一种跨时序融合记忆网络的交通事件检测方法
- 国知局
- 2024-07-31 22:44:01
本发明属于智能视频处理,具体涉及一种跨时序融合记忆网络的交通事件检测方法。
背景技术:
1、在交通场景中,前置摄像头记录司机的“第一人称”或“自我中心”视角,这种自我为中心的视频已广泛应用于道路安全预警、导航、端到端自动驾驶、交通流管理和行人保护等应用。为了确保交通安全,不仅需要准确识别和定位附近的物体,还需要迅速识别和定位发生的异常事件,尤其是交通事故,以便采取及时措施来规避危险。交通事件检测与交通视频异常检测任务有着密切的关系。不同的是交通事件涉及碰撞、撞车和事故情况,而视频异常比事故情况包含的范围更广。交通事件呈现长尾分布,大多数驾驶场景属于少数常见情况,但几乎无限的罕见情况也可能发生。因此,安全驾驶系统需要在常见和罕见情境下准确识别和响应。传统人工报告事故数据的方法虽然提供了有价值信息,但存在及时性和可靠性问题。
2、为解决这些挑战,计算机视觉技术在交通事件检测中发挥关键作用。为了解决交通事件/异常检测中的长尾分布问题,基于多实例学习(mil)的弱监督框架,提出了一些分段级方法。他们使用高级类别标签直接学习每个视频片段的异常分数。已经提出了一些其他帧级方法,它们使用预测模型进行车辆和行人的异常检测。这些帧级方法通常通过深度学习模型根据先前的帧构造当前帧。
3、在dota数据集中针对行车记录的驾驶视频,通过给定观察帧窗口将交通事件检测定义为时间窗口和空间区域的准确定位。由于公式的差异,交通事件检测需要在视频帧中使用不同的时间关系模型。由于交通事件帧在视频序列中的比例通常较小,加上光照、天气条件以及碰撞物体的小规模等多种干扰因素,使得交通事故检测变得复杂。尽管存在挑战,研究人员已经精心设计多个深度学习模型以寻找有用的模式,成为解决这一任务的主要选择,替代方案包括有监督、半监督、弱监督和无监督学习框架。深度学习技术在计算机视觉中的应用对事故检测系统的准确性和效率至关重要。通过深度学习算法,系统能学习和理解复杂的交通场景,从而提高对各种交通情境的识别能力。目前,用于交通事件检测的方法一般是基于时空特征提取和时间序列处理两个角度出发。
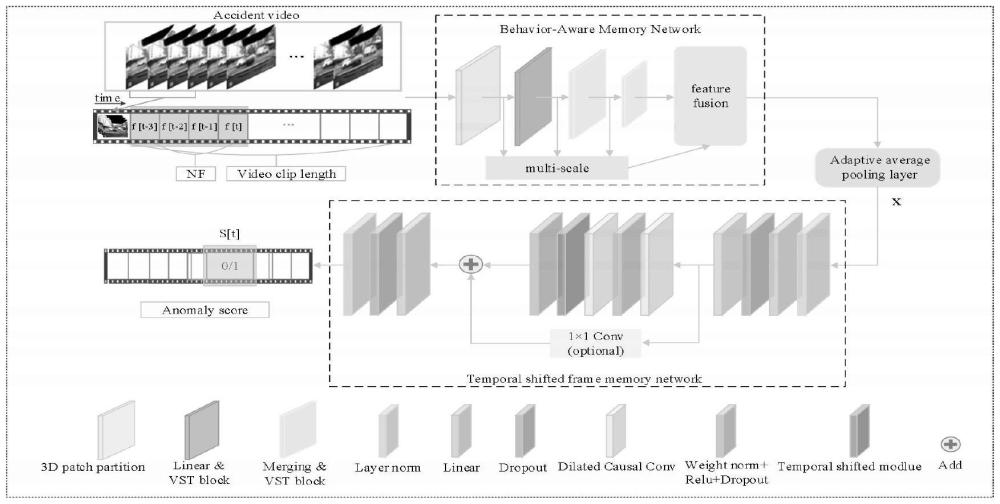
4、一方面,目前,针对单一阶段的videoswintransformer(vst)的交通视频异常检测研究相对较少。采用vst架构作为patchgan生成器的编码器,从视频帧序列中提取特征,从而增强视频数据集中的异常检测,实现有效的时空特征提取。一些研究人员采用vst作为视频异常检测中双阶段网络架构的一部分,使用纯vst在交通场景中建模短期记忆,它只依赖于当前帧和少数以前的帧来结合时间相关性并检测场景中的在线行为。但基于纯vst的网络在以驾驶者为第一视角的交通视频中,无法充分捕捉不同尺度的时空信息。在交通场景中,车辆和行人可能具有不同的尺度,所提出的行为关联记忆网络架构可以有效地处理这种多尺度信息,在交通场景中有助于解决时间相关性、适应不同尺度的对象,并提升在线行为检测的性能。
5、另一方面,temporalconvolutionalnetwork(tcn)是一种专门用于处理时间序列数据的convolutionalneuralnetwork(cnn)。与传统cnn不同,tcn考虑了时间维度上的相关性,因此能够更有效地处理时间序列数据。为了解决智能交通系统中关键问题之一,即短期交通流预测,研究者采用了taguchi方法来提高短期交通流预测模型。通过基于tcn的预测模型的改进,将其应用作为有效的城市短期交通预测工具。另外,还提出了一种基于遗传算法优化的时间卷积神经网络模型,旨在提升短期交通流预测的准确性和计算效率。目前,大多数研究集中在使用lstm、tcn及其变体来解决交通场景中的交通流预测问题,但鲜有研究采用tcn来处理交通视频中时间序列信息的相关性问题。而快速检测异常事件和准确定位异常事件的起始和结束时间,以便定位事故发生的片段,为事故责任调查提供支持是目前急需解决的问题。
技术实现思路
