语音情绪识别方法与流程
- 国知局
- 2024-06-21 11:28:16
本公开涉及情绪识别领域,具体地,涉及一种语音情绪识别方法,更具体地,涉及一种基于多重特征融合的语音情绪识别方法。
背景技术:
1、情绪能够表现出人的心理状态,并且可以从多方面进行判断,其中,言语中情绪的变化是比较明显的。例如,说话的语气、语调和语速等信息都可以透露出情绪的变化。因此,可以通过识别语音中的情绪来了解心理状态。
2、目前,现有的情绪识别研究通常通过提取语音的梅尔频谱特征来进行识别,但是单一的特征会导致模型提取的信息不足,无法有效拟合数据,导致模型泛化能力不足。另外,基于语音的情绪识别方法主要为循环模型和基于transformer的模型。在实际应用中,循环模型容易出现梯度消失问题,且训练效率低下;基于transformer的模型在目前设备上难以支持大量数据同时训练。
技术实现思路
1、本公开针对现有技术中存在的上述技术问题,提供了一种语音情绪识别方法和装置。
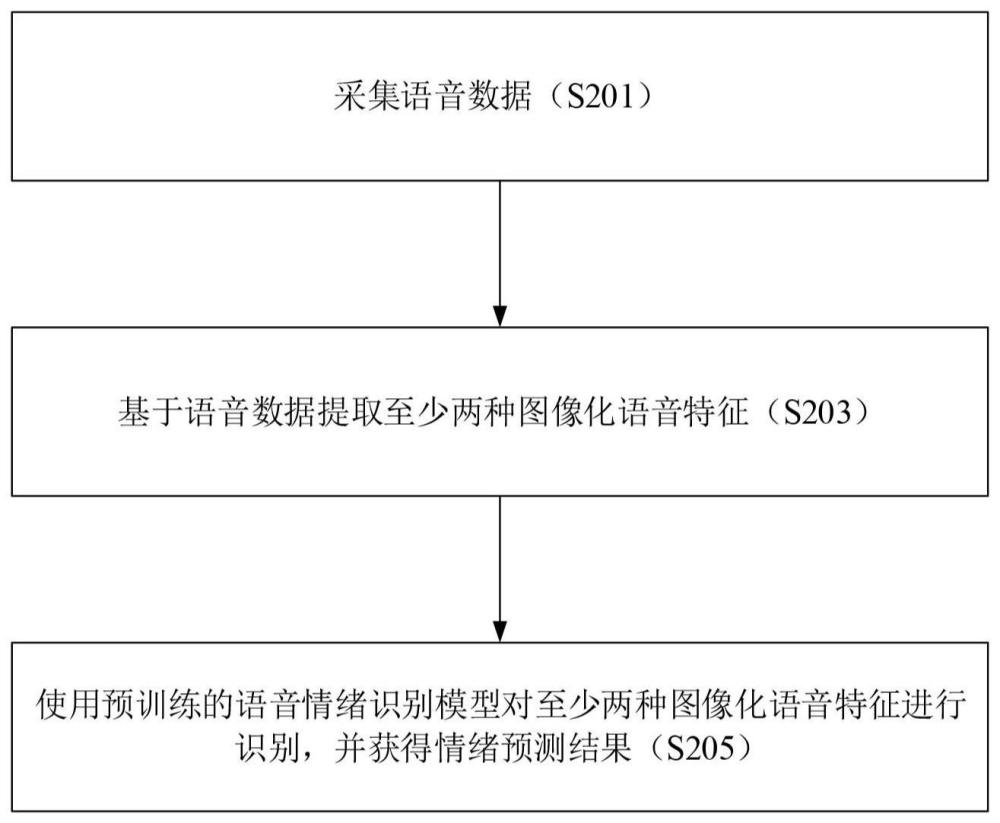
2、本公开提供了一种语音情绪识别方法,所述方法包括:采集语音数据;基于语音数据提取至少两种图像化语音特征;以及使用预训练的语音情绪识别模型对至少两种图像化语音特征进行识别,并获得情绪预测结果,其中,所述语音情绪识别模型包括:卷积层,被配置为以至少两种图像化语音特征作为输入提取全局特征信息;注意力层,被配置基于全局特征信息根据局部-全局广播注意力或移动视觉变换器注意力并且还根据通道注意力、空间注意力和深层注意力来提取注意力特征;以及输出层,被配置为根据所述注意力特征确定所述情绪预测结果。
3、根据本公开的示例性实施例,所述至少两种图像化语音特征包括:梅尔频谱特征、短时傅里叶变换特征、梅尔倒谱系数特征、频谱对比度特征、频谱中心特征、平均过零率中的至少两种。
4、根据本公开的示例性实施例,所述卷积层包括:第一级,利用浅层网络分别从至少两种图像化语音特征提取图像化语音特征的局部特征信息,并对分别提取的局部特征信息进行特征融合;以及第二级,对已融合的局部特征信息进行多次下采样以获得全局特征信息。
5、根据本公开的示例性实施例,所述注意力层包括:第一分支,基于全局特征信息利用局部-全局广播注意力或移动视觉变换器注意力提取第一特征;第二分支,基于全局特征信息使用通道注意力提取通道特征,使用空间注意力提取空间特征,采用交叉融合的模式,将通道特征和空间特征融合以获得第二特征;以及第三分支,基于深层注意力提取第三特征,其中,所述注意力特征包括第一特征、第二特征和第三特征。
6、根据本公开的示例性实施例,第一特征、第二特征和第三特征分别由表示各个情绪标签的概率的向量来表示,根据所述注意力特征确定情绪预测结果,包括:将第一特征的向量、第二特征的向量和第三特征的向量相加或加权相加,并将相加结果中具有最大概率的情绪标签确定为情绪预测结果。
7、根据本公开的示例性实施例,情绪标签包括中性、高兴、悲伤、生气、恐惧、厌恶和惊讶。
8、根据本公开的示例性实施例,所述方法还包括通过以下步骤对所述语音情绪识别模型进行训练:采集训练样本;将训练样本转换为训练用图像化语音特征,训练用图像化语音特征包括:梅尔频谱特征、短时傅里叶变换特征、梅尔倒谱系数特征、频谱对比度特征、频谱中心特征、平均过零率中的至少两种;对训练用图像化语音特征进行数据增强以获得增强样本;以及根据训练用图像化语音特征和增强样本对语音情绪识别模型进行训练。
9、根据本公开的示例性实施例,对所述训练用图像化语音特征进行数据增强以获得增强样本,包括:通过裁剪、缩放、添加噪声、添加遮挡中的至少一种对训练用图像化语音特征进行数据增强以获得增强样本。
