一种基于DQN算法的氢能驱动船舶能量管理方法
- 国知局
- 2024-08-01 07:08:02
本发明涉及电气工程与船舶工程交叉领域,具体涉及一种基于dqn算法的氢能驱动船舶能量管理方法。
背景技术:
1、随着全球环境污染和温室气体排放问题日益严重,船舶作为主要的交通工具,其尾气排放不仅包括大量的二氧化碳,还包括硫氧化物、氮氧化物等有害物质,这些排放物对大气、海洋和生态系统都有潜在的危害。
2、为了减少这些排放并推动船舶工业向更加环保的方向发展,各种清洁能源技术已经开始被应用于船舶中。其中,氢能和锂电池作为清洁能源备受关注。氢能作为一种无碳排放的能源,可以提供清洁、高效的动力输出,而锂电池则因其高能量密度和快速充放电的特点,成为了主要的能源存储方式。
3、但是,氢燃料电池和锂电池在实际应用中都存在独特的挑战。例如,氢存储需要特定的容器和压力条件,而锂电池的使用寿命、充放电效率和温度管理都需要特殊考虑。因此,如何在船舶电站中综合利用这两种能源,并且高效、安全地进行能量管理,成为了氢能与锂电池上船应用的技术难题。
4、另外,船舶在不同的航行状态下,能量需求不同。船舶在高速航行和低速航行中,或在重载和轻载状态下,能量的需求和消耗都会有显著差异。因此,需要一个智能的能量管理策略,来解决这些问题。
技术实现思路
1、发明目的:为了克服现有技术中存在的不足,提供一种基于dqn算法的氢能驱动船舶能量管理方法,能够根据船舶的实时状态和环境条件,动态地调整氢能和锂电池的出力,以确保船舶高效、稳定和绿色运行。
2、技术方案:为实现上述目的,本发明提供一种基于dqn算法的氢能驱动船舶能量管理方法,包括如下步骤:
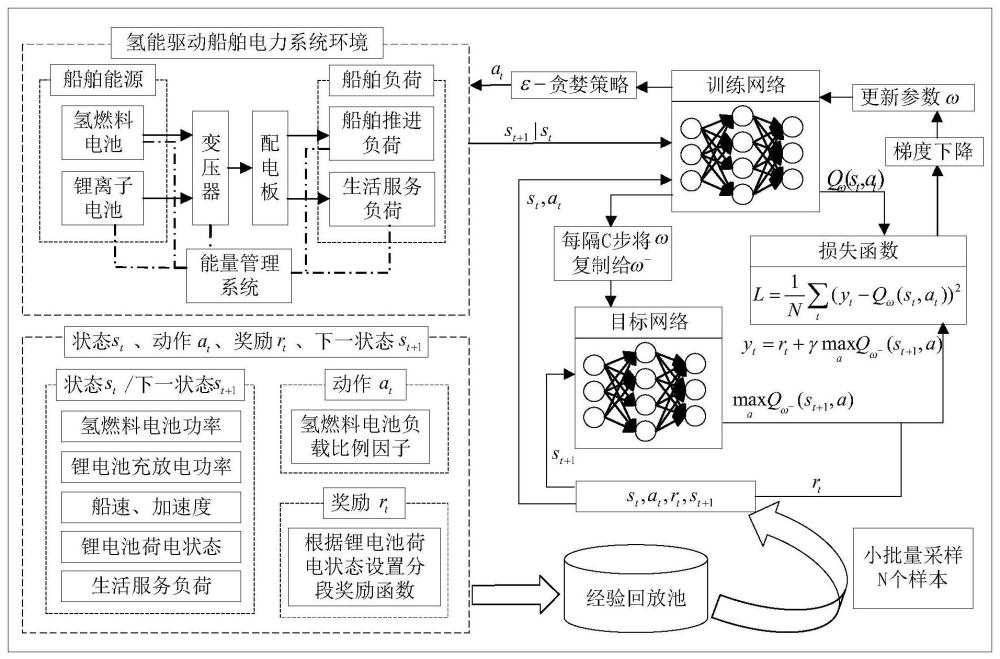
3、s1:基于船舶多工况负荷需求,构建船舶混合动力系统模型;
4、s2:通过实时能量管理系统与船舶混合动力系统以及船舶所处的海洋环境进行持续交互,得到四元组;
5、s3:将四元组存放到经验回放池中,经验回放池采样池内数据形成dqn训练集;
6、s4:将dqn训练集输入到构建好的dqn网络中进行训练;
7、s5:通过实时能量管理系统获取到当前船舶状态,训练好的dqn网络根据当前船舶状态输出船舶能源之间最优分配决策。
8、进一步地,所述步骤s1中船舶混合动力系统模型包括船舶能源模块和船舶负荷模块,所述船舶能源模块包括氢燃料电池模块和锂电池储能模块,所述船舶负荷模块包括推进负荷和生活服务负荷。
9、进一步地,所述船舶混合动力系统模型的表达如下:
10、氢燃料电池模块:
11、发电功率:
12、
13、其中,为氢燃料电池t时段发电功率;ηh为氢燃料电池的发电效率;为在t时间段的耗氢量;eh为氢气能量密度;
14、氢燃料电池功率输出范围:
15、
16、其中,为氢燃料电池在t时段的运行状态;和分别为氢燃料电池的最大和最小出力;ch为氢燃料电池最大储氢容量;
17、锂电池储能模块:
18、充电模型:
19、
20、放电模型:
21、
22、其中,为t时刻锂电池储能容量;为锂电池储能自放电率;为t-1时刻锂电池储能容量;ηch为锂电池储能充电效率;为t时刻充电功率;为t时刻放电功率;为锂电池储能放电效率;
23、锂电池荷电状态区间:
24、socmin<soct<socmax (5)
25、其中,socmin和socmax分别为锂电池荷电状态上下限,soct为锂电池在t时刻的荷电状态;
