一种基于深度强化学习的视觉端到端车辆跟随方法
- 国知局
- 2024-07-30 09:20:46
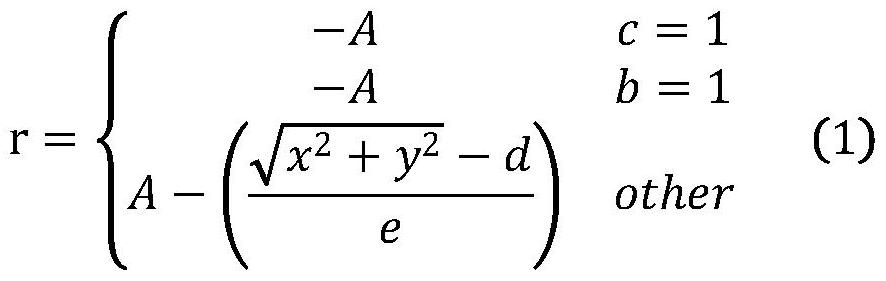
本发明属于计算机视觉和智能控制领域,具体涉及一种基于深度强化学习的视觉端到端车辆跟随方法。
背景技术:
0、技术背景
1、车辆跟随的目标是根据获取的环境状态信息自主控制跟随车辆的速度,从而与前车保持特定距离。随着汽车工业的快速发展使得自动驾驶技术受到越来越多的关注。车辆跟随行为将增强车辆的安全驾驶能力、交通效率和道路安全。此外,许多车辆跟随模型已被广泛应用于不同领域,如交通仿真和自动驾驶。目前,大多数cf模型需要直接获取车辆的位置、速度和加速度等高维特征作为输入,这对于无通信环境并不适用。另一些车辆跟随模型采用图片或点云等低维特征作为输入,但需集成车辆跟踪和相机控制两个独立的子任务。然而,这两个子任务都需要大量的人工参与图像标记和复杂的协调程序,此外,相机控制的好坏也至关重要。他可能会在现实世界中进行许多高昂的试错。
2、在数据驱动的车辆跟随方法方面,具有真实驾驶体验的跟随模型被构建出来,并指出了传统跟随模型不适用于时变的交通条件。随之计算机视觉的发展,基于图像的车辆跟随方法受到了极大的关注。该方法利用一张图像来预测前车的位置,并利用该位置控制车辆实现跟随任务。这一方法构建低级控制和高级命令之间的映射关系,从而将从相机中获得原始的图像映射到转向命令。然而这些解决方案都是分别设计车辆感知模块和控制模块,这将对模块间的联调带来巨大挑战和高昂的成本。本发明方法与上述方式完全不同,它以端到端的形式直接映射图像帧到动作,且不需要大量的人力来进行图像标记和复杂的联调。
技术实现思路
1、本发明针对技术背景中提到的问题,基于深度强化学习的视觉端到端车辆跟随方法。该方法以跟随者的第一人称视角作为输入,并且不依赖于高维特征(例如速度、位置、加速度等),因此即使在非通信环境中也能有效工作。此外,构建了空间-注意力-时间框架提取和合并视频帧之间的时空特征,并立即输出跟随者的运动动作(如油门、刹车)。具体包括以下步骤:
2、(1)仿真环境构建,使用carla作为仿真环境,模拟环境中的静态物体,如基础设施、建筑物和植被,以及移动物体,如车辆和行人。对于cf任务,需要生成跟随车辆和前行车辆,以保证它们在道路上运行。为了获取图像信息,在跟随者上安装了rgb摄像头。此外,还生成了碰撞检测传感器来确定跟随者是否与任何物体发生碰撞,并且生成跟随者的3d边界框用于车道入侵检测。
3、(2)环境和车辆运动增强设计,使用颜色生成器生成随机颜色,以增加前车外观的多样性,从而提高跟随不同颜色的不同车辆的泛化能力。随机生成前车的运动轨迹,增加运动多样性,从而提高cf模型的整体泛化性,使其更容易部署和推广。随机设置carla中的天气参数,例如更改阳光、下雨、大雾、阴天等参数的值。
4、(3)构建状态空间,跟随者通过以第一人称视角视频帧作为输入来准确地跟随前方车辆,状态空间由连续的rgb视频帧组成,提供跟随者在每个时间步观察到的视觉信息。
5、(4)构建动作空间,采用油门和刹车作为动作空间。具体来说,油门和刹车分为23类,为每一类定义一个离散动作来表示油门和刹车的值。制动力范围为0至1,其中0表示不制动,1表示完全制动。考虑到实际驾驶中很少采用完全制动,因此制动力限制在0.6-0范围内,制动力从0.6开始,每一步减少0.1。另一方面,油门值在0-1范围内,其中0代表不踩踏油门,1代表完全踩踏油门。由于实际驾驶中很少使用全油门,因此油门值被限制在0-0.8范围内,从0开始,每一步增加0.05。值得注意的是,在实际驾驶中,驾驶员使用同一脚踩油门和踩刹车。因此,动作空间中的油门和刹车不能同时大于零。
6、(5)奖励函数设计,设计的奖励函数能够提供有效的反馈来评估跟随者的动作价值。定义了一个平行于地面的二维局部坐标系s,y轴从跟随者的左侧指向右侧,x轴垂直于y轴并指向跟随者的前部。坐标系原点位于跟随者中心。前车在坐标系s中的位置用(x,y)表示。奖励函数如公式1所示:
7、
8、其中a>0,e>0,d>0为超参数,c=1表示跟随者与其他物体碰撞,跟随者与前车之间的跟随距离超过最大或小于最小跟车距离;b=1表示跟随者越过车道边界。
9、(6)构建强化学习网络框架,框架由空间-注意力-时间模块组成,并以actor网络和critic网络为主体,其中,actor和critic共享时空特征提取模块,时空特征提取模块以卷积和循环神经网络为基本构建单元,中间引入改进的高效自注意力机制。非共享部分采用全连接网络构建,并使用relu作为激活函数。
10、(7)构建预处理网络及数据集,采样dark-net53作为预处理网络架构并加载预训练权重。构建数据集,通过从仿真中采样的rgb视频,并利用仿真环境中的3d包围框对视频帧进行标注生成标签,从而制作预处理数据集。
