学习过程中鲁棒反馈控制的多面体策略优化的系统和方法与流程
- 国知局
- 2024-07-30 09:22:41
本发明总体上涉及系统控制,并且更具体地,涉及在学习过程中用于具有部分已知动力学的系统的鲁棒优化和反馈控制的方法和设备。
背景技术:
1、虽然机器学习和人工智能领域在过去十年中取得了突破性的进步,但这些技术在物理或机器人系统中的应用有限。例如,大多数机器人系统仍然使用经典的基于模型的方法来控制复杂的过程。这可以归因于表征大多数现有学习方法的一些不希望出现的特征,如缺乏鲁棒性或样本效率差。在学习过程中保证物理系统的控制的鲁棒性是很重要的,因为精确表示物理动力学的(学习)模型很少。
2、强化学习(rl)是一种解决顺序决策问题的学习框架,其中“代理”或决策者通过与通常未知的环境交互来学习策略以优化长期奖励。在每次迭代或时间步长中,rl代理获得关于其动作的长期性能的评估反馈(称为奖励或成本),使其能够改进后续动作的性能。
3、无模型强化学习(rl)方法由于其无需复杂的动力学模型即可构建控制策略的能力而广为普及。然而,大多数无模型rl算法不能包含关键的系统特性,如对外源干扰的鲁棒性或甚至渐近稳定性。相反,可以逐渐灌输这些期望的特性的基于模型的rl(mbrl)严重依赖底层的动力学模型,并且当模型不匹配很大时,表现出较差的性能,有时甚至导致灾难性的故障。这个问题与其中了解真正的动力学非常困难的许多不同的场景非常相关。这适用于其中机器人被认为应该在运行期间与新对象进行交互并且因此不能有交互的先验模型的许多机器人系统。
4、在mbrl技术的策略优化阶段,优化方法应允许在学习模型中加入不确定性,并确保所得到的控制器针对部分已知系统的控制的鲁棒性。这通常很难实现。这是需要了解和表示系统动力学中存在的不确定性以及在策略优化步骤中开发不确定性的问题。然而,在机器人、自动驾驶等领域中,学习控制器的许多应用都需要这一点。
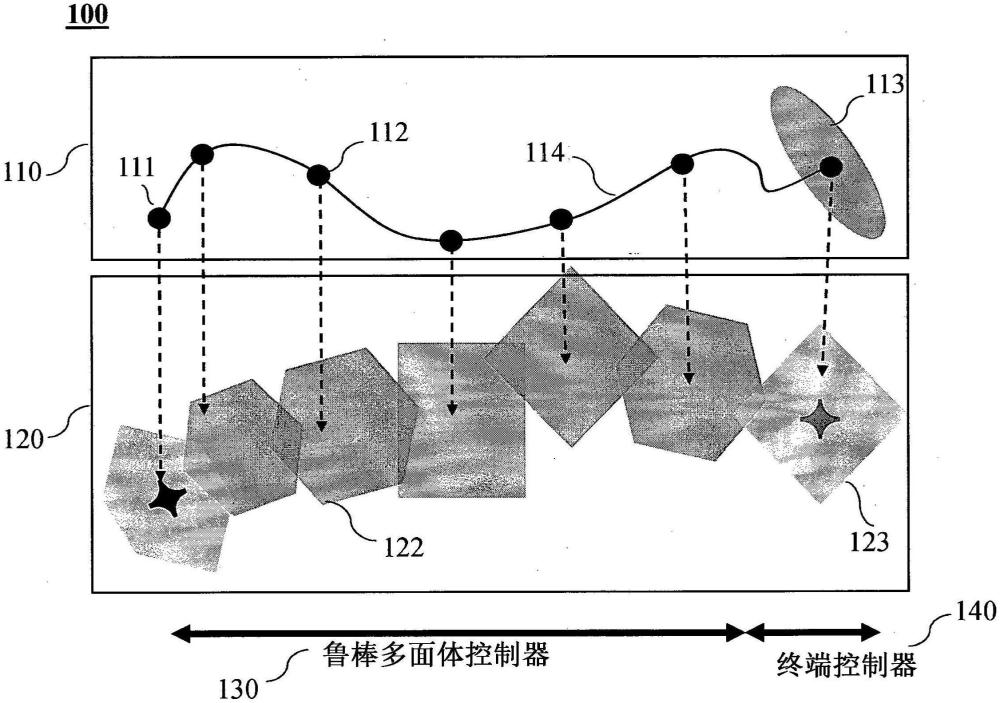
5、大多数基于学习的控制器设计的技术在系统上实现时都存在性能不佳的问题,因为在学习过程中不能以原则性的方式保证系统收敛到期望的系统状态。在非线性系统的稳定控制器的设计中的现有工作曾使用控制器的吸引盆(或吸引域)的概念来保证非线性系统的收敛和稳定性。例如参见tedrake,russ等人所著“lqr-trees:feedback motionplanning via sums-of-squares verification(lqr树:通过平方和验证进行的反馈运动规划)”国际机器人研究杂志29.8(2010):1038-1052。由于习得模型中的不确定性,在学习阶段期间计算非线性控制器的吸引域是不可行的。然而,可能不需要设计吸引域来覆盖机器人的整个状态空间。设计具有已知吸引域的终端控制器可能就足够了。然后将控制问题分解为将系统鲁棒移动到终端控制器的吸引子盆中的任务,于是终端控制器可以将系统状态调节到期望的终端状态。
6、利用这样的理解,可以设计能够在控制器设计过程中包含系统动力学不确定性并可靠地将系统从初始状态移动到终端控制器的吸引子盆的控制器是很重要的。然而,在控制器设计过程中包含不确定性要求人们应该能够以适合控制器计算的方式估计并表示不确定性。
7、为了保证动力学系统总是收敛到期望的终端状态,我们需要设计终端控制器,其保证在系统到达系统的终端盆时,将系统调节到期望的终端状态。非线性系统的控制器的吸引子盆的估计无论从计算上还是从算法上通常都是非常困难的问题。然而,有效地估计控制器的吸引子盆可以允许我们快速地稳定和学习期望的行为。
8、因此,需要可以在模型学习过程中开发不确定性的适当表示并设计控制器来在学习过程中鲁棒地控制系统以获得期望的性能的鲁棒策略优化和控制器设计技术。
技术实现思路