26、推进负荷:
27、
28、其中,为t时段的船舶推进负荷,vt为t时段船速;c1、c2为推进系数;
29、生活服务负荷:
30、
31、其中,pt为船舶航行过程中t时段总负荷;为t时段生活服务负荷。
32、本发明方案所提出的智能决策系统的核心是开发一个具有高度自适应性和良好经济性的实时能量管理系统(real time energy management system,rt-ems)。混合动力船舶综合电力系统主要由氢燃料电池和锂电池储能系统构成。rt-ems会根据船舶的运行状态来实时调控氢燃料电池和锂电池储能系统提供功率的比例。混合动力船舶的能量调控过程可通过马尔科夫决策过程(markov decision process,mdp)进行表征,此时系统当前的状态只与上一时刻的状态有关。
33、在mdp中,存在一个智能体来执行动作,让其与环境持续交互,从而根据环境的反馈不断改善智能体策略。本方案中可以将rt-ems视为mdp中的智能体,与整个船舶的系统以及船舶所处的海洋环境持续交互,rt-ems会根据当前环境反馈的状态和上一时刻行为决策获得的奖励来决定当前时刻的行为决策。
34、进一步地,所述步骤s2中通过马尔科夫决策过程mdp来表征混合动力船舶的能量调控过程,mdp由五元组(s,a,t,r,g)唯一确定,其中,s为状态空间,包含环境中一切可能的状态;a为动作空间,包含智能体的一切可执行动作;t为状态转移函数,t(s'|s,a)表示智能体在状态s执行动作a后转移至状态s'的概率;r为奖励函数,需要人工设置,对应着优化目标,智能体会根据奖励函数从环境得到反馈的回报值,并基于此优化自身策略;g为折扣因子,取值范围在[0,1)之间,数值越大表示越关注长期的累计奖励,否则表示更注重短期的当前奖励。
35、进一步地,mdp表征混合动力船舶的能量调控过程的具体内容为:
36、作为强化学习的优化对象,智能体的策略可建模为在某一状态下采取某一动作的概率:
37、
38、其中,p(a|s)为在s状态下采取动作a的概率;
39、在一个mdp中,从t时刻至终止状态时所有奖励的加权求和被称为回报,回报的具体计算方式如下:
40、
41、其中gt为t时刻的回报,rt为t时刻的奖励。
42、状态价值函数:
43、vπ(s)=eπ[gt|st=s] (10)
44、其中,vπ表示在mdp中基于策略p的状态价值函数(state-value function),被定义为从状态s出发遵循策略π能获得的期望回报;
45、动作价值函数:
46、在mdp,由于动作存在,需额外定义一个价值动作函数(action-value function):
47、qπ(s,a)=eπ[gt|st=s,at=a] (11)
48、其中,qπ(s,a)表示在mdp遵循策略p时,对当前状态s执行动作a得到的期望回报;
49、状态价值函数和动作价值函数之间的关系:在使用策略π中,状态s的价值等于在该状态下基于策略π采取所有动作的概率与相应的价值相乘再求和的结果:
50、
51、使用策略π时,状态s下采取动作a的价值等于即时奖励加上经过衰减后的所有可能的下一个状态的状态转移概率与相应的价值的乘积:
52、
53、贝尔曼期望方程:
54、通过状态价值函数和动作价值函数之间的关系可以推导出贝尔曼期望方程:
55、
