一种大模型发音偏误检测及发音动作图像反馈方法及装置
- 国知局
- 2024-06-21 11:53:31
本发明涉及计算机辅助语音教学,特别是指一种大模型发音偏误检测及发音动作图像反馈方法及装置。
背景技术:
1、在二语学习的计算机辅助教学系统领域,如何为学习者提供有效的反馈信息,长期以来一直是研究和工业界的重点与难题。研究[1]展示了使用有限状态自动机(finitestate automata,fsa)来模拟跟读文本中正确语音及潜在错误语音路径的方法。基于识别到的路径,该方法允许教师或语音专家事先编写各路径的具体反馈信息,从而能为学习者提供包含发音动作的反馈。目前,工业界普遍采用的做法是利用偏误检测系统来比较学习者的实际音素与标准音素,从而识别出潜在错误的音素,并利用统计方法推测错误原因。然而,这种基于fsa的方法虽然能够提供具体的动作反馈,但它需要大量的预设工作和专业人员的参与,这在实际工业应用中往往是不可行的。此外,它仅限于特定文本的范围内,无法广泛适用于不同的学习情景。而目前工业界广泛采用的基于统计方法的反馈,往往因错误原因众多而难以精准定位,导致学习者得到的反馈信息有限,且无法获得针对具体发音动作的指导。此外,现有的计算机辅助二语教学系统尚未广泛整合图像反馈功能。
2、另一方面,研究界尝试使用核磁共振技术获取二语学习者的口型发音数据,以提供更为直观的发音图像反馈。尽管这种方法在理论上具有潜力,但由于核磁共振设备昂贵,这限制了其在实际应用中的普及。目前尚无一种技术方案能够针对任意指定的跟读文本提供全面的反馈,同时将语音反馈与图像反馈有效融合。
3、当前,在二语学习领域,基于有限状态自动机的方法能够为学习者提供包含发音动作的反馈。然而,这种方法存在显著缺陷。首先,它要求预先设计可能的语音路径和反馈信息,这一过程需要依赖于语音学专家的深度参与,从而导致人力资源的大量消耗,这在工业界是难以接受的。其次,fsa方法仅能适用于预定的文本范围,限制了它在更广泛教学场景中的应用。
4、此外,目前工业界广泛采用基于统计的方法来提供错误原因的反馈。这种方法面临的主要问题在于,它可能无法准确识别并反馈出真正导致错误的具体原因。由于错误的可能原因众多,这导致最终提供给学习者的反馈信息往往过于笼统,难以针对个体情况进行精准指导。更重要的是,这种方法没有提供发音动作的修正反馈,缺乏直观的视觉指导,这是在提高发音准确性方面极为关键的。
5、在技术上更先进的尝试,如使用核磁共振技术获取学习者的口型发音数据,也面临着实际应用的限制。核磁共振设备的高昂成本使其难以普及,并且当前还不存在一种技术方案,能够在任意给定的跟读文本上实现综合的语音和图像反馈,从而提供多模态的、用户友好的反馈体验。
技术实现思路
1、为了解决现有技术在不能够在任意给定的跟读文本上实现综合的语音和图像反馈,从而提供多模态的、用户友好的反馈体验的技术问题,本发明实施例提供了一种大模型发音偏误检测及发音动作图像反馈方法及装置。所述技术方案如下:
2、一方面,提供了一种大模型发音偏误检测及发音动作图像反馈方法,该方法由大模型发音偏误检测及发音动作图像反馈设备实现,该方法包括:
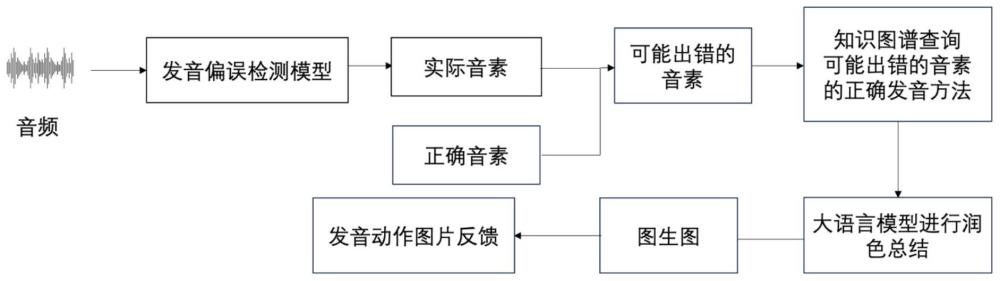
3、s1、获取二语学习者音频,将二语学习者音频输入至发音偏误模型中,输出二语学习者的实际音素序列;对实际音素序列进行错误识别处理,获得错误发音;
4、s2、构建知识图谱,通过知识图谱对错误发音进行对应正确发音的搜索,获得反馈信息;
5、s3、将反馈信息输入至大语言模型中,获得反馈文本;
6、s4、预设正确发音的口型图片,基于正确发音的口型图片通过图生图技术生成对应的发音口型图像;
7、s5、将反馈文本和发音口型图像综合反馈给二语学习者,完成大模型发音偏误检测及发音动作图像反馈。
8、可选地,s1中,获取二语学习者音频,将二语学习者音频输入至发音偏误模型中,输出二语学习者的实际音素序列,包括:
9、获取二语学习者音频;
10、构建发音偏误模型,通过预设的标准跟读文本对发音偏误模型进行训练,获得训练好的发音偏误模型,
11、将二语学习者音频输入至训练好的发音偏误模型中,输出二语学习者的实际音素,实际音素包括正确发音和错误发音。
12、可选地,s1中,对实际音素序列进行错误识别处理,获得错误发音,包括:
13、获取实际音素序列,通过维特比算法,从实际音素序列中的正确音素和实际音素中,识别存在的发音错误的音素,获得错误发音。
14、可选地,步骤s2中,构建知识图谱,通过知识图谱对错误发音进行对应正确发音的搜索,获得反馈信息,包括:
15、识别并获取错误发音;
16、构建知识图谱,知识图谱包括中文声母、中文韵母,以及每个中文声母中文韵母的发音属性;
17、通过知识图谱对错误发音进行对应正确发音的搜索,获得反馈信息。
18、可选地,步骤s3中,将反馈信息输入至大语言模型中,获得反馈文本,包括:
19、将反馈信息输入至大语言模型中,通过大语言模型对反馈信息进行润色和总结,生成反馈文本。
20、可选地,s4中,预设正确发音的口型图片,基于正确发音的口型图片通过图生图技术生成对应的发音口型图像,包括:
21、预设声韵母的口型图片,从口型图片中提取关键的图像轮廓信息;
22、添加知识图谱中与口型图片的发音细节相关的文本描述,生成发音口型图片。
23、可选地,将反馈文本和发音口型图像综合反馈给二语学习者,完成大模型发音偏误检测及发音动作图像反馈,包括:
24、获取反馈信息以及发音口型图像;
25、将反馈信息和发音口型图像综合发送至展示页面端;
26、二语学习者获取发音偏误情况及后续发音练习方向,完成大模型发音偏误检测及发音动作图像反馈。
27、另一方面,提供了一种大模型发音偏误检测及发音动作图像反馈装置,该装置应用于大模型发音偏误检测及发音动作图像反馈方法,该装置包括:
28、发音偏误识别模块,用于获取二语学习者音频,将二语学习者音频输入至发音偏误模型中,输出二语学习者的实际音素序列;对实际音素序列进行错误识别处理,获得错误发音;
29、知识图谱模块,用于构建知识图谱,通过知识图谱对错误发音进行对应正确发音的搜索,获得反馈信息;
30、反馈文本生成模块,用于将反馈信息输入至大语言模型中,获得反馈文本;
31、图生图模块,用于预设正确发音的口型图片,基于正确发音的口型图片通过图生图技术生成对应的发音口型图像;
32、综合反馈模块,用于将反馈文本和发音口型图像综合反馈给二语学习者,完成大模型发音偏误检测及发音动作图像反馈。
33、另一方面,提供一种大模型发音偏误检测及发音动作图像反馈设备,所述大模型发音偏误检测及发音动作图像反馈设备包括:处理器;存储器,所述存储器上存储有计算机可读指令,所述计算机可读指令被所述处理器执行时,实现如上述大模型发音偏误检测及发音动作图像反馈方法中的任一项方法。
34、另一方面,提供了一种计算机可读存储介质,所述存储介质中存储有至少一条指令,所述至少一条指令由处理器加载并执行以实现上述大模型发音偏误检测及发音动作图像反馈方法中的任一项方法。
35、本发明实施例提供的技术方案带来的有益效果至少包括:
36、本发明提出了一种创新的基于知识图谱检索的大语言模型发音偏误检测及发音动作图像反馈方法。此方法的核心在于,它能够自动生成针对任意跟读文本的发音动作反馈,包括文本和图像信息,而无需依赖预先编写的反馈内容。这一创新解决了现有技术中的两大主要问题:一是显著降低了对专业语音人员的依赖,从而减少了人力成本;二是突破了仅限于特定跟读文本的限制,实现了更广泛应用的可能性。此外,通过结合文字和图像反馈,本技术为二语学习者提供了一种更全面、直观的学习体验,从而在提高学习效率和发音准确性方面具有显著优势。
本文地址:https://www.jishuxx.com/zhuanli/20240618/24305.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表