1、本发明针对上述现有技术中的技术问题,提出了一种跨时序融合记忆网络的交通事件检测方法,该发明通过在不同时间尺度上的时序特征融合,在时序轴上对特征进行平移来扩展网络对视频中时间序列的感受野,使得模型能够更好地捕捉时序数据中的时间关系和动态变化,以提高对时间序列数据的建模能力,提高在交通场景中对于所发生的异常事件进行时间定位和分类的能力。
2、本发明为实现上述发明目的,采取的技术方案如下:
3、一种跨时序融合记忆网络的交通事件检测方法,包括以下步骤:
4、步骤1:在行为关联记忆网络中,过将连续的t帧视频帧依次输入到多尺度信息融合的vst中,在连续的视频帧中捕捉位于相对较短的时间窗口内的帧之间的相关性,并检测在线行为;步骤2:在时移帧记忆网络中,对步骤1相应的输出作为temporalshiftedframememorynetwork的输入,利用卷积层和残差连接来学习时间序列中的长期依赖关系,并对交通事件发生开始和结束的时间进行定位,从而得到已知事故类别的分类概率。
5、进一步的作为本发明的优选技术方案,所述行为关联记忆网络中,在vst中,模型通过将视频序列的帧作为时间维度的一部分,引入了对时间相关性的建模;每个时间步的输入是一个视频帧,其中每个帧都被划分为空间上的窗口;通过对视频序列中的每个窗口执行自注意力机制,vst能够捕捉时间维度上的动态变化,从而建模视频中的时间相关性;通过对四个阶段vst模块的输出进行多尺度的特征融合,并采用非卷积下采样算法与其结合进行更加深入的算法,同时保留详细的时空特征。
6、进一步的作为本发明的优选技术方案,利用vst模块中的时间编码部分,通过将时间序列的每个时间步的空间特征作为输入,并通过自注意力机制来捕获帧与帧之间的的短期依赖关系,这允许模型关注先前和当前帧中的相关信息,以便更好地理解视频中的上下文信息;其中,两个连续的vstblocks的计算方法如式(1)所示:
7、
8、其中,和zl表示blockl的3d(s)w-msa模块和ffn模块的输出特征;3dw-msa和3dsw-msa分别表示基于三维窗口的多头自注意力,使用规则和移位的窗口分区配置;
9、vst在视频帧序列中引入了窗口化的注意力机制,以捕获局部和全局的时间信息,从而有效地处理视频中的异常情况;其最初设计用于视频动作分类,行为关联记忆网络模型在进一步调整后,用于执行单帧的分类任务;仅关注由当前帧到前一帧构成的大小为nf帧的小时间窗口;从时间t的当前帧到t-(nf-1)的前一帧;行为关联记忆网络将尺寸为nf×h×w×3的视频作为输入,其中nf(=4),h,e,w分别对应的是帧的数量、高度、宽度和rgb通道;在内部,该模型将视频帧分解为不重叠的3d补丁,将视频划分为令牌,并将特征投影到任意维度c。
10、进一步的作为本发明的优选技术方案,vst的多尺度融合结构,其中在特征提取部分获取多个不同大小的特征,并在每个阶段对特征进行特殊的局部处理,经过第一次patchmerging和卷积操作后,将特征大小更改为输入图像的四分之一,之后总共通过四个transformer模块,每个模块再次通过特征大小更改为二分之一,保留每个模块的输出,最后将多个特征模块进行融合,以获得最佳效果,计算方式如式(2)所示:
11、
12、在每个vst块中,通过采用多头注意力机制,使得模型可以同时关注输入中不同的局部信息;同时,通过在每个块中引入窗格,vst保持局部关系和上下文的平衡;较小的窗格有助于保留更细粒度的信息,而较大的窗格则有助于捕捉全局信息;
13、考虑到在交通场景中的相对位置关系和捕捉交通场景中的车辆行为之间的时序依赖关系,vst中的3d相对位置偏置起到了重要的作用;在以驾驶者为第一视角的交通视频场景中,vst中的3d相对位置偏置有助于提高模型对空间和时间关系的敏感性,从而改善视频序列的建模和在线行为检测的性能;3d相对位置偏置的具体计算方式如式(3)所示:
14、
15、其中,b就是位置偏置;b表示在一个windows内每个patch的相对位置,给每个相对位置一个特殊的embedding值。
