基于领域对抗学习的多语言语音情感识别系统
- 国知局
- 2024-06-21 11:43:33
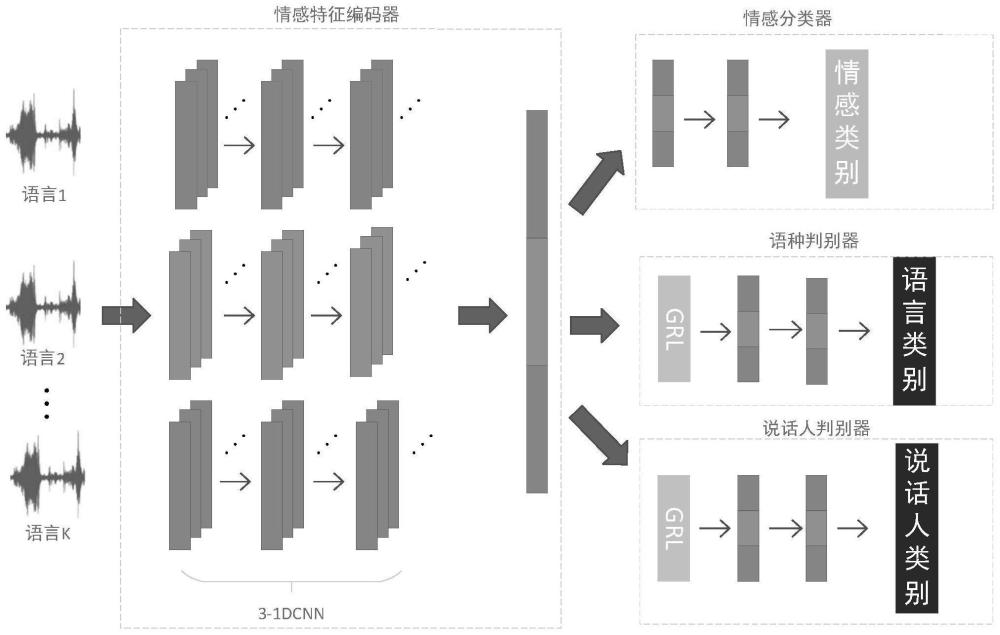
本发明属于人机交互领域,涉及一种基于领域对抗学习的多语言语音情感识别系统。
背景技术:
1、语音情感识别是人工智能领域中的一个重要分支,专注于从人类语音中识别情感和情绪状态,这一技术在多种应用场景中具有重要作用,例如在客户服务、健康监测、交互式娱乐和教育等方面。随着全球化的深入发展,跨语言的语音情感识别尤显重要,它涉及到处理和理解不同语言和文化背景下的语音情感表达。在情感语音识别网络方面的研究,一般用于语音识别的训练识别网络基本上都可以用于情感语音识别,如隐马尔科夫模型hmm(hidden markov model)、svm等。hmm与svm分别是基于概率统计理论和机器学习的分类方法,可归于信号处理的分类模型,基本未涉及人类的认知过程。而情感的识别是一个抽象、模糊、复杂的过程,无法简简单单的通过信号处理的方法来认知。人工神经网络(artificial neural network,ann)是一种模拟生物神经元的分类网络,拥有自主学习能力,在一定程度上反映了人脑的基本特性,但是这种方法网络结构难以确定,容易使网络过学习,从而陷入局部最优。因此有研究者尝试使用深度学习网络(deep neural network,dnn)去提取更抽象的深度特征,用于情感分类。还有像循环神经网络(recurrent neuralnetwork,rnn)、长短时记忆网络(long short term memorv network,lstm)等具备记忆功能,适合处理时序数据的网络结构,也能很好地应用于数据分类,但这些都只适用于单种语言的情感分类。在过去的几十年中,语音情感识别技术主要集中在单一语言上,不同语言在表达情感时有着不同的声学特征和语言习惯,这导致了模型在一种语言上训练得到的知识不能直接应用于另一种语言。
技术实现思路
1、有鉴于此,本发明的目的在于提供一种基于领域对抗学习的多语言语音情感识别系统,通过不同语种之间以及不同说话人之间的领域对抗学习消除不同语言之间的差异,有效提高语音情感识别模型的泛化能力。
2、为达到上述目的,本发明提供如下技术方案:
3、一种基于领域对抗学习的多语言语音情感识别系统,该系统包括情感特征编码器、情感分类器、语种判别器和说话人判别器。其中情感特征编码器基于卷积神经网络,用于学习并提取跨语言共享的情感特征;情感分类器根据情感特征识别出输入语音的情感状态;语种判别器和说话人判别器均基于领域对抗神经网络进行不同语种以及不同说话人的识别,以情感特征为输入,输出输入语音所属的语种和对应的说话人,通过不同语种之间以及不同说话人之间的领域对抗学习消除不同语言之间的差异,有效提高模型的泛化能力。
4、可选地,情感特征编码器包括三个编码模块,每个编码模块均包括最大池化层、批处理归一化层和卷积层,输入数据先经过一个卷积层后到达最大池化层,再依次经过卷积层、批处理归一化层、卷积层、最大池化层、批处理归一化层和卷积层后输出。
5、可选地,情感分类器包括两个全连接层和softmax层,每个全连接层都需要经过relu函数;在每个全连接层后均设有一dropout层;最后一个dropout层的输出进入softmax层进行情感分类。输出的情感分类预测如下式所示:
6、p(y|x)=softmax(c(e(x),θc))
7、式中,y表示情感类别,p(y|x)表示给定输入x下,预测为类别y的概率,θc表示分类器的参数,e(x)表示提取的情感特征。
8、可选地,语种判别器和说话人判别器均包括grl层、全连接层、随机失活层和输出层;其中随机失活层设置在全连接层后。输入数据依次经过grl层、全连接层、随机失活层、全连接层和随机失活层后进入输出层中。
