一种基于局部和全局跨通道融合的声纹识别方法
- 国知局
- 2024-06-21 10:44:25
本发明涉及数字信号处理和语音识别,尤其涉及一种基于局部和全局跨通道融合的声纹识别方法。
背景技术:
1、随着信息技术的不断发展,指纹、虹膜和人脸等生物识别技术在近年来逐渐融入我们的生活,改变了我们的日常。与此同时,声纹识别作为另一种生物识别技术,通过分析和识别人的声音来验证身份,也逐渐引起人们的关注。声纹识别技术广泛应用于刑侦破案、罪犯追踪、国防监控、证券和银行交易、公安取证、个人电脑和汽车的声控锁、语音助手唤醒,身份证和信用卡识别等多个领域。局部和全局跨通道融合的声纹识别用于语音助手唤醒、身份证和信用卡识别等场景。当下,硬件技术的突破带来了更多更快的计算资源,资源丰富也不能铺张浪费,为了利用少的资源并且实现更快的运算处理速度,局部和全局这种多路设计显得尤为重要。局部和全局设计目标是在保持测试准确率的情况下,通过并行运算加快运算速度。当然为了进一步提高准确率,跨通道融合也相当必要,跨通道融合的设计是在增加极少量的浮点运算(可忽略不计),局部和全局分别融合对方的生成的信息,增加测试的准确率。当前,国内外声纹识别领域大多注重准确性,因此设计这些模型时,网络的深度较深,使得模型训练时间过长。主流的模型有tdnn、resnet、x-vector、ecapa-tdnn。
技术实现思路
1、本发明的目的是克服背景技术中存在的上述缺陷,提供一种基于局部和全局跨通道融合的声纹识别方法,在加快模型运算速度的同时,在增加可忽略不计的浮点运算的基础上提高准确率。
2、本发明为解决上述技术问题采用以下技术方案:
3、一种基于局部和全局跨通道融合的声纹识别方法,包括:
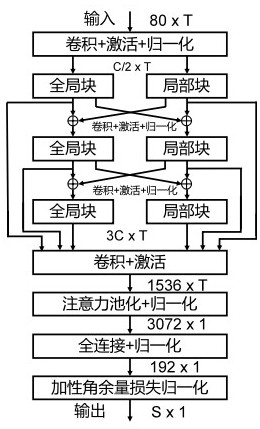
4、通过神经网络模型提取音频的特征,输出的特征向量是对应说话人的身份id的语音片段特征,将语音片段特征进行存储,以便后续的音频检索;所述神经网络模型,包含两个卷积层、三个全局块和三个局部块、注意力池化层、全连接层、加性角余量损失归一化层;所述全局块和局部块是典型的残差结构,所述残差结构用来进行跨尺度信息提取;全局块和局部块通过跨通道进行连接;所述注意力池化层将所述全局块和局部块的信息进行拼接提取特征,经过全连接层和加性角余量损失归一化层用于后续的声纹识别。
5、进一步的,所述方法具体包含以下步骤:
6、步骤a:首先对单通道的音频文件进行预处理,得到梅尔频谱数据,并使用频谱增强,得到最后的频谱数据,具体包括:
7、根据预设的批量大小,获取此批量大小的单通道的音频文件信息,对于所得到的音频数据,加入混响和噪声,得到新的音频数据,按照预设的时间间隔对语音信号数据进行采样处理,将其转换为一维的语音信号;对一维语音信号滑动加窗,从而实现分帧;设置帧长25ms,帧移10ms,以保证帧内信号的平稳性,并使帧之间有交叠;接着对每一帧做快速傅立叶变换,并计算功率谱;对功率谱应用梅尔滤波器组,获取每个滤波器内的对数能量作为系数,得到频谱数据;对得到的频谱数据进行频谱增强,得到最后的频谱数据;
8、步骤b:结合卷积层、全局块、局部块、跨通道融合、注意力池化层,基于频谱数据对模型进行训练,得到训练后的声纹识别模型,具体步骤如下:
9、步骤b1:首先数据进入卷积层得到特征数据,第一层设计的输入通道是80,输出通道是512,卷积核大小为5,填充的方式是相同模式;对于特征数据进行批量归一化和relu激活,得到处理后的特征数据;