11、(8)训练预处理网络,将预处理数据集中的视频帧输入到预处理网络进行训练,将批大小设置为32,采用adam优化预处理网络,学习率设置为0.0001,在200个回合的训练后保存权重参数以获取最终预训练网络。
12、(9)训练车辆跟踪强化学习网络,实时从carla环境中获得的跟随者第一人称视角视频帧,逐帧输入预训练网络,然后生成特征图,将特征图输入强化学习网络,并输出动作和动作价值。仿真环境执行动作,并根据奖励函数反馈奖励。学习率设置为0.0001,基于奖励值采用a3c算法优化网络模型,记录每一步的奖励,绘制曲线,观察曲线收敛后保存网络模型参数。
13、(10)车辆跟随,将跟随者第一人称视角视频帧输入预训练网络模型,随后输入强化学习模型的actor网络,输出动作,跟随者执行动作,并反馈新的视频帧,从而实现车辆跟随。
14、进一步,所述的空间-注意力-时间模块由三个主要组件组成:空间特征提取器、时间特征提取器和决策器。
15、进一步,空间特征提取器由3×3、5×5的卷积层和8个自注意力层组成。卷积层和自注意力层之间采用多个卷积下采样处理。
16、进一步,时间特征提取器由lstm循环神经网络模型构成。空间特征提取器处理后的特征向量被用作lstm循环神经网络的输入,通过输入门、遗忘门和输出门,最终能够从车辆跟随任务中观察到的信息中提取时间特征。
17、进一步,决策器由actor和critic网络组成,这两个网络都由全连接层组成,并共享相同的输入特征。critic网络用于逼近状态价值函数,而actor网络用于输出动作的策略分布,跟随者根据分布选择动作。
18、根据本文中提出的技术方案,我们实现了在无通信环境下的端到端的汽车跟随,其中车辆将视觉观察作为输入并生成相应的控制信号作为输出。提出的空间-注意力-时间框架擅长从视频帧中提取和集成视觉时空特征,通过定制的奖励函数和强化学习训练减少了对大量图像标记和复杂协调的需求,并显着提高了无通信环境中视觉帧到动作预测的准确性。
技术特征:1.一种基于深度强化学习的视觉端到端车辆跟随方法,其特征在于,包括以下步骤:
2.根据权利要求1所述的一种基于深度强化学习的视觉端到端车辆跟随方法,其特征在于,步骤6)中的空间-注意力-时间模块,包括空间特征提取器、时间特征提取器和决策器三个组件。
3.根据权利要求2所述的一种基于深度强化学习的视觉端到端车辆跟随方法,其特征在于,空间特征提取器由3×3、5×5的卷积层和8个自注意力层组成;此外,卷积层和自注意力层之间采用多个卷积下采样处理;这种注意力机制在原始rgb图像在特征提取网络后进行卷积下采样处理,得到大小为9×9的特征图,这意味着原始图像被划分为9×9网格;与网格相对应的每个图像被分别编码到特征图中;此时,使用相对位置编码来记录特征图的位置信息,然后对特征图进行压平;这些扁平化的特征图被输入到三个独立的全连接层中,以获得索引q、键k和值v;q乘以k,使用softmax激活函数得到注意力权重矩阵w;将位置信息添加到权重w后,乘以v,得到权重处理后的特征值c;最后将特征值c作为注意力层的输出向量;时间特征提取器由lstm循环神经网络构成,决策器由全连接层构成。
4.根据权利要求2所述的一种基于深度强化学习的视觉端到端车辆跟随方法,其特征在于,时间特征提取器由lstm循环神经网络模型构成;空间特征提取器处理后的特征向量被用作lstm循环神经网络的输入,通过输入门、遗忘门和输出门,最终能够从车辆跟随任务中观察到的信息中提取时间特征。
5.根据权利要求2所述的一种基于深度强化学习的视觉端到端车辆跟随方法,,其特征在于,决策器由actor和critic网络组成,这两个网络都由全连接层组成,并共享相同的输入特征;critic网络用于逼近状态价值函数,而actor网络用于输出动作的策略分布,跟随车辆根据分布选择动作。
技术总结本发明公开了一种基于深度强化学习的视觉端到端车辆跟随方法,利用跟随者的第一视角观察作为输入,并生成相应的控制信号作为输出。我们构建了空间‑注意力‑时间框架,以实现从视觉到动作的高精度映射。为了提升跟随者在非通信场景中的性能,提出了定制的奖励函数和环境增强技术。跟随者使用了异步优势演员‑评论家算法在3D环境中进行训练和测试。在面对随机路径、恶劣天气、多样颜色和前车纹理的情况下,该方法展现出了出色的泛化能力。对车辆跟随模型的可解释性分析表明,显著增强模型对障碍物和物体位置的关注。对空间‑注意力‑时间框架进行了消融研究,阐明每个模块对跟随前车的贡献,进一步证明了所提方法在跟踪性能方面的卓越性。技术研发人员:刘海滨,李明飞,谢丰,夏铭浩,董浩受保护的技术使用者:北京工业大学技术研发日:技术公布日:2024/7/18本文地址:https://www.jishuxx.com/zhuanli/20240730/149116.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表