9、其中,语种预测如下式所示:
10、p(lang|x)=softmax(d(e(x),θd))
11、式中,lang表示语种,θd为语种判别器的参数;
12、说话人预测如下式所示:
13、p(speak|x)=softmax(s(e(x),θs))
14、式中,speak表示说话人,θs表示说话人判别器的参数。
15、可选地,该系统的损失函数l包括情感分类损失lemo、语种判别损失llang和说话人判别损失lspeak,如下式所示:
16、l=lemo-λ(llang+lspeak)
17、式中,λ为权重参数。
18、本发明的有益效果在于:本发明可消除不同语言的数据分布差异,具有较好的情感显著特征的提取能力,能够在不同语言和文化背景下有效识别和分析人类语音中的情感表达。本发明可克服现有语音情感识别技术在处理多语言环境时面临的挑战,特别是在处理具有不同语音特征和情感表达习惯的语言时的限制。
19、本发明的其他优点、目标和特征在某种程度上将在随后的说明书中进行阐述,并且在某种程度上,基于对下文的考察研究对本领域技术人员而言将是显而易见的,或者可以从本发明的实践中得到教导。本发明的目标和其他优点可以通过下面的说明书来实现和获得。
技术特征:1.一种基于领域对抗学习的多语言语音情感识别系统,其特征在于:该系统包括情感特征编码器、情感分类器、语种判别器和说话人判别器;所述情感特征编码器用于学习并提取跨语言共享的情感特征;所述情感分类器根据所述情感特征识别出输入语音的情感状态;所述语种判别器和说话人判别器均基于领域对抗神经网络进行不同语种以及不同说话人的识别,以所述情感特征为输入,输出输入语音所属的语种和对应的说话人。
2.根据权利要求1所述的多语言语音情感识别系统,其特征在于:所述情感特征编码器包括三个编码模块,每个编码模块均包括最大池化层、批处理归一化层和卷积层,输入数据先经过一个卷积层后到达最大池化层,再依次经过卷积层、批处理归一化层、卷积层、最大池化层、批处理归一化层和卷积层后输出。
3.根据权利要求1所述的多语言语音情感识别系统,其特征在于:所述情感分类器包括两个全连接层和softmax层,每个全连接层都需要经过relu函数;在每个全连接层后均设有一dropout层;最后一个dropout层的输出进入softmax层进行情感分类。
4.根据权利要求1所述的多语言语音情感识别系统,其特征在于:所述语种判别器和说话人判别器均包括grl层、全连接层、随机失活层和输出层;所述随机失活层设置在所述全连接层后;输入数据依次经过grl层、全连接层、随机失活层、全连接层和随机失活层后进入所述输出层中。
5.根据权利要求1、3或4中任一项所述的多语言语音情感识别系统,其特征在于:该系统的损失函数l包括情感分类损失lemo、语种判别损失llang和说话人判别损失lspeak,如下式所示:
技术总结本发明涉及一种基于领域对抗学习的多语言语音情感识别系统,属于人机交互领域。该系统包括情感特征编码器、情感分类器、语种判别器和说话人判别器。其中情感特征编码器基于卷积神经网络,用于学习并提取跨语言共享的情感特征;情感分类器根据情感特征识别出输入语音的情感状态;语种判别器和说话人判别器均基于领域对抗神经网络进行不同语种以及不同说话人的识别,以情感特征为输入,输出输入语音所述的语种和对应的说话人。本发明可消除不同语言的数据分布差异,具有较好的情感显著特征的提取能力,能够在不同语言和文化背景下有效识别和分析人类语音中的情感表达。技术研发人员:胡敏,李敏,黄宏程受保护的技术使用者:重庆邮电大学技术研发日:技术公布日:2024/4/17本文地址:https://www.jishuxx.com/zhuanli/20240618/23145.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表