一种基于实体替换的语音数据增强方法与流程
- 国知局
- 2024-06-21 11:44:42
本发明涉及一种语音数据增强方法,特别是一种基于实体替换的语音数据增强方法。
背景技术:
1、随着航班量日益增长,对空中交通管理的安全和效率提出了更高的要求。民航业的快速发展给管制员带来了更大的工作量,增加了管制员的工作负荷。由于业务繁忙、管制工作重,管制员的失误会造成严重的安全隐患。在空中交通管理中引入更高水平自动化的最大障碍之一是管制员使用语音无线电通信向飞行员传达管制指令。如何将管制语音中的信息接入自动化系统,以提升自动化系统对信息的感知能力、如何使系统能自动理解管制指令的实际意义并实现冲突检测成为需要解决的技术难点。
2、为了提高语音识别算法的准确性,关键的挑战之一便是采集并标注足够的训练数据。这个挑战会导致训练的语音识别模型要么很容易过拟合,要么很难去处理那些模型在训练集中从来没有见过的数据。为解决上述问题,一般采用语音数据增强的方法增加语音识别模型的训练样本规模。语音识别训练数据主要包含训练音频以及对应的标注文本。传统方法主要通过修改语音数据的音量、语速、音调等音频底层特征,并与原先的标注文本配对形成新的训练数据。该方法不会增加新的标注文本,无法增加文本多样性,具有很大缺陷。
技术实现思路
1、发明目的:本发明所要解决的技术问题是针对现有技术的不足,提供一种基于实体替换的语音数据增强方法。
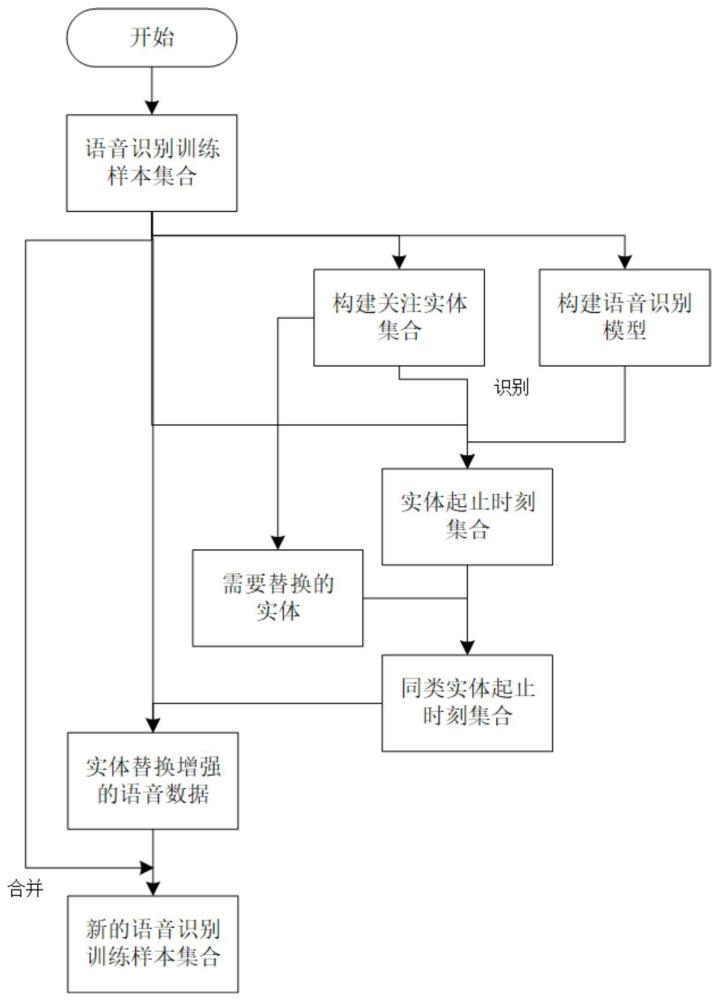
2、为了解决上述技术问题,本发明公开了一种基于实体替换的语音数据增强方法,包括如下步骤:
3、步骤1:构建语音识别模型,获取语音样本并进行标注,得到带标注的语音;根据语音样本和标注构建关注实体集合;
4、步骤2:根据语音识别模型和关注实体集合,构建实体定位模型,用于寻找带标注语音中每个实体的起止时刻,输出全部起止时候集合;
5、步骤3:采用关注实体集合中同类实体替换文本中的实体,并根据起止时刻替换对应语音数据,形成新的带标注语音集合;
6、步骤4:将新的带标注语音集合与原先的带标注语音集合合并,形成新的语音识别训练样本集合。
7、进一步的,步骤1中所述的构建语音识别模型和关注实体集合,包含如下步骤:
8、步骤1-1:设计语音识别神经网络;
9、步骤1-2:采集语音样本集合,表示为训练集x如下:
10、x={x1,x2,...,xn}
11、其中,n为训练集中的样本总数,x1,x2,...,xn分别为训练集中的第1,2,...,n个语音样本即训练样本;
12、步骤1-3:对步骤1-2的语音样本集合进行人工标注,得到标注文本集合,表示为标注集y如下:
13、y={y1,y2,...,yn}
14、其中,y1,y2,...,yn分别语音样本x1,x2,...,xn对应的语音文字标注;
15、步骤1-4:使用训练集x和标注集y,训练步骤1-1中设计的语音识别神经网络,将训练数据作为输入序列,将语音识别神经网络的输出与标注集中的语音文字标注进行对比,并根据连接时序分类损失函数优化所述语音识别神经网络的参数,获得语音识别模型;
16、步骤1-5:使用分词工具对标注集y中所有的语音文字标注进行分词,对分词结果进行筛选,保留当前需要关注的词,作为关注实体,并对其进行分类,一共分为m类关注实体,形成关注实体集合e。
17、进一步的,步骤1-1中所述的语音识别神经网络,结构如下:
18、所述的语音识别神经网络由语音特征编码层和识别结果输出层组成,其中语音特征编码层包含3层卷积神经网络和12层transformer神经网络,识别结果输出层包含1层全连接神经网络,所述语音识别神经网络的输入为语音,输出为该语音对应的文本;
19、按照预设输出比例将输入的语音流转化成文本流。
20、进一步的,步骤2中所述的实体定位模型,包含如下步骤:
21、步骤2-1:从关注实体集合e中选择第k个实体ek;k的初始值为1;
22、步骤2-2:从训练集x选择第i条语音xi输入步骤1中构建的语音识别模型,其中i的初始值设为1,判断输出的第i条语音对应的文本中该实体ek是否出现,如果没有出现,则进行步骤2-3,否则进行步骤2-4;
23、步骤2-3:设定实体ek在文本中样本起止时刻集合sample_durationk,i为空集合,如果训练集x还有语音没有被检测,则重复执行步骤2-2,如果训练集x中每条语音都被检测,则将训练集中x所有与实体ek关联的起止时刻集合组成实体起止时刻集合entity_durationk,表示如下:
24、entity_durationk
25、={sample_durationk,1,sample_durationk,2,...,sample_durationk,n}
