一种基于最优运输方法的跨模态表示方法
- 国知局
- 2024-06-21 11:36:15
本发明涉及语音翻译方法,具体涉及一种基于最优运输方法的跨模态表示方法。
背景技术:
1、语音到文本的翻译(speech-to-text translation,s2tt)是指将口头语音信号转换为文本形式的技术。在这个领域,得益于深度学习和其他先进的语音处理技术,已经取得了显著的进展,有效地降低了不同语言使用者之间的沟通障碍。
2、语音翻译一般是由语音识别和文本翻译两部分级联构成,如图1所示,其先通过语音识别模型(automatic speech recognition,asr)来对语音进行转录,然后通过文本翻译模型(machine translation,mt)对转录文本进行翻译,得到目标文本例如“谢谢”。
3、但是级联语音翻译存在错误传播、翻译效率低和语音中的副语言信息丢失等问题。为了解决这个缺陷提出了端到端语音翻译,简单来说,就是通过单个模型,完成源语音到目标文本的转换,如图2所示,其直接通过s2t模型将源语音转换为目标文本例如“谢谢”。
4、与传统的级联方法相比,端到端的语音翻译可以避免错误传播和高延迟的缺点。但是端到端的语音翻译所需的语料相对有限,使得从源语音到目标文本的准确映射学习变得相当复杂。为此,研究者们通常采用多任务学习方法,通过引入文本翻译任务,学习其中的知识来辅助语音翻译的训练,如图3所示(ye r,wang m,li l.end-to-end speechtranslation via cross-modal progressive training[j].arxiv preprint arxiv:2104.10380,2021.)。
5、然而,由于语音和文本之间存在模态差异,这导致了语音翻译性能通常落后于机器翻译任务。一些研究已经注意到了模态差异的问题,从神经科学的角度设计了一个固定大小的语义记忆模块来弥补这一差距。然而,这种方法实际上牺牲了文本翻译的效果。因此学习语义的语音和文本的相似表示对于语音翻译非常重要。
技术实现思路
1、本发明针对现有语音翻译方法存在的问题,提出了一种基于最优运输方法的跨模态表示方法。
2、本发明为解决技术问题所采用的技术方案如下:
3、本发明的一种基于最优运输方法的跨模态表示方法,主要包括以下步骤:
4、步骤一、构建多任务通用框架的最优运输模型;
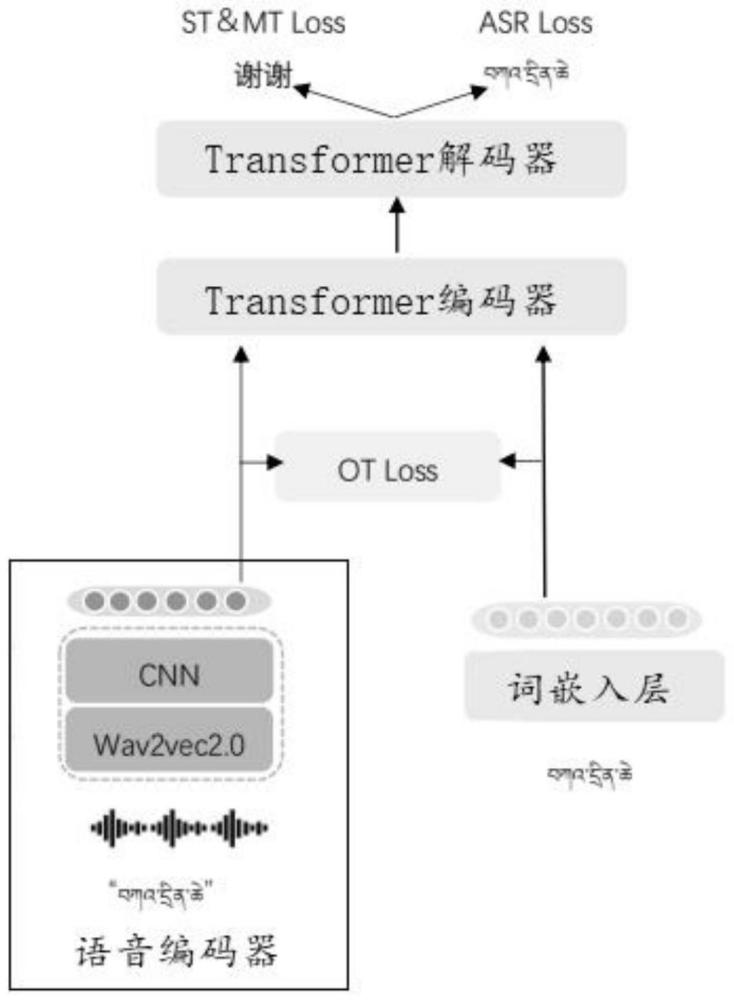
5、所述最优运输模型由语音编码器、词嵌入层、transformer编码器和transformer解码器组成,所述词嵌入层与语音编码器并行设置,所述语音编码器和词嵌入层都连接到所述transformer编码器,所述transformer编码器连接到所述transformer解码器;
6、步骤二、采用最优运输方法实现跨模态表示;
7、s2.1:定义离散概率分布;
8、设α为离散概率分布,它由在位置处的质量a1,…,ai,…,an表示,其中a1+…ai…+an=1,ai表示位置ui处的质量;所述离散概率分布α等于以质量ai为概率和对应位置ui的狄拉克δ函数值乘积的累加和,其计算公式如下:
9、
10、把所述离散概率分布α中的质量运输到离散概率分布β,形成一个由在新位置处的质量b1,…,bi,…,bm表示的新离散概率分布β,其中b1+…bi…+bm=1;
11、s2.2:利用最优运输模型找到运输成本最低的运输计划;
12、设z*为运输成本最低的运输计划,其计算公式如下:
13、
14、其中,1m表示元素都为1的m维向量,1n表示元素都为1的n维向量,a=(a1,…a,an)表示离散概率分布α中的质量向量,b=(b1,…a,bm)表示离散概率分布β中的质量向量,z和c分别表示元素为zij和cij的n×m阶矩阵,cij=c(ui,vj);
15、s2.3:利用运输成本最低的运输计划找到两个离散概率分布之间的最优传输方案;
