一种基于双特征的语音情感识别方法及系统
- 国知局
- 2024-06-21 11:44:48
本发明属于语音情感识别,具体涉及一种基于小波散射特征和梅尔频率倒谱系数的双特征并使用排列熵加权和偏差调整规则的语音情感识别方法及系统。
背景技术:
1、人类的情感可以通过各种信息来源来表达和识别,如语音、文字、面部表情、生理信号等,利用两种或多种信息源进行情感识别的方法称为多模态情感识别。在这些信息源中,语音是表达情感最有前景的方法之一,也是实现人机交互的重要基础。
2、一直以来,梅尔频率倒谱系数(mfcc)作为一种模拟人耳听觉特性的声音特征表示方法,被广泛应用于语音情感识别研究。随着数据量的增加和计算能力的提高,深度学习方法在语音情感识别中也展现出强大的性能。在每个任务都需要定制化的神经网络架构的同时,小波散射变换(wst)作为一种新兴的特征提取技术出现,其优点在于它在数学上具有严格的理论证明,并且在实际应用中被证明小样本情境下可以获得优于卷积神经网络(cnn)的识别率,因此,在生物信号、尤其是声音信号中可以为特定分类器或cnn提供优质输入。但是,基于小波散射尺度特征差异性的探索局限于特征级,经检索,尚未发现分数级的相关文献,融合语音wst特征和其他时频尺度特征具有进一步提升声音信号分类性能的潜力。
3、基于现有技术的上述现状,本发明以提高语音情感识别准确率为目的,基于小波散射变换尺度特征的差异性,并根据不同时频表达的互补性,提出了一种基于wst和mfcc的排列熵加权和偏差调整规则的语音情感识别方法及系统。
技术实现思路
1、本发明的目的是提供一种基于双特征的语音情感识别方法及系统,本发明能够有效利用小波散射尺度扩展特征和mfcc相关特征的互补性,通过排列熵加权和偏差调整的方式,提高语音情感识别的准确性和鲁棒性。
2、为了实现上述目的,本发明采用以下技术方案:
3、一种基于双特征的语音情感识别方法,包括以下步骤:
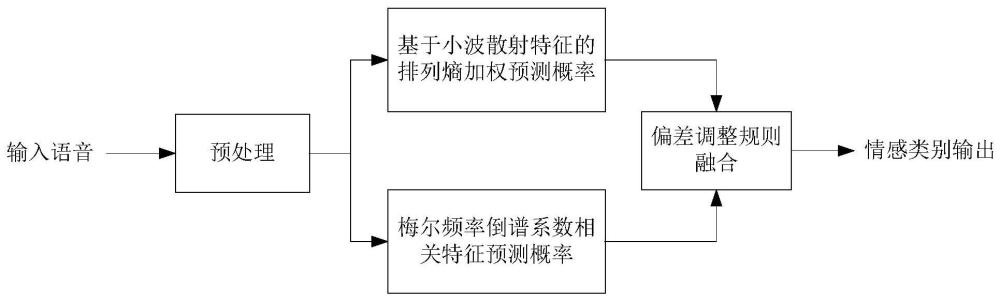
4、s1、预处理:获取采样频率和时长相同的语音信号;
5、s2、提取步骤s1语音信号的两类特征:一类为小波散射特征,另一类为梅尔频率倒谱系数mfcc相关特征;
6、s3、将小波散射特征按尺度维度扩展为尺度特征,并计算各尺度特征的排列熵作为权重;
7、s4、使用排列熵对各尺度特征预测的各情感类别的后验概率进行加权,并按情感类别求和,得到排列熵加权后验概率;
8、s5、使用梅尔频率倒谱系数mfcc相关特征预测各情感类别的后验概率;
9、s6、使用偏差调整规则融合基于两类特征的后验概率,得到最终的情感分类结果。
10、优选的,步骤s1中,将不同采样频率的语音情感数据统一为固定采样频率的样本,并截取固定长度,不足部分使用零填充,最后进行归一化,得到采样频率和时长相同的语音信号。
11、优选的,步骤s2中,所述梅尔频率倒谱系数相关特征为梅尔频率倒谱系数及其一、二阶差分特征的统计值。
12、优选的,步骤s2中,先依据卷积、非线性、平均三步操作获取预处理后语音信号的小波散射特征;再对提取的mfcc及其一、二阶差分特征,求取统计值作为mfcc相关特征。
13、优选的,步骤s3中,按尺度维度将所获得的散射特征扩展为n个相同长度的特征,并赋予相同类别的标签;设置时延和嵌入维度,得到输入尺度维度特征的重构相空间,然后将每个嵌入向量按升序排列,并计算每个排列模式出现的概率,最终根据排列模式概率得到排列熵作为该尺度特征的权重。
14、优选的,步骤s4中,使用支持向量机预测尺度维度特征的各类别后验概率;对每条预测数据的所有尺度特征,使用权重对相应后验概率乘积加权,然后将所有尺度加权概率按情感类别求和,最后归一化得到排列熵加权后验概率
