分添加,得到第三处理后音频;
34、第三处理单元,用于基于所述第三处理后音频以及输入的预训练唇形拟合算法模型,对虚拟形象进行唇形驱动。
35、优选地,第一处理单元内还包括调整模块,用于对输入音频进行采样频率的调整;所述第一处理单元还包括第一处理模块、第二处理模块和第三输出模块;第一处理模块,用于以设定的频率区间为单位对第一处理后音频的频谱进行分段;第二处理模块,用于对第一处理模块处理后的音频依据音频的能量谱系,进行权重拟合;第三输出模块,用于将第二处理模块处理后的音频输出,得到第二处理后音频;所述第二处理模块包括第一子计算模块、第二子计算模块和第三子计算模块:第一子计算模块,用于确定每一单位频谱的能量;任一单位频谱的能量为:
36、
37、其中,ei表示第i单位频谱的能量,ρ表示介质密度,ν表示声波速度,a表示第i单位频谱的声波振幅;
38、v=λf
39、其中,v表示声波速度,λ表示波长,f表示声音频率;
40、第二子计算模块,用于对确定的所述每一单位频谱的能量进行求和,得到所有单位频谱的总能量;所述所有单位频谱的总能量e为:
41、
42、其中,ei表示第i单位频谱的能量,n表示为第一处理后音频分段后的段数;
43、第三子计算模块,用于基于确定的所述每一单位频谱的能量和得到的所述所有单位频谱的总能量,确定每一单位频谱的能量权重值;以及基于确定的权重值,对每一单位频谱的能量进行加权处理;
44、所述确定每一单位频谱的能量权重值,包括:
45、
46、其中,wi表示第i单位频谱的权重,ei表示第i单位频谱的能量,e表示所有单位频谱的总能量。
47、优选地,所述第二处理单元包括:标记模块,用于对所述第二处理后音频进行检测,并标记出所有时长超过设定时长且波幅为0的静音片段;融合输出模块,用于采用白噪声音频对标记模块标记出的静音片段进行底噪添加,以及输出第三处理后音频;所述第三处理单元包括:判断模块,用于获取虚拟形象视频文件,截取其中一帧进行人脸检测,并判断是否检测到人脸五官;如果检测到人脸五官,则输出当前帧对应图片中关于人脸五官关键特征点构成的特征向量;如果没有检测到人脸五官,则终止唇形驱动;驱动模块:用于利用输出的所述特征向量和获取的第三处理后音频,调用预训练的唇形拟合算法模型,对虚拟形象视频的所有帧进行面部向量修改。
48、与现有技术相比,本发明的有益效果是:
49、采用对输入音频的处理,从而能够补偿现有唇形迁移模型对真人中文唇形拟合度不够高的问题,实现了快速迭代现有数字人产品,优化数字人合成真实度的目标,能够方便简单地对现有产品中唇形的逼真需求进行应急式满足;对静音片段进行噪声添加,解决了静音片段中,唇形迁移模型不会对原始嘴型做任何处理的问题,使原始虚拟人视频不再拘泥于静默视频,增强了唇形迁移模型的适配性;对输入音频进行频率滤除、加权处理,从而对频率能量分布做到柔性均衡,使不同频率的音频对唇形的影响达到平稳过渡,得到了对于当前唇形迁移模型最佳的驱动音频,解决了基础模型驱动唇形与真人相差过大,嘴唇张不开且嘴唇变化过快的问题。
本文地址:https://www.jishuxx.com/zhuanli/20240618/21415.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表