16、定义离散概率分布α和离散概率分布β之间的距离度量即wasserstein距离为w(α,β)=<c,z*>,即为在两个离散概率分布之间找到的最优传输方案,使传输后两个离散概率分布之间的距离最小;求解wasserstein距离的上界近似函数wλ(α,β),其计算公式如下:
17、
18、其中,为熵函数,将其作为正则化改善优化结果,λ>0为正则化权值,p(zij)表示从位置ui到位置vj传递zij个单位质量的概率;
19、s2.4:训练损失函数;
20、将计算获得的函数wλ(α,β)作为损失函数加入到训练损失函数中,计算模型训练的损失。
21、进一步的,所述语音编码器包括wav2vec2.0和两个卷积层,所述语音编码器的输入为在16khz上采样的原始波形信号;所述wav2vec2.0用于对输入的原始波形信号进行波形处理;所述两个卷积层用于缩小wav2vec2.0输出序列的时间维度。
22、进一步的,步骤s2.1中,假设单位质量从位置ui到位置vj的运输成本用c(ui,vj)表示,其中c:为成本函数,zij≥0表示从位置ui到位置vj所需要传递的质量,则位置ui到位置vj的运输成本表示为zij*c(ui,vj),从离散概率分布α到离散概率分布β的总质量运输成本为离散概率分布β从离散概率分布α的位置ui接收到的总质量为它等于在位置ui储存的质量,因此离散概率分布β的位置vj从离散概率分布α接收到的总质量为因此bj表示经过传递后离散概率分布β在位置vj的质量。
23、进一步的,步骤s2.3中,使用sinkhorn算法计算函数wλ(α,β)。
24、进一步的,步骤s2.4中,设u=(u1,…,ui,…,un)和v=(v1,…,vj,…,vm)分别为语音编码器和词嵌入层的输出序列,对于所有的位置ui和位置vj都有和假设两个离散概率分布α和β的隐藏维度相同且都等于d,定义离散概率分布α的质量均匀分布在位置(u1,…,un),离散概率分布β的质量均匀分布在位置(v1,…,vm)处,定义从位置ui到位置vj运输一个单位质量的代价为c(ui,vj)=||ui-vj||2,那么wasserstein距离可看作是语音编码器的输出序列u和词嵌入层的输出序列v之间的差距。
25、进一步的,步骤s2.4中,所述模型训练的损失为:其中和分别为在<s,y>、<s,x>和<x,y>对上的交叉熵损失,其公式分别如下:
26、
27、
28、
29、其中,<s,y>,<s,x>和<x,y>为语音翻译数据集所构建的数据对,表示wasserstein损失,λ>0为正则化权值。
30、进一步的,所述语音翻译数据集包含语音-转录-翻译三元组d={(s,x,y)},其中s=(s1,…,sn)为语音特征的输入序列,其对应的序列长度为n,x=(x1,…,xm)为源语言的转录本,其对应的序列长度为m,y=(y1,…,yk)为对应的目标的翻译文本,其对应的序列长度k。
31、本发明的有益效果是:
32、本发明提出的一种基于最优运输方法的跨模态表示方法,通过在输入端使用最优运输(optimal transport,ot)方法来减小音频和文本模式之间的表示差距,相较于现有技术,本发明具有以下优点:
33、1、模态差异缩小,最优运输(optimal transport,ot)方法有助于在模型输入端缩小语音和文本之间的模态差异,能够更准确地捕捉语音信号和文本之间的对应关系。
34、2、通过缩小模态差异并提高关联性,本发明的方法能够在语音翻译任务中实现更高的性能,这对于提高翻译准确性和整体任务表现是至关重要的。
35、3、由于本发明注重处理语音翻译模型输入模态之间的差异,这使得本发明的方法更适用于广泛的语音翻译任务,尤其是在标记数据有限的情况下,表现更为出色。
本文地址:https://www.jishuxx.com/zhuanli/20240618/22325.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表