音频处理方法、可读存储介质、程序产品及电子设备与流程
- 国知局
- 2024-06-21 11:53:43
本技术涉及终端,特别涉及一种音频处理方法、可读存储介质、程序产品及电子设备。
背景技术:
1、目前,用户通常使用手机、平板电脑等电子设备进行语音交互。电子设备可以通过麦克风等设备采集电子设备外界的音频,并基于采集的音频执行相应的操作,例如识别所采集的音频中的语音指令并执行识别出的指令、将采集的音频发送给其他电子设备以实现通话、会议、网课、直播等。
2、在一些场景中,如果电子设备的周围有噪声干扰,电子设备所采集的音频中包括噪声,例如环境噪声、用户所处环境中其他用户的声音等。如此,会影响用户利用语音进行交互的质量。例如,在用户通过语音向电子设备传递指令的场景中,电子设备会由于噪声较大而无法准确识别用户的语音指令。又例如,用户在声音嘈杂的区域进行会议、直播等的情况下,环境噪声和其他用户的声音也会被电子设备采集并传输给其他电子设备,如此,会导致其他电子设备的用户不易听清该用户的语音或者干扰其他电子设备的用户。
技术实现思路
1、本技术实施例提供了一种音频处理方法、可读存储介质、程序产品及电子设备。
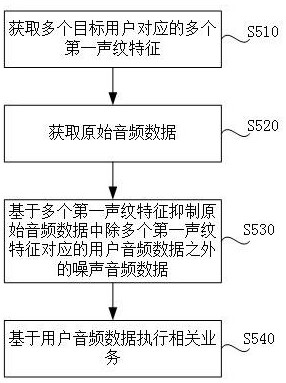
2、第一方面,本技术实施例提供了一种音频处理方法,应用于第一电子设备,方法包括:获取对应第一业务的第一音频数据;将第一音频数据和n个第一声纹特征输入到第一模型中,以使得第一模型基于n个第一声纹特征得到第一音频中n个第一声纹特征对应的第二音频数据,其中,不同的第一声纹特征对应不同的第一用户,n为大于1的整数;基于第二音频数据执行第一业务。
3、示例性地,在本技术的一些实施例中,第一音频数据还可以被称为原始音频数据,第一用户还可以被称为目标用户,第二音频数据还可以称为用户音频数据。可以理解,第一电子设备在获取第一音频数据后,可以通过第一模型对第一音频数据降噪处理,从而获得只包含第一用户对应的第二音频数据。并且,第一电子设备可以存储多个第一用户的第一声纹特征,也就是说,第一电子设备可以保留第一音频数据中多个第一用户的语音,从而满足多名第一用户的使用要求。
4、在上述第一方面的一种可能的实现中,上述n个第一声纹特征是基于以下方式确定的:确定第一音频数据对应声纹特征的类别,并从m个第一声纹特征中确定出与第一音频数据对应声纹特征的类别对应的n个第一声纹特征,其中,m为大于n的整数。
5、示例性地,在本技术的一些实施例中,第一电子设备可以存储m个第一用户的m个第一声纹特征。但是,第一电子设备获取的第一音频数据中,只包含了n个第一用户的第一声纹特征。如此,在对第一音频数据降噪时,可以只向第一模型中输入对应的n个第一声纹特征即可,从而减少第一模型对第一音频数据降噪的复杂度。提高降噪速率和降噪效果。
6、在一些实施例中,电子设备还可以基于一个分类标准对声纹特征进行分类。从而在第一音频数据中基于分类标准获取目标类别的声纹特征,再基于分类标准从m个第一声纹特征中选择属于目标类别的n个第一声纹特征输入第一模型。如此,在第一音频数据中的声纹特征较多的情况下,不需要将每个声纹特征与第一声纹特征对比,从而减少选择第一音频数据中n个第一声纹特征的复杂度。其中,多个第一声纹特征可以属于一个类别。目标类别中,可以包括多个声纹类别。
7、在上述第一方面的一种可能的实现中,上述将第一音频数据和n个第一声纹特征输入到第一模型中,以使得第一模型基于n个第一声纹特征得到第一音频中n个第一声纹特征对应的第二音频数据,包括:确定n个第一声纹特征在第一音频数据中的权重信息;将权重信息、第一音频数据和n个第一声纹特征输入到第一模型中,以使得第一模型基于n个第一声纹特征、n个第一声纹特征的权重信息得到第一音频中n个第一声纹特征对应的第二音频数据,其中,第一声纹特征的权重越大、第一模型对第一声纹特征对应的音频数据保留的越完整。
8、示例性地,在本技术的一些实施例中,将n个第一声纹特征输入第一模型之前,还可以根据n个第一声纹特征在第一音频数据中对应音频的时长和/或能量对n个第一声纹特征进行加权,并将n个第一声纹特征对应的权重也输入第一模型。第一模型在对第一音频数据降噪时,权重越高的第一声纹特征对应的音频保留的越完整。
9、例如,在第一音频数据中,有a和b两名第一用对应的语音,其中,a的语音时长较长,并且声音大,能量高。b的语音时长较短,并且声音小。因此,在第一音频数据中,a的语音占主导地位,因此,a对应的权重较高,在降噪过程中,可以更完整地保留a的语音。
