一种基于语音识别的电子设备及其控制方法与流程
- 国知局
- 2024-06-21 11:44:43
本发明属于自动语音识别,更具体地说,是涉及一种基于语音识别的电子设备及其控制方法。
背景技术:
1、语音识别就是让机器通过识别和理解过程把语音信号转变为相应的文本或命令的一种技术,包括特征提取技术、模式匹配准则、模型训练技术。
2、现有的语音识别为文字主要是针对有文字的民族语言,而针对没有文字的各种方言是无法进行语音识别为汉语文字。
技术实现思路
1、为了解决现有技术上的不足之处,本发明的目的在于提供一种led灯及其远程控制系统、方法,通过设置语音采集模块、信号处理模块、特征提取模块、语音识别模块、文字转换模块,可以对任何汉语地区的方言或没有自己文字的少数民族方言的语音可以在线自动转换为汉语文字,解决了针对没有文字的各种方言是无法进行语音识别为汉语文字的的问题。
2、为了实现上述目的,本发明采取的技术方案是:
3、一种基于语音识别的控制方法,应用于一种基于语音识别的控制系统,包括语音采集模块、信号处理模块、特征提取模块、语音识别模块、文字转换模块、语音数据库、报警器、存储器、处理中心;所述语音采集模块、信号处理模块、特征提取模块、语音识别模块、文字转换模块、语音数据库、报警器、存储器分别与处理中心相连;所述语音数据库为各汉语地区的各种方言的语音以及没有自己文字的各少数民族语言的语音的收集;
4、所述报警器根据所述处理中心根据获取的语音特征信息与存储器存储的各种语言的语音标准库进行匹配,若不一致时,则自动发出声音报警,证明为新的语言的语音,并传递给语音数据库,作为后续类似语言的语音识别的标准;
5、所述存储器负责语音采集模块、信号处理模块、特征提取模块、语音识别模块、文字转换模块、语音数据库、报警器的信息存储,以及所录入的各种地区或各少数民族的方言语音的存储;
6、所述处理中心负责语音采集模块、信号处理模块、特征提取模块、语音识别模块、文字转换模块、语音数据库、报警器、存储器的信息传递,为系统枢纽中心,并根据获取的语音特征信息与存储器存储的各种语言的语音标准库进行匹配,若一致则识别为具体的语音种类,并传递给语音识别模块;若不一致则传递给报警器,证明为新的语言的语音,并传递给语音数据库,作为后续类似语言的语音识别的标准;
7、所述控制语音采集模块通过录音设备采集汉语方言和各少数民族地区方言的口音、说话速度以及极性等因素生成目标语音信号,并转换为模拟电信号通过模数转换器转化为数字信号,并传递给信号处理模块;
8、所述信号处理模块负责将连续的声波信号滤波转换成离散的数字信号,并将数字信号的幅度量化成离散的数值,再将量化后的数字信号转换成二进制码,去除噪声、增强语音信号的可识别性,并传递给特征提取模块;
9、所述特征提取模块包括预备加重单元、加窗分帧单元、频域变换单元、梅尔频率单元、倒谱分析单元、傅里逆变单元、特征计算单元,将处理后的语音信号被分解成小的时间片段的帧,并提取每个帧的特征为语音的频谱特征并分析为一系列特征向量,并传递给处理中心;
10、所述语音识别模块负责对识别出的具体语言的语音的特征向量与训练好的语音模型进行匹配,并通过hmm模型、asr系统的训练和优化确定为具体的文字内容,并传递给文字转换模块;
11、所述文字转换模块负责将语音识别出的具体的文字内容转化为可读的标准汉语文字信息,并通过纠错、断句、标点符号添加等方法可以使转换结果更符合自然语言的语法规则和语义逻辑,进一步提高语音转文字的准确性和可读性。
12、本发明还提供一种基于语音识别的控制方法,包括以下步骤:
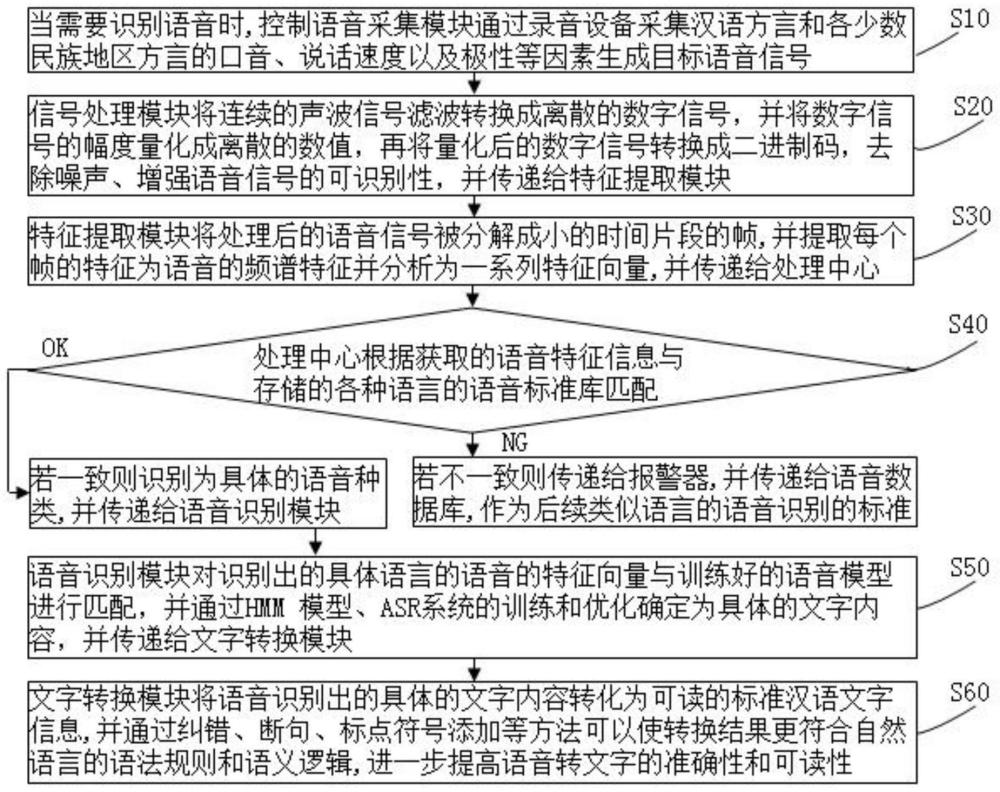
13、s10、当需要识别语音时,控制语音采集模块通过录音设备采集汉语方言和各少数民族地区方言的口音、说话速度以及极性等因素生成目标语音信号,并转换为模拟电信号通过模数转换器转化为数字信号,并传递给信号处理模块;
