信息显示方法、装置、设备和存储介质与流程
- 国知局
- 2024-07-31 22:41:14
本发明涉及图像处理,尤其涉及一种信息显示方法、装置、设备和存储介质。
背景技术:
1、随着人工智能技术的发展,语音识别、声纹识别、图像识别以及机器翻译等技术逐渐成为研究的热点。其中,声纹识别技术以其独特的优势,如用户友好性、隐私保护等,在身份认证、安全防范等领域有着广泛的应用前景。
2、现有技术中,往往只关注语音的识别和声纹的提取,而且对于多语种的场景,通常是通过翻译设备对语音进行翻译后再播放。因此,上述方式无法实现翻译信息的可视化,而且无法将翻译信息和用户的身份进行结合。
技术实现思路
1、本发明提供一种信息显示方法、装置、设备和存储介质,用以解决现有技术中翻译信息无法实现可视化,且无法将翻译信息和用户的身份进行结合的缺陷,实现了将翻译信息通过ar眼镜可视化显示,并将翻译信息和用户的身份进行结合的目的。
2、本发明提供一种信息显示方法,应用于ar眼镜,所述方法包括:
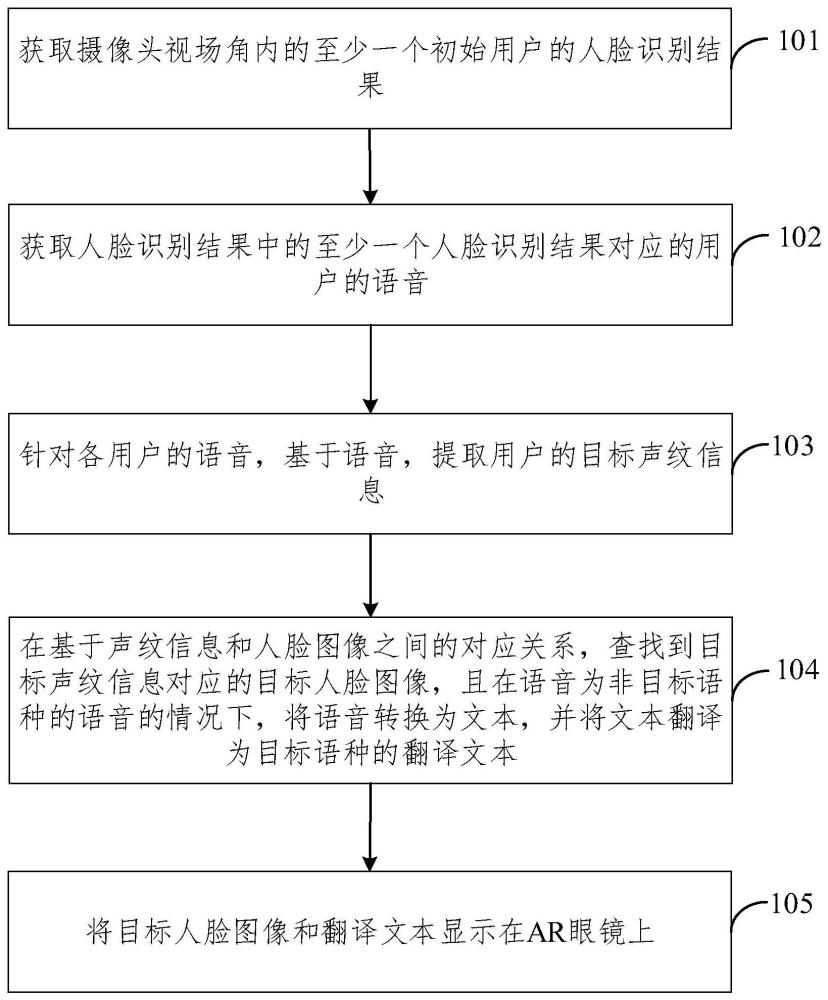
3、获取摄像头视场角内的至少一个初始用户的人脸识别结果;
4、获取所述人脸识别结果中的至少一个人脸识别结果对应的用户的语音;
5、针对各所述用户的语音,基于所述语音,提取所述用户的目标声纹信息;
6、在基于声纹信息和人脸图像之间的对应关系,查找到所述目标声纹信息对应的目标人脸图像,且在所述语音为非目标语种的语音的情况下,将所述语音转换为文本,并将所述文本翻译为目标语种的翻译文本;
7、将所述目标人脸图像和所述翻译文本显示在所述ar眼镜上。
8、根据本发明提供的一种信息显示方法,所述方法还包括:
9、获取至少一个第一样本声纹信息和至少一个样本人脸图像;
10、将各所述第一样本声纹信息和各所述样本人脸图像输入预先训练的匹配模型,得到所述匹配模型输出的各所述第一样本声纹信息对应的样本人脸图像。
11、根据本发明提供的一种信息显示方法,所述方法还包括:
12、获取目标场景下包含至少一个第一样本用户的人脸的样本图像,并获取所述目标场景下采集的第一目标样本语音,所述第一目标样本语音包括至少一个第一样本用户的样本语音;
13、基于所述样本图像进行人脸识别,得到至少一个样本人脸识别结果;
14、获取所述目标场景下采集的第一目标样本语音,所述第一目标样本语音包括至少一个第一样本用户的样本语音;
15、提取各所述样本语音对应的第二样本声纹信息;
16、基于各所述样本人脸识别结果和各所述第二样本声纹信息对初始匹配模型进行无监督训练,以调整所述初始匹配模型的相关度系数,得到所述匹配模型,所述相关度系数用于表征所述样本人脸识别结果和所述第二样本声纹信息的匹配度。
17、根据本发明提供的一种信息显示方法,所述获取目标场景下包含至少一个第一样本用户的人脸的样本图像,并获取所述目标场景下采集的第一目标样本语音,包括:
18、确定在所述目标场景下所述摄像头视场角内的所述第一样本用户的第一数量;
19、获取所述目标场景下采集的第二目标样本语音;
20、基于第二目标样本语音,采用声源定位算法确定所述第一数量的第一样本用户中说话用户的第二数量;
21、基于所述第二数量,调整所述摄像头的视场角,并调整麦克风阵列中处于工作状态的麦克风的数量和位置,调整完成后采集新的第二目标样本语音;
22、基于所述新的第二目标样本语音确定至少一个语音分离结果和各所述语音分离结果对应的语音质量评价值;
