基于残差网络带二维注意力和语义增强的说话人识别方法
- 国知局
- 2024-06-21 11:47:57
本发明属于声纹识别,涉及基于残差网络带二维注意力和语义增强的说话人识别方法。
背景技术:
1、说话人验证是一种通过比较两个语音样本以验证它们是否由同一个说话人发出的技术。作为生物识别的一种重要方式,它被广泛应用于安全、认证和监测等领域。近年来,基于深度学习的声纹识别系统在性能上有了很大的提高。说话人系统由三个模块组成:计算说话人嵌入的特征提取模块,训练时的评分模块,以及推理时的校准模块。其中特征提取模块是最重要的组件,将高维的输入语音转换为一个紧凑的向量,即嵌入,来表示说话人特定的特征,之后再由后面的模块进行评分以迭代或者推理以判别。因此,为了取得更好的性能,对说话人特定特征提取和增强的对于说话人识别任务至关重要。随着深度学习技术的发展,基于深度学习的声纹识别系统在性能上得到了显著提升。
2、传统的说话人验证技术通常面临数据量不足和过拟合问题,这限制了模型的泛化能力。为了解决这些问题,研究者们提出了各种数据增强技术,如通过对输入音频的预处理来增加训练样本的多样性。然而,这些方法往往在计算成本和可靠性方面存在不足。
3、并且传统的squeeze-and-excitation(se)模块在处理高维潜在空间时,往往难以找到理想的注意力权重分配。
技术实现思路
1、有鉴于此,本发明的目的在于提供基于残差网络带二维注意力和语义增强的说话人识别方法,该方法通过隐式语义数据增强对说话人嵌入进行有意义的语义方向增强,既不需要额外的计算成本,又能提高数据的可靠性,进而提升模型的泛化能力;并且,针对模型中的注意力机制进行了改进,通过一个池化层和两个卷积层来计算通道-频率的平面注意力权重,从而更全面地捕捉输入数据中不同维度之间的相关性,提高模型的健壮性,从而解决背景技术中存在的技术问题。
2、为达到上述目的,本发明提供如下技术方案:
3、基于残差网络带二维注意力和语义增强的说话人识别方法,该方法包括以下步骤:
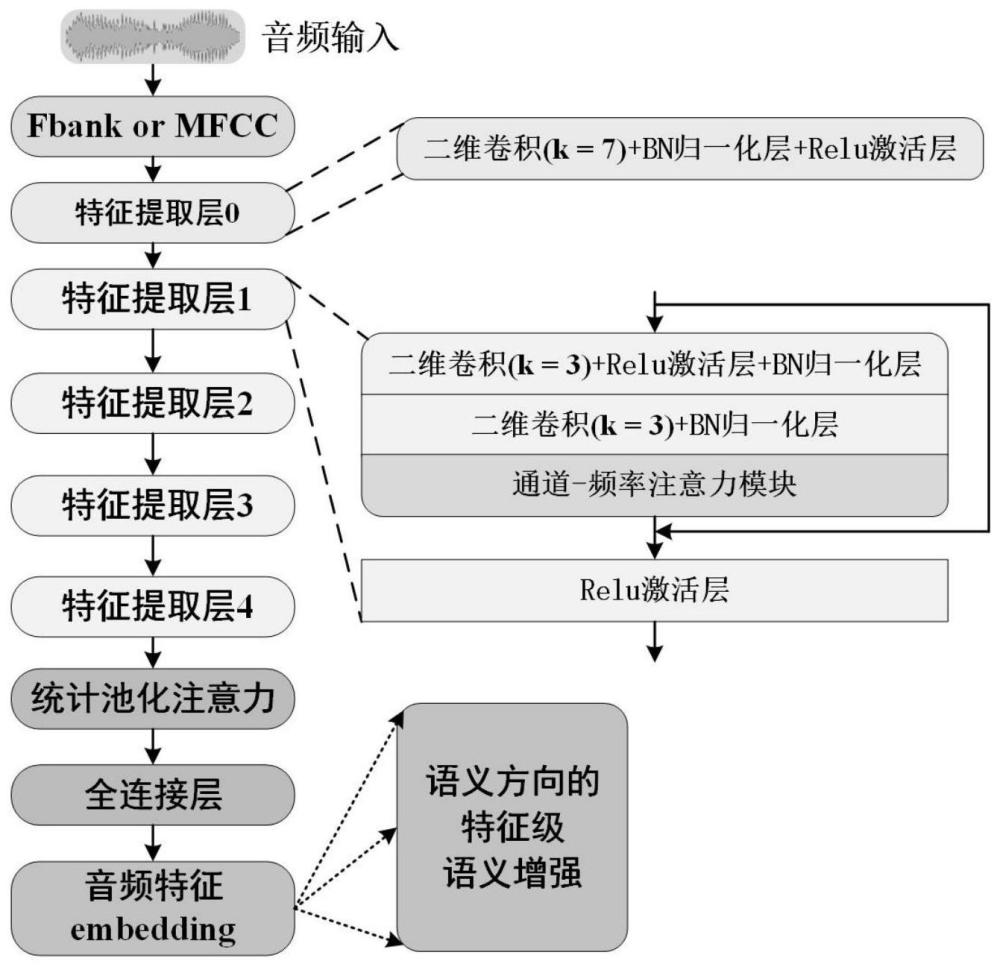
4、s1:将接收语音信号的梅尔频谱图作为模型的输入;
5、s2:将输入的语音信号的梅尔频谱图依次经过第一特征提取层和四个第二特征提取层,所述第一特征提取层与四个第二特征提取层串联起来进行特征提取;
6、所述第二特征提取层包含四层结构,第一层结构包括:二维卷积层、非线性激活层和归一化层;第二层结构包括:二维卷积层和归一化层;第三层结构为通道-频率注意力模块层;将通道-频率注意力模块层的输出通过残差结构与该第二特征提取层的输入的下采样连接共同经过第四层的relu非线性激活层;
7、s3:将s2提取的多个层级特征进行融合,同时利用网络浅层和深层的信息;
8、s4:将融合后的特征输入基于注意力机制的统计池化层和全连接层,生成说话人特征嵌入;
9、s5:在说话人特征嵌入空间中执行有意义的语义扰动,实现特征级别的数据增强。