15、优选的,步骤s5中,使用另一个支持向量机预测mfcc相关特征的各类别后验概率pm。
16、优选的,步骤s6中,将mfcc预测所得后验概率与预先设置的偏差调整系数作差;依据判决规则,将基于wst的加权后验概率与基于mfcc偏差调整的后验概率融合,得到最终的预测概率,所述判决规则如下:
17、规则1:当且时,将输入划分为c1类。
18、规则2:当且时,将输入划分为c2类。
19、规则3:当而时,若将输入划分为c1类,否则,划分为c2类。
20、规则4:当而时,若将输入划分为c2类,否则,划分为c1类。
21、其中,符号表示按最大概率值分类,c1和c2为预测所属类别,th为设定的偏差调整系数。
22、本发明还提供了一种基于双特征的语音情感识别系统,该系统用于执行上述语音情感识别方法,包括以下模块:
23、预处理模块:用于统一不同采样频率的数据集,得到相同时长、采样频率的语音样本;
24、特征提取模块:用于从语音样本中提取小波散射特征矩阵,并按尺度维度扩展为尺度特征;以及获取mfcc相关特征;
25、排列熵加权模块:用于小波散射特征按尺度维度扩展为尺度特征,计算尺度特征的排列熵,并根据排列熵对各尺度特征预测的情感类别的后验概率进行加权求和,归一化得到排列熵加权后验概率,使用梅尔频率倒谱系数相关特征预测情感类别的后验概率;
26、偏差调整模块:根据偏差调整规则,调整基于小波散射特征和梅尔频率倒谱系数两类特征的后验概率,根据判决规则得到最终的情感分类结果。
27、作为优选方案,排列熵加权模块使用svm1预测各尺度特征的各情感类别的后验概率;并根据各尺度特征的排列熵作为权重,对各尺度特征的后验概率进行乘积相加;最后对加权结果进行归一化,得到排列熵加权后验概率。
28、偏差调整模块使用svm2预测mfcc相关特征的各情感类别的后验概率;并根据预设的偏差调整系数,与svm2的预测结果做差;根据判决规则得到最终的情感分类结果。
29、作为优选方案,基于双特征的排列熵加权模块和偏差调整模块构成语音情感识别的排列熵加权与偏差调整结构。
30、综上,本发明公开了一种基于小波散射变换和梅尔频率倒谱系数的双特征语音情感识别方法及系统,在本发明技术方案中,输入经过预处理之后并行进入两个模型分支。首先是基于小波散射特征的模型,它负责提取出小波散射特征,并按尺度维度扩展为尺度特征向量,同时计算各尺度特征的排列熵,对基于尺度特征的预测概率加权求和;其次是基于梅尔频率倒谱系数的识别模型,它负责提取出梅尔频率倒谱系数相关特征,并预测各情感类别后验概率;最后使用偏差调整规则融合两支路的预测结果,由此得到最终的情感预测结果。
31、与现有技术相比,本发明具有如下优点:
32、(1)本发明利用小波散射变换的尺度维度扩展特征,无需额外的计算开销,增加了情感语音的训练数据量,提高了特征的表达能力。
33、(2)本发明采用排列熵对不同尺度特征的识别结果进行加权,有效地利用了小波散射变换不同尺度特征对语音情感的差异性表征,同时该模型仅在加权时进行一次点乘操作,保证了该模块的加入不会显著增加整个系统的复杂度,影响系统的运行效率。
34、(3)本发明设计了基于不同时频尺度特征的并行结构,通过偏差调整规则在分数级上进行融合,该结构采用简单的系统构成,充分利用了不同时频尺度特征的互补性,进一步提高了语音情感识别的准确率和鲁棒性。
本文地址:https://www.jishuxx.com/zhuanli/20240618/23317.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表