1、一些实施方式的目的是提供在学习过程中针对具有部分已知动力学的系统的数据驱动的控制策略鲁棒优化的系统和方法。另外地或另选地,一些实施方式的目的是提供可以学习部分已知系统的不确定性的多边形表示的这样的系统和方法。另外地或另选地,一些实施方式的目的是提供一种可以使用具有局部稳定性保证的多面体不确定性表示进行鲁棒优化来计算鲁棒多面体控制器的系统和方法。另外地或另选地,一些实施方式的目的是提供一种能够学习针对底层系统的终端控制器的吸引域的系统和方法。另外地或另选地,一些实施方式的目的是提供一种在终端控制器的吸引域中使用终端控制器并且在其他地方使用多面体控制器来控制底层动力学系统的系统和方法。
2、本公开的一些实施方式提供了一种新的鲁棒策略优化机制,其可以通过学习残差(真实动力学的未建模分量)系统可能存在于的多面体来解决模型不匹配问题。这种基于贝叶斯回归的残差动力学的多面体过度近似,使得通过求解可处理的半确定规划(sdp)来构建鲁棒策略成为可能。
3、根据本公开的一些实施方式,提供了一种新的计算机实现方法,用于通过使用直接从数据中学习的贝叶斯多面体表示模型不确定性来学习基于模型的强化学习的鲁棒策略。该方法的算法允许满足输入和状态约束。进一步地,在习得的贝叶斯多面体的假设下,将该新方法安排成具有局部稳定性保证的多面体控制器中。作为设计鲁棒多面体控制器的一个示例,本公开描述了估计终端控制器的接取池,从而获得更好的数据效率和保证的稳定性。
4、该抛出策略是从系统输出数据中学习的,其作用是将系统动力学传播到指定的目标状态。在目标状态处,我们采用接取策略并利用监督式学习来估计相应的接取池,在该接取池内任何状态都保证(以高概率)能够稳定至目标状态。因此,当抛出策略将状态驱动到该接取池内时,接取策略将系统驱动到目标状态。我们的方法的一个主要优点是我们还可以加入状态和输入约束。所提出的算法在倒立摆和欠驱动机器人系统上进行验证。
5、一些实施方式是基于这样的认识,即,系统的动力学模型的不准确性会导致用于设计动力学系统的控制器的动力学系统的预测中的复合误差。为了以不准确的动力学模型获得期望的动力学系统的行为,通常需要量化不准确性,并且然后在控制器设计中使用不准确性的估计,以便能够在运行期间补偿这些不准确性。
6、当前公开的一些实施方式基于这样的认识,即,对于大多数物理模型,预测模型可以使用领域知识而可用或可以使用物理引擎创建。这些模型通常是不准确的,并且与真实系统的物理观测结果不完全匹配。然而,这些模型可以用来计算控制真实系统的初始控制器。一些实施方式基于这样的认识,即,这样的控制器将导致真实系统上的性能较差,但可以用于从真实系统收集数据。然后,该数据可以用来改进针对真实系统的预测模型。
7、当前公开的一些实施方式基于这样的认识,即,使用控制器从真实系统收集的数据可以用于计算真实系统与系统的模型之间的观测值之间的差异。可以使用机器学习模型从收集的数据学习真实系统与系统的已知模型之间的差异。当前公开的一些实施方式基于这样的认识,即,可以使用针对同一者的不同表示以不同的方式量化机器学习模型的不确定性。
8、当前公开的一些实施方式基于这样的认识,即,使用不确定性的线性表示或多面体表示可以允许我们使用来自半确定规划(sdp)的工具来设计针对具有已知不确定性的动力学模型的鲁棒反馈控制器。这样的鲁棒控制器可以在保证对模型不确定性的局部鲁棒性的情况下被设计。当前公开的一些实施方式基于这样的认识,即,可以使用线性贝叶斯优化和贝叶斯回归方法的针对预测的预定义置信区间来获得习得模型中不确定性的多面体表示。
9、本公开的一些实施方式基于这样的认识,即,可能不能在系统无法到达的状态空间的部分中纠正系统的动力学模型。在实现计算的控制轨迹时,观测状态与计算的标称轨迹之间的误差随着轨迹的范围增加而增加。因此,系统永远不会访问期望的终端状态的邻域。一些实施方式基于这样的认识,并且因此我们设计了一种终端控制器,一旦系统进入终端控制器的吸引子盆,该终端控制器将系统状态调节到期望的系统状态到终端状态。