10、进一步的,所述s2中,第一特征提取层包括:二维卷积层、归一化层和非线性激活层,使用二维卷积层来处理输入特征,使用归一化层来调整特征的尺度,并通过非线性激活函数增强特征表示。
11、进一步的,所述s2中,通道-频率注意力模块,引入频率的关注度和频率间依赖关系来充分利用信息,并使用压缩注意力模块se计算频率的注意力权重,通过广播机制将不同的频率注意力权重向量调整到相同的形状rc×f×1,然后进行元素级运算将频率注意力权重与通道的注意力权重进行融合,计算过程表示为:
12、ω=ωc⊙ωf (1)
13、其中,ωc∈rc×f×1和ωf∈rc×f×1是经过广播调整的通过到注意力权重和频率注意力权重,⊙表示元素级相乘,得到通道和频率的二维平面注意力权重,将得到通道和频率的二维平面注意力权重与输入特征进行元素级乘法,来重新调整每个通道和频率的特征。
14、进一步的,使用压缩注意力模块se计算频率的注意力权重,具体为:
15、在所述压缩压励注意力模块中,输入x∈rc×f×t,其中,c是卷积通道的数量,f表示频率维度,t代表在时间维度上的特征长度;
16、se模块操作集中在通道的维度,为减少计算时的参数量,提前对频率和时间的维度进行压缩处理;
17、所述提前对频率和时间的维度进行压缩处理,具体为,对于每个通道c,将该通道上所有的元素值求均值,得到该通道上的全局平均值,即在频率时间平面上进行全局平均池化,公式表示为:
18、
19、每个通道的全局信息被聚合在向量s中,其长度为c,其中的每个元素代表对应通道的全局平均值;并用向量s来进行的求通道注意力的操作;所述通道注意力的操作是通过两个全连接层和一个非线性层来捕获跨通道的交互,如公式(3)所示:
20、ω=σ(w2(relu(w1sc))) (3)
21、其中,σ()是sigmoid函数,w2和w1是权重矩阵,维度分别是大小为c×d和d×c的矩阵;其中,d是小于c的超参数,用于减少模型复杂度;relu激活函数被应用于w1和某个输入信号sc的乘积,激活信号被乘第二个权重矩阵w2,将维度回到的sc通道维度数,通过sigmoid激活函数将输出限制在(0,1)之间,得到每个通道的注意力权重ω∈rc,将所述得到每个通道的注意力权重作为压缩激励模块的输入x,通过按元素相乘来缩放每个通道,每个通道的信息能根据其重要性进行加权,实现对不同通道的动态调整。
22、进一步的,所述s5中,在说话人特征嵌入空间中执行有意义的语义扰动,实现特征级别的数据增强,具体为:
23、假设训练集是并且yi∈{1,…,n}是n个说话人类别上第i句音频xi的标签;向量fi=[fi1,…,fif]t表示神经网络提取的xi的高维特征嵌入;
24、动态计算某个说话人yi的类内协方差矩阵