14、s20、信号处理模块将连续的声波信号滤波转换成离散的数字信号,并将数字信号的幅度量化成离散的数值,再将量化后的数字信号转换成二进制码,去除噪声、增强语音信号的可识别性,并传递给特征提取模块;
15、s30、特征提取模块将处理后的语音信号被分解成小的时间片段的帧,并提取每个帧的特征为语音的频谱特征并分析为一系列特征向量,并传递给处理中心;
16、s40、处理中心根据获取的语音特征信息与存储器存储的各种语言的语音标准库进行匹配:若一致则识别为具体的语音种类,并传递给语音识别模块;若不一致则传递给报警器,证明为新的语言的语音,并传递给语音数据库,作为后续类似语言的语音识别的标准;
17、s50、语音识别模块对识别出的具体语言的语音的特征向量与训练好的语音模型进行匹配,并通过hmm模型、asr系统的训练和优化确定为具体的文字内容,并传递给文字转换模块;
18、s60、文字转换模块将语音识别出的具体的文字内容转化为可读的标准汉语文字信息,并通过纠错、断句、标点符号添加等方法可以使转换结果更符合自然语言的语法规则和语义逻辑,进一步提高语音转文字的准确性和可读性。
19、进一步,所述步骤s30,包括以下步骤:
20、s31、预备加重单元通过一阶高通滤波器给定时域输入信号x[n]而变为“y[n]=x[n]-αx[n-1],0.9≤α≤1.0,x[n]为原始信号,αx[n-1]为衰减信号”,加强高频信号的频率,防止高频信号衰减,并传递给加窗分帧单元;
21、s32、加窗分帧单元将不定长的音频数字信号切分成固定长度的若干个小段的帧长为10~30ms的帧,信号变为“y[n]=w[n]x[n],y[n]为分帧后信号,w[n]为窗函数,x[n]为原始信号”,避免减少帧之间的干扰,并传递给频域变换单元;
22、s33、频域变换单元通过傅里叶变换将若干个小段的帧长为10~30ms的语音帧由时域信号变换到频域信号为“f(ω)为f(t)的象函数,f(t)为f(ω)的象原函数,ω为频率,t为时间,e为自然对数的底数,i为虚数单位(即i的平方为-1),d为在时域和频域都离散,dt为在时域是离散”,取dft系数的模获得谱特征,并传递给梅尔频率单元;
23、s34、梅尔频率单元将线性频率“f=2595*log10(1+f/700)”转换为梅尔频率“mel(f)=2595*log10(1+f/700)”后进行对数运算,并传递给倒谱分析单元;
24、s35、倒谱分析单元通过梅尔倒谱系数将频域信号“log|x[m]|=log|h[m]|+log|e[m]|”分解成谱包络和谱细节的乘积“x[m]=h[m]*e[m]”而获取语音的特征,并传递给傅里逆变单元;
25、s36、傅里逆变单元通过傅里叶逆变换(idft)之后的第1~k个点,为k维mfcc特征提取,并传递给特征计算单元;
26、s37、特征计算单元通过一阶二阶差分操作对一段语音信号进行mfcc特征提取而获取动态特征。
27、本发明提供的一种基于语音识别的控制系统,还包括计算机设备、计算机可读存储介质;所述计算机设备包括存储器和各功能模块,所述存储器存储有计算机程序,所述各功能模块执行所述计算机程序时实现以上任意一项所述的一种基于语音识别的控制方法的步骤;所述计算机可读存储介质上存储有计算机程序,所述计算机程序被各功能模块执行时实现以上任意一项所述的一种基于语音识别的控制方法的步骤。
28、本发明还提供一种基于语音识别的电子设备,由以上所述的一种基于语音识别的控制方法所实现。
29、本发明与现有技术相比的有益效果:
30、通过设置语音采集模块、信号处理模块、特征提取模块、语音识别模块、文字转换模块,可以对任何汉语地区的方言或没有自己文字的少数民族(包括其它国家民族)方言的语音可以在线自动转换为汉语文字,解决了针对没有文字的各种方言是无法进行语音识别为汉语文字的的问题。
本文地址:https://www.jishuxx.com/zhuanli/20240618/23306.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表