56、进一步地,所述步骤s2中四元组为(st,at,rt,st+1),其中,st和st+1分别表示t和t+1时刻船舶所处的状态,rt表示智能体执行动作at之后环境反馈给智能体的一个奖励值;
57、at表示智能体获取当前船舶状态st后,根据ε-贪婪算法选择出一个船舶能源之间最优分配决策,
58、
59、其中,ε-贪婪策略表示,1-ε概率利用期望奖励最大的动作(此处为氢燃料电池出力比例),以ε概率随机选择一个动作;
60、本发明中mdp提供了dqn所需的决策框架。在dqn中,智能体需要了解当前的状态(来自mdp)并在此基础上做出决策。
61、进一步地,所述四元组(st,at,rt,st+1)中,
62、st表示如下:
63、
64、其中,为t时刻氢燃料电池发电系统输出功率、和分别为t时刻锂电池储能系统的充放电功率、为t时刻船速参考、为t时刻加速度、为t时刻生活服务负荷,soct为t时刻锂电池储能系统荷电状态;
65、at表示如下:
66、采用氢燃料电池负载比例因子作为决策变量,其定义为:
67、
68、其中,phn为氢燃料电池系统最大输出功率;当ratiot等于1时,氢燃料电池系统按最大功率运行,ratiot等于0时,氢燃料电池系统空载运行,ratiot在0到1之间离散化取值,设置为{0,0.1,0.2,0.3,0.4,0.5,0.6,0.7,0.8,0.9,1.0},因此at可表示为:
69、at={0,0.1,0.2,0.3,0.4,0.5,0.6,0.7,0.8,0.9,1.0} (18)
70、rt表示如下:
71、奖励值将根据奖励函数计算获得奖励,函数的设计考虑氢燃料电池系统耗氢量特征,同时确保锂电池储能系统荷电状态维持在安全区间[socmin,socmax]内,具体如下所示:
72、soct+1<socmin或soct+1>socmax
73、rt=-3 (19)
74、0≤soct+1≤socmin
75、
76、其中,|δsocmax|为锂电池储能系统荷电状态变化的最大值;
77、socmin≤soct+1≤socmax荷电状态在安全区间内,奖励函数需要根据氢燃料电池系统耗氢特征的变化设计奖励函数:
78、
79、其中,和β为拟合参数,ratioopt为最优负载比例因子;
80、
81、进一步地,所述步骤s3中将四元组(st,at,rt,st+1)存放到经验回放池中,若经验回放池内样本数量未超过最大经验回放池容量,直接存入样本;若超出最大容量,则删除最早存入样本,存入当前样本。当经验回放池中的样本足够时,经验回放池会随机采样n个样本数据作为dqn训练集。
82、本发明利用dqn训练集来训练dqn目标网络,根据以下公式计算损失函数的值:
83、
84、而目标网络参数则通过间隔c次训练,将训练网络参数ω复制给目标网络参数ω-,通过以上训练直到损失函数收敛。
85、训练网络参数ω复制给目标网络参数ω-的原理为:dqn训练规则,训练网络计算损失函数中的qω(st,at)项,目标网络计算损失函数中的项,两者同时更新非常不稳定,所以先固定住目标网络,使用一套比较旧的参数;训练网络每一步都更新,每隔c步两者同步一次。
86、所述步骤s4中dqn网络的具体训练过程为:
87、1)对dqn网络中的经验回放池、训练网络和目标网络参数进行初始化;