10、本公开的一些实施方式基于这样的认识,即,大多数动力学系统将需要稳定的终端控制器,以确保动力学系统可以被调节并保持在系统的期望的终端状态。然而,除了终端控制器外,还需要估计终端控制器的其中终端控制器保证稳定的吸引子盆。本公开的一些实施方式基于这样的认识,即,根据系统的终端状态的模型是否已知,可以使用无模型或基于模型的方式来设计用于动力学系统的终端控制器。如果终端状态的模型是未知的,终端控制器也可以使用无模型方法,如比例、积分和导数(pid)控制器,来进行计算。
11、本公开的一些实施方式基于这样的认识,即,终端控制器的吸引子盆可以通过从终端状态周围的邻域采样状态并训练分类器来预测采样状态是否可以调节到期望的终端状态来进行估计。这种学习过程可以通过首先在终端状态的邻域中采样状态,并且然后观察系统的向期望终端状态的稳态收敛行为来设计。在收集数据和从初始状态的收敛标记之后,分类器可以被训练为预测从任何初始状态的收敛性,从而提供对终端控制器的吸引子盆的估计。
12、本公开的一些实施方式基于这样的认识,即,最终控制器设计使用鲁棒的、基于sdp的控制器将系统状态推送到控制器的吸引子盆,并且然后使用由习得的分类器预测的终端控制器。
13、根据本发明的一些实施方式,提供了一种控制器,以用于通过学习系统的动力学来生成控制系统的策略。所述控制器可以包括:接口控制器,该接口控制器被配置为从设置在所述系统上的传感器获取测量数据;至少一个处理器;以及具有计算机实现的指令存储在其上的存储器,该计算机实现的指令包括模型学习模块和策略学习模块,当由所述至少一个处理器执行时,所述计算机实现的指令使所述控制器执行以下步骤:向所述存储器提供由系统的动力学的已知部分和系统的动力学的未知部分表示的非线性系统模型;通过基于标称策略和关于状态的噪声项使用系统传感器测量系统的动力学来收集系统的状态;通过收集系统的数据来估计控制输入的集合和系统的状态的集合的序列,其中,数据包括系统状态、应用的控制输入和系统状态变化的集合,其中,每个控制输入通过标称策略和附加噪声项计算;利用收集到的系统的数据学习多面体系统,以用于利用线性概率回归模型近似系统的动力学的未知部分;通过在终端状态的邻域内采样初始状态并通过监督学习估计吸引子盆来估计终端控制器的吸引子盆;以及利用估计的多面体系统生成多面体策略,以将系统从初始状态驱动到终端控制器的吸引子盆。
14、进一步地,根据一些实施方式,提供了一种计算机实现的方法,以用于通过学习系统的动力学来生成控制系统的策略。基于计算机实现的方法要执行的步骤包括:从设置在所述系统上的传感器获取测量数据;向存储器提供由系统的动力学的已知部分和系统的动力学的未知部分表示的非线性系统模型;通过基于标称策略和关于状态的噪声项使用系统的传感器测量系统的动力学来收集系统的状态;通过收集系统的数据来估计控制输入的集合和系统的状态的集合和序列,其中,数据包括系统状态、应用的控制输入和系统状态的变化的集合,其中,每个控制输入通过标称策略和附加的噪声项计算;利用收集到的系统的数据学习多面体系统,以用于利用线性概率回归模型近似系统的动力学的未知部分;通过在终端状态的邻域内采样初始状态并通过监督学习估计吸引子盆来估计终端控制器的吸引子盆;以及利用估计的多面体系统生成多面体策略,以将系统从初始状态驱动到终端控制器的吸引子盆。
15、将参照附图进一步解释当前公开的实施方式。所示出的附图不一定是按比例绘制的,而是通常将重点放在说明当前公开的实施方式的原理上。
本文地址:https://www.jishuxx.com/zhuanli/20240730/149268.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表