10、在上述第一方面的一种可能的实现中,上述权重信息是基于以下信息中的至少一种确定的:第一声纹特征对应的音频数据在第一音频数据中的能量、第一声纹特征对应的音频数据在第一音频数据中的时长。
11、在上述第一方面的一种可能的实现中,上述第一模型为扩散模型。
12、在上述第一方面的一种可能的实现中,上述扩散模型是基于以下方式训练得到的:将第二用户对应的第三音频数据输入到扩散模型,以使得扩散模型分t步对第三音频数据添加t个噪声数据得到带噪数据;基于带噪数据对扩散模型进行训练,以使得扩散模型基于第二用户对应的第二声纹特征分t步对带噪数据进行去噪处理,并且扩散模型第i步对带噪数据进行去噪处理所去除的数据与t个噪声数据中的第i个数据的误差小于误差阈值;其中,t为大于0的整数,1≤i≤t。
13、示例性地,在本技术的一些实施例中,扩散模型的训练过程例如可以是对第二用户(还可以称为说话人)的第三音频数据(还可以被称为干净数据)分t步添加噪声数据。可以理解,第三音频数据没有噪声,仅有第二用户的语音,属于干净数据。在经过t步添加噪声后,第三音频数据生成的带噪数据接近白噪声。之后对带噪数据分t步去除噪声数据,训练第一模型每一步去除的噪声数据与该步添加的噪声数据的误差小于误差阈值。可以理解,在训练去除噪声数据的过程中,可以将第二用户对应的第二声纹特征作为控制条件,保留第二声纹特征对应的音频数据不被去除。
14、在上述第一方面的一种可能的实现中,上述第一业务为语音交互业务,基于第二音频数据执行第一业务,包括:识别第二音频数据中的第一用户的语音,并输出第一用户的语音对应的文字内容,或者基于第一用户的语音执行对应的功能。
15、可以理解,在本技术的一些实施例中,第一电子设备将获取的第一音频数据根据第一模型降噪,获得第二音频数据后,可以基于第二音频执行相关业务。例如,该相关业务可以是语音交互。第一电子设备能够基于第二音频数据,更加准确的确定第一用户的指令。例如,调整温度,报告天气情况,定闹钟等。或者第一电子设备可以识别出第一用户的第二音频数据中的语音内容,并生成文本输出,输出的文本更加精确。
16、在上述第一方面的一种可能的实现中,上述第一业务为向第二电子设备传输音频数据的业务,基于第二音频数据执行第一业务,包括:将第二音频数据传输给第二电子设备。
17、在本技术的一些实施例中,第一电子设备获取第二音频特征后,可以将第二音频数据传输给第二电子设备。例如第一用户通过第一电子设备进行通话。第一电子设备可以将第二音频数据传输给通过对方的第二电子设备,从而使得第一用户的语音更加清楚,提高通话质量。
18、在上述第一方面的一种可能的实现中,上述第一声纹特征是第一电子设备历史采集的至少一个第四音频数据对应的声纹特征。
19、示例性地,在本技术的一些实施例中,第一电子设备的第一声纹特征可以根据第四音频数据获得。示例性地,第四音频数据可以通过第一用户主动注册。第一电子设备可以从第四音频数据中提取除第一用户的第一声纹特征。在另一些实施例中,第一音频数据也可以是多个人语音数据,第一电子设备可以提取除各个人的声纹特征,并让机主判断是否将当前说话人作为第一用户,从而将当前的声纹特征作为第一声纹特征。
20、第二方面,本技术提供一种电子设备,该电子设备包括:存储器,用于存储指令;至少一个处理器,用于指执行指令使设备实现上述第一方面及上述第一方面的任意一种可能实现提供的方法。第二方面能达到的有益效果可参考第一方面任一实施方式所提供的方法的有益效果,此处不再赘述。
21、第三方面,本技术提供一种计算机可读存储介质,该可读存储介质中存储有指令,该指令被设备执行时,使计算机实现上述第一方面及上述第一方面的任意一种可能实现提供的方法。第三方面能达到的有益效果可参考第一方面任一实施方式所提供的方法的有益效果,此处不再赘述。
22、第四方面,本技术提供一种计算机程序产品,该计算机程序产品在设备上运行时,使设备实现上述第一方面及上述第一方面的任意一种可能实现提供的方法。第四方面能达到的有益效果可参考第一方面任一实施方式所提供的方法的有益效果,此处不再赘述。
本文地址:https://www.jishuxx.com/zhuanli/20240618/24325.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表