88、2)dqn网络中的智能体与系统所处的海洋环境持续交互,每次交互时会得到一个四元组(st,at,rt,st+1),其中st为当前t时刻的系统所处的状态,其中包括t时刻的氢燃料电池功率、锂电池充放电功率、船速、加速度、锂电池荷电状态、生活服务负荷;at为智能体在获取到状态st后,会根据ε-贪婪策略选择出一个氢燃料电池负载比例因子;rt为智能体执行at后,系统环境会反馈一个奖励给智能体,具体奖励在(19)-(22)式给出;st+1表示为t+1时刻的系统所处的状态;
89、3)将dqn智能体与系统所处的海洋环境交互得到的四元组存储到经验回放池中;经验回放池存储原则为:若经验回放池中的元组数量未超过经验回放池的容量上限,直接将四元组存储到经验回放池中;若经验回放池中的元组数量超过经验回放池的容量上限,则删除最早存储的四元组,存入新的四元组;
90、4)当经验回放池中的样本达到指定值时,经验回放池会随机小批量采样n个样本数据作为dqn训练集,将数据输入到训练网络和目标网络中进行训练,并根据公式来计算损失函数,其中γ为折扣因子,0≤γ≤1,γ越趋于0表示越关注短期奖励,反之则表示越关注长期奖励;qω(st,at)为基于策略π在状态st下智能体执行动作at后dqn训练网络输出的期望回报,ω为训练网络参数;为基于策略π在状态st+1下智能体执行动作a后dqn目标网络输出的最大期望回报,ω为目标网络参数;
91、5)使用梯度下降法根据损失函数值来更新dqn训练网络参数ω;
92、6)当dqn训练网络参数ω更新次书达到c的倍数时,将训练网络参数ω复制给目标网络参数ω-;
93、7)重复4)-6),直至损失函数值收敛。
94、本发明利用dqn强化学习算法,设计了一种氢燃料电池和锂电池混合动力船舶能量管理方法,不仅保证了氢能驱动船舶安全稳定运行,还可以提升环境友好性。
95、本发明方案具有以下特点:
96、充分挖掘氢燃料电池和锂电池的工作特性,基于船舶多工况负荷需求,构建船舶混合动力系统模型。
97、利用dqn算法进行深度强化学习,根据当前负荷需求和能源存储状态,实时优化氢燃料电池和锂电池的能源出力。
98、根据船舶的历史工况和当前环境条件,通过dqn强化学习算法进行自我学习和调整,为船舶选择最佳的能量供应策略。
99、有益效果:本发明与现有技术相比,具备如下优点:
100、1、本发明考虑了船舶运行过程中能源需求的复杂性和动态变化,克服了传统能源管理系统在氢能与锂储能协调上的局限性,实现了最优的能效比和性能输出。
101、2、本发明通过精确的能源调控,充分考虑了航海经济性与环境可持续性的和谐统一,确保船舶在不同的运行条件下都能保持能源利用最大化效益。
102、3、本发明提供的dqn算法可以在不断的学习和自我优化过程中提高船舶系统对于不确定性因素的应对能力,实现能源输出的动态调整,确保动力系统在各种海况下的稳定性和可靠性。
103、4、本发明通过精确的能源调控,船舶得以在保持其速度与性能的核心条件不受影响的同时,显著延伸了其航行距离。
104、5、本发明铺垫了船舶自动化与智能化航行的未来之路,促进了航行效率大幅度提升,为船舶控制系统的智能升级和自主决策能力的增强奠定了坚实的基础。
本文地址:https://www.jishuxx.com/zhuanli/20240722/226310.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。