10、步骤b2:将输出的512个通道对半划分,作为全局块和局部块输入通道个数;将数据分别输入到全局层和局部层;在全局层中对数据进行一维卷积,将通道数放大到原来的2倍;再进行归一化和激活操作;卷积默认加上归一化和激活操作;接着进入残差结构,将输入划分为8个组,第一组就是直接当作输出值;第二组开始,每组进行卷积操作,卷积核大小为3,将卷积后的结果复制两份,一部分作为输出,一部分用作下一组做信息融合;后面3~8组的操作相同;这八组计算完后,将八组的结果拼接在一起;最后再将拼接的结果经由一维卷积,将通道数还原为原来的大小;步骤b2能用下列公式表示:
11、,
12、其中,表示的是输入的数据,是一维卷积操作,是将划分为8份,是将输入的每个通道进行拼接,是最后的输出结果;
13、将输出的结果再经过全局块操作,也即全局通道注意力操作:
14、,
15、其中,表示的是输入的数据,是一维卷积操作,函数对输入进行指数化,然后进行归一化;为层归一化操作,对网络中每个样本的特征进行归一化;是修正线性单元用于提高网络训练精度;
16、局部块使用的是通道注意力操作:
17、,
18、其中,表示的是输入的数据,是一维卷积操作,表示的是全局平均池化;sigmoid函数是一种非线性激活函数,它的输出范围是[0,1];是修正线性单元用于提高网络训练精度;
19、步骤c:全局通道注意力块和通道注意力块操作完后得到的结果进行跨通道融合得到特征数据:
20、,
21、其中,分别是上面经过局部块和全局块得到的结果,是批量归一化,是修正线性单元用于提高网络训练精度;分别是局部块和全局块对于信息的提取结果,是通过相加的操作实现跨通道融合对应局部块和全局块的结果;局部块和全局块分别都有三层,除去对通道进行放缩的卷积的卷积核大小为1外,其他每一层卷积的卷积核大小都为3,除去放缩的通道数,每个块的通道数都是512;接着将三层的结果拼接在一起,经过一个卷积层,得到结果;
22、步骤d:基于注意力池化层,将特征数据赋予不同的权重,得到新的特征数据:
23、,
24、其中,表示的是上一层的输入,是一维卷积操作,是批量归一化,是修正线性单元用于提高网络训练精度;也是一个非线性的激活函数,它的输出范围是[-1, 1];函数对输入进行指数化,然后进行归一化;
25、步骤e:基于全连接层,对特征数据进行全连接处理,得到分布式特征:
26、,
27、其中,表示的是上一层的输出的结果,是批量归一化,是线性操作,用于将输入数据与权重矩阵相乘,并添加偏置向量,以生成输出;
28、步骤f:基于加性角余量损失归一化层,对分布式特征表示进行处理,得到音频数据嵌入码,以此得到训练后的模型;基于加性角余量损失归一化层的损失函数的表达式如下:
29、,
30、其中,表示第i个样本的深度特征,属于第类,表示全连接层权重的第j列,是偏置项;n和n分别代表批量大小和说话人的类别数;
31、步骤g:基于训练后的声纹识别模型进行声纹识别处理,得到最后比对结果;其具体步骤包括:
32、每次识别取两段语音数据,将待识别的语音数据输入到训练后的声纹识别模型中,获得每段音频所对应的语音数据嵌入码,根据语音数据嵌入提取的特征码计算它们的余弦相似度,并根据计算结果判断这两段音频是否来自同一个说话人,最终输出识别结果;其中余弦相似度的计算公式具体如下所示:
33、,
34、其中,表示第一段音频数据的第i个向量单位,表示第二段音频数据的第i个向量;n表示的是向量的维度。
35、本发明采用以上技术方案与现有技术相比,具有以下有益效果:
36、(1)本发明采用的并行的设计在没有加宽模型的宽度前提下,进一步加快了运算速度;
37、(2)本发明在声纹识别中具有较高的准确率和实时性,弥补了传统的声纹识别技术在准确性和运算速度方面存在的不足,在语音助手唤醒、身份证和信用卡识别等相关应用场景具有较大的应用潜力。
本文地址:https://www.jishuxx.com/zhuanli/20240618/21466.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。