25、动态计算某个说话人yi的类内协方差矩阵具体为:根据每个小批量的统计数据在线计算该批量中的均值和协方差矩阵,并通过按比例聚合该批次和之前所有小批量的统计数据以在线方式计算该说话人总的协方差矩阵;在嵌入计算得出之后,计算说话人总的协方差矩阵和融合协方差矩阵,每个说话人在训练期间有自己的协方差矩阵来增强该说话人的数据;
26、以该协方差矩阵构建嵌入层次的正态分布作为采样方向,从零均值正态分布中随机采样获得表示fi的语义方向的向量;增强嵌入由公式(4)表示:
27、
28、其中,~表示的取值依赖于λ是控制语义数据增强强度的系数;
29、协方差是在训练期间动态计算的,当网络训练周期较少时,动态计算的说话人协方差矩阵不完善;在前期通过λ减少协方差对计算过程的影响;fi是初始提取的特征嵌入,是经过增强后的特征嵌入;将每个嵌入fi增强m次;将每个样本扩充到m个再计算该样本,经过最后一层线性层后计算交叉熵损失函数,表示为:
30、
31、其中,w和b表示从特征嵌入到分类层之间线性层的权重和偏置;fim表示特征嵌入fi被增强的第m个嵌入;计算损失的嵌入样本数量为nm个;在m→∞时,为损失函数导出一个计算的上限,近似模拟使用所有可能的语义增强方向下所得到的交叉熵损失的期望,表示为:
32、
33、log(·)是凹函数,使用jensen不等式e(logx)≤loge(x)进行近似:
34、
35、由于公式(4)中,的分布符合正态分布,使用矩生成函数对的期望进行计算代入公式(7)中得到:
36、
37、公式(8)损失函数最终损失函数的期望值,即在没有显式增强样本的情况下,通过该损失函数计算损失的上限来更有效地执行隐式语义数据增强。
38、本发明的有益效果在于:
39、第一,本发明基于说话人嵌入级别的语义增强和通道-频率平面的注意力机制相结合的模型改进方法,实现对嵌入进行有意义的语义方向增强和对数据的多维特征关联计算;扩充样本量和提高特征捕获能力,进而改善模型的性能。
40、第二,本发明中特征提取层融合了二维的卷积特征提取层和通道-频率注意力模块,这使得模型能够对特征不同通道和频率之间的关系进行建模,使得模型能够更加灵活地学习特定频率上的信息,有助于捕捉与任务相关的细粒度模式。
41、第三,本发明通过隐式语义数据增强将说话人嵌入进行有意义的语义方向增强,几乎不需要额外的计算成本,同时加强了数据的可靠性,提高了模型的泛化能力。
42、第四,本发明提供一种高效的注意力模块,由一个池化层和两个卷积层以计算通道-频率的平面注意力权重,更全面地捕捉输入数据中不同维度之间的相关性,提高了模型的健壮性。
43、本发明的其他优点、目标和特征在某种程度上将在随后的说明书中进行阐述,并且在某种程度上,基于对下文的考察研究对本领域技术人员而言将是显而易见的,或者可以从本发明的实践中得到教导。本发明的目标和其他优点可以通过下面的说明书来实现和获得。
本文地址:https://www.jishuxx.com/zhuanli/20240618/23621.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表