26、并判断关注实体集合e中所有t个实体是否均已检查过,如果没有则将k的值增加1,并重新执行步骤2-1,如果是则将所有实体起止时刻集合组成全部起止时候集合total_duration,表示如下:
27、total_duration={entity_duration1,entity_duration2,...,entity_durationt}
28、步骤2-4:设定实体ek在第i条语音对应的文本中第j次出现位置的第一个字对应的语音帧时刻减去预设时长为实体的开始时刻第j次出现位置的最后一个字对应的语音帧时刻加上预设时长为实体的结束时刻
29、步骤2-5:将实体ek在文本中所有实体的开始时刻和对应的结束时刻组成起止时刻,并将所有的起止时刻组成样本起止时刻集合sample_durationk,i,表示如下:
30、
31、其中,p表示起止时刻的数量;
32、步骤2-6:将i的值增加1,返回执行步骤2-2。
33、进一步的,步骤3中所述的形成新的带标注语音集合,包含如下步骤:
34、步骤3-1:从关注实体集合e选择第o个实体eo;
35、步骤3-2:根据实体eo所属类别,随机挑选一个同类实体设为ek;
36、步骤3-3,从全部起止时候集合total_duration中找到实体ek对应的实体起止时刻集合entity_durationk;
37、步骤3-4:从实体起止时刻集合entity_durationk中取出第i个样本起止时刻集合sample_durationk,i;
38、步骤3-5:如果该样本起止时刻集合sample_durationk,i为空,则执行步骤3-4,否则执行步骤3-6;
39、步骤3-6:从样本起止时刻集合sample_durationk,i中取出第j个起止时刻截取其间对应的音频片段wavdest;
40、步骤3-7:按照步骤3-3至步骤3-6的方法从实体eo的实体起止时刻集合entity_durationo中随机找一个包含实体eo的样本xs,即语音样本集合x中的第s个语音片段,将对应标注文本ys中的实体eo替换成实体ek得到新标注文本y′s,将语音片段xs对应的样本起止时刻集合sample_durationo,s中所有的音频片段用wavdest均衡化后替换,得到新语音样本x′s,x′s和y′s即为新语音样本及其对应的语音文字标注。
41、步骤3-8:重复步骤3-1到步骤3-7直到产生的新语音样本及其对应的语音文字标注的数量满足预设数量,将所有的新语音样本及其对应的语音文字标注,组成新的带标注语音集合输出。
42、进一步的,步骤3-7中所述的将xs对应的样本起止时刻集合sample_durationo,s中所有的音频片段用wavdest均衡化后替换,包含如下步骤:
43、步骤3-7-1:计算样本xs和音频片段wavdest的均方根能量分别为rmss和rmsdest;
44、步骤3-7-2:计算均方根能量差值得到音频片段能量增益rmsgain,如下:
45、rmsgain=rmss-rmsdest
46、步骤3-7-3:根据能量增益调整音频片段wavdest的音量大小,使之与语音片段xs一致,方法如下:
47、
48、其中,wavdest′表示能量均衡后的音频片段波形;
49、步骤3-7-4:只用wavdest′替换语音片段xs对应的样本起止时刻集合sample_durationo,s中所有的音频片段。
50、进一步的,步骤3-7-1中所述的计算音频的均方根能量,具体如下:
51、
52、其中,xs,n表示样本xs第n个音频采样点的波形值,l表示样本xs的采样点个数。
53、进一步的,步骤1-1中所述的预设输出比例,即按照每50ms音频输出一个文字的比例将音频流转化成文字流。
54、进一步的,步骤2-4中所述的预设时长为20ms。
55、进一步的,步骤1-5中所述的筛选和分类,为人工筛选和人工分类。
56、有益效果:
57、1、本发明构建关注实体集合,用于对当前语音数据所处领域的专有名词进行建模,通过人工筛选分类的手段挖掘标注文本中包含的语义信息。
58、2、本发明构建基于实体替换的语音数据增强方法,采用同类实体替换的方式增加新的标注文本,在保障语义合理的前提下增加了训练文本的多样性,并通过能量均衡的方式平滑替换音频片段和原音频片段的音量差异,有助于提高语音识别模型的泛化能力。
本文地址:https://www.jishuxx.com/zhuanli/20240618/23303.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表