10、根据本公开的另一方面,提供了一种存储指令的计算机可读存储介质,其特征在于,当所述指令被至少一个计算装置运行时,促使所述至少一个计算装置执行如上所述的语音情绪识别方法。
11、根据本公开的另一方面,提供了一种包括至少一个计算装置和至少一个存储指令的存储装置的系统,其特征在于,所述指令在被所述至少一个计算装置运行时,促使所述至少一个计算装置执行如上所述的语音情绪识别方法。
12、通过应用根据本公开的示例性实施例的语音情绪识别方法、系统、可读存储介质,通过使用梅尔频谱特征、短时傅里叶变换特征、梅尔倒谱系数特征、频谱对比度特征、频谱中心特征、平均过零率中的至少两种特征避免了单一的特征会导致的模型提取的信息不足无法有效拟合的问题。另一方面,通过采用来源于light-visiontransformer中的轻量化自注意力机制,将卷积与注意力机制相结合,提出了一个训练成本低、且融合多种轻量化注意力模块的模型,以达到提升模型泛化能力、提升模型训练效率并可以同时训练大量数据的目的。
技术特征:1.一种语音情绪识别方法,其特征在于,包括:
2.根据权利要求1所述的方法,其特征在于,所述至少两种图像化语音特征包括:梅尔频谱特征、短时傅里叶变换特征、梅尔倒谱系数特征、频谱对比度特征、频谱中心特征、平均过零率中的至少两种。
3.根据权利要求1所述的方法,其特征在于,所述卷积层包括:
4.根据权利要求1所述的方法,其特征在于,所述注意力层包括:
5.根据权利要求4所述的方法,其特征在于,所述第一特征、所述第二特征和所述第三特征分别由表示各个情绪标签的概率的向量来表示,
6.根据权利要求5所述的方法,其特征在于,所述情绪标签包括中性、高兴、悲伤、生气、恐惧、厌恶和惊讶的标签。
7.根据权利要求1所述的方法,其特征在于,还包括:通过以下步骤对所述语音情绪识别模型进行训练:
8.根据权利要求7所述的方法,其特征在于,对所述训练用图像化语音特征进行数据增强以获得增强样本,包括:通过裁剪、缩放、添加噪声、添加遮挡中的至少一种对所述训练用图像化语音特征进行数据增强以获得所述增强样本。
9.一种存储指令的计算机可读存储介质,其特征在于,当所述指令被至少一个计算装置运行时,促使所述至少一个计算装置执行如权利要求1至8中的任一权利要求所述的语音情绪识别方法。
10.一种包括至少一个计算装置和至少一个存储指令的存储装置的系统,其特征在于,所述指令在被所述至少一个计算装置运行时,促使所述至少一个计算装置执行如权利要求1至8中的任一权利要求所述的语音情绪识别方法。
技术总结公开了一种语音情绪识别方法,所述方法包括:采集语音数据;基于语音数据提取至少两种图像化语音特征;以及使用预训练的语音情绪识别模型对至少两种图像化语音特征进行识别,并获得情绪预测结果,其中,所述语音情绪识别模型包括:卷积层,被配置为以至少两种图像化语音特征作为输入提取全局特征信息;注意力层,被配置基于全局特征信息根据局部‑全局广播注意力或移动视觉变换器注意力并且还根据通道注意力、空间注意力、深层注意力提取注意力特征;以及输出层,被配置为根据注意力特征确定情绪预测结果。技术研发人员:陈宪语,童心,贺佳琦,李永春,潘瑶,苗秀丽,魏宏超,周丹,蒲岩受保护的技术使用者:沈阳康慧类脑智能协同创新中心有限公司技术研发日:技术公布日:2024/2/19本文地址:https://www.jishuxx.com/zhuanli/20240618/21704.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表