23、在所述语音质量评价值小于阈值时,返回至调整摄像头的视场角,并调整麦克风阵列中处于工作状态的麦克风的数量和位置的步骤,直至所述语音质量评价值大于或等于所述阈值;
24、基于调整后的摄像头获取所述目标场景下包含至少一个第一样本用户的人脸的样本图像,并基于调整后的麦克风阵列获取所述目标场景下采集的第一目标样本语音。
25、根据本发明提供的一种信息显示方法,所述基于各所述样本人脸识别结果和各所述第二样本声纹信息对初始匹配模型进行无监督训练,包括:
26、确定各所述人脸识别结果的质量得分;
27、基于各所述样本人脸识别结果、各所述质量得分、各所述第二样本声纹信息和各所述语音质量评价值对所述初始匹配模型进行无监督训练。
28、根据本发明提供的一种信息显示方法,所述基于所述新的第二目标样本语音确定至少一个语音分离结果,包括:
29、对所述新的第二目标样本语音中所述说话用户的声源所在的位置的样本语音进行增强,得到增强后的样本语音;
30、对所述增强后的样本语音进行语音分离,得到所述至少一个语音分离结果。
31、本发明还提供一种信息显示装置,包括:
32、获取模块,用于获取摄像头视场角内的至少一个初始用户的人脸识别结果;
33、所述获取模块,还用于获取所述人脸识别结果中的至少一个人脸识别结果对应的用户的语音;
34、提取模块,用于针对各所述用户的语音,基于所述语音,提取所述用户的目标声纹信息;
35、转换模块,用于在基于声纹信息和人脸图像之间的对应关系,查找到所述目标声纹信息对应的目标人脸图像,且在所述语音为非目标语种的语音的情况下,将所述语音转换为文本;
36、翻译模块,用于将所述文本翻译为目标语种的翻译文本;
37、显示模块,用于将所述目标人脸图像和所述翻译文本显示在所述ar眼镜上。
38、本发明还提供一种电子设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述程序时实现如上述任一种所述信息显示方法。
39、本发明还提供一种非暂态计算机可读存储介质,其上存储有计算机程序,该计算机程序被处理器执行时实现如上述任一种所述信息显示方法。
40、本发明还提供一种计算机程序产品,包括计算机程序,所述计算机程序被处理器执行时实现如上述任一种所述信息显示方法。
41、本发明提供的信息显示方法、装置、设备和存储介质,通过获取摄像头视场角内的至少一个初始用户的人脸识别结果,并获取人脸识别结果中的至少一个人脸识别结果对应的用户的语音,针对各用户的语音,可以提取该用户的目标声纹信息,在基于声纹信息和人脸图像之间的对应关系,查找到该目标声纹信息对应的目标人脸图像,且该语音为非目标语种的语音时,会将语音转换为文本,并将文本翻译为目标语种的翻译文本,从而将目标人脸图像和翻译文本显示在ar眼镜上。一方面,可以将翻译文本显示在ar眼镜上,可以实现翻译文本的可视化,另一方面,在显示翻译文本的同时,还会基于识别出的人脸识别结果这一生物特征和声纹这一生物特征,显示当前正在说话的用户的目标人脸图像,从而可以将翻译文本和正在说话的用户的身份进行结合,实现了说话人的身份识别功能。另外,在多人会话的场景中,通过语音分离技术,将每个说话者的人脸图像和翻译信息进行显示,还可以提高在多人会话等复杂场景下,说话人身份识别的准确性。
本文地址:https://www.jishuxx.com/zhuanli/20240730/194123.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。