16、进一步的作为本发明的优选技术方案,异常事件检测等计算机视觉问题需要处理输入之间的时间依赖性,并对短期或长期序列进行建模;经过行为关联记忆网络处理的输出在经过自适应平均池化三维层后,最终进入到分级头的内部;该过程由一系列归一化层、线性层和dropout层交替组成来进行;在最后一个归一化层之后插入了一个时移帧记忆网络模型,专门用来处理视频中的时序建模问题;时移帧记忆网络模型结合了tsm和tcn深度模型的优势。进一步的作为本发明的优选技术方案,tcn使用多层卷积层来逐渐扩大时间窗口;多层卷积层捕获不同时间尺度上的特征,使模型能够理解长期的时间依赖性;对于tcn中的膨胀卷积的计算方式则是由cnn的特征图输出计算方式上进一步推导得出;特征图的输入zin经过原始卷积层的计算得到输出zout,由下式计算:
17、
18、其中,p表示零填充数量;k表示卷积层中卷积核的大小;s是步长;表示向下取整;而特征图经过膨胀卷积后的卷积核尺寸k'则变为:
19、k'=d×(k-1)+1(5)
20、式中,d表示膨胀系数;用k'带入式(4)中的k,就计算出特征图经过膨胀卷积之后的输出尺寸;
21、在tcn网络架构中,是通过大小排列的空洞卷积来增加感受野的;空洞卷积是通过跳过部分输入来使filter可以应用于大于filter本身长度的区域;等同于增加零来从原始filter中生成更大的filter;具体的计算公式如式(6)所示:
22、
23、式中,x表示输入的一维时间序列;f表示空洞卷积中的滤波器filter;k为滤波器的尺寸大小;d是膨胀系数,d=1,2,4,8,16.......,膨胀系数为2的阶乘;s-d·i表示的是过去时间序列的方向。
24、进一步的作为本发明的优选技术方案,,在tcn网络架构中残差连接的空洞卷积之间添加了tsm,使得网络捕获更加广泛的时间上下文信息;针对在线视频来说,tsm模型的shift操作只能是单向的,采用residualtsm模块;为了降低模型的复杂度,更容易捕捉交通视频中相邻帧之间的时间序列规律性,采用等间隔的时序移动,通过对给定时间帧进行后向移动;能够在已有的空洞卷积感受野上实现对时间帧的移动,从而更好地扩展空洞卷积在时间信息上的处理范围,实现对时间信息的全面交互;通过更全面的信息融合,对交通场景中的异常事件进行分类;对输入时间序列x=[x1,x2,x3,…xt],进行等间隔时序移动,每个元素平移一个时间步长的话,则平移后的序列y可以表示为y=[xk+1,xk+2,…,xt,x1,…xk],其中xk+1表示原序列中的第k+1个元素。
25、进一步的作为本发明的优选技术方案,tsm的引入使得网络能够更好地捕捉到视频序列中的时间依赖关系,包括交通参与者快速的动作、时间变化较大的场景;同时由于tsm引入了更多的参数和非线性操作,增强网络的非线性,有助于减轻过拟合问题,使得时移帧记忆网络模型网能够适应复杂的时序模式,而不容易受到噪声的影响;在tsfmn网络中,假设输入n为一维时间序列,增经过膨胀卷积后的输出m[i]为
26、
27、其中,i为输入输出序列的位置索引,k表示滤波器的位置索引,k表示卷积核的尺度大小;
28、将经过膨胀卷积后的输出m[i]作为tsm的输入,设m[i]={m0,m1,…,mt}i∈[0,t],则经过tsm网络架构之后的输出y[i]表达式如下:
29、
30、式中,-1,0,+1分别表示时间位移方向;w=(ω1,ω2,ω3)表示卷积过程中的权值。
31、本发明所述的一种跨时序融合记忆网络的交通事件检测方法,采用以上技术方案与现有技术相比,具有以下技术效果:本发明提出了一种能够在在线工作模式下保证响应时间并实时工作的跨时序融合记忆网络的交通事件检测网络。首先,本发明设计了行为关联记忆网络,该架构是基于videoswintransformer的多尺度信息融合,通过将时序信息引入transformer模型,并在不同时间尺度上融合特征,从而更好地适应视频序列的时空动态变化。其次,本发明提出时域位移网络,该网络架构通过在时序轴上对特征进行平移来扩展网络对视频中时间序列的感受野,使得模型能够更好地捕捉时序数据中的时间关系和动态变化,以提高对时间序列数据的建模能力。成功识别并准确定位了视频中的交通事故发生和结束时间。
本文地址:https://www.jishuxx.com/zhuanli/20240730/194355.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。