芯片算子库接入深度学习框架的方法、装置、设备及介质与流程
- 国知局
- 2024-07-31 22:52:21
本公开涉及人工智能,尤其涉及一种芯片算子库接入深度学习框架的方法、装置、设备及介质。
背景技术:
1、相关技术将深度学习框架和ai(artificial intelligence,人工智能)芯片进行对接,一种方式是将深度学习框架的中间表示对接到ai芯片软件栈的中间表示,此种方式的适配难度偏大;另一种方式是深度学习框架的算子直接对接ai芯片的算子,此种方式对适配人员要求较高。
技术实现思路
1、为克服相关技术中存在的问题,本公开提供一种芯片算子库接入深度学习框架的方法、装置、设备及介质。本公开的技术方案如下:
2、根据本公开实施例的第一方面,提供一种芯片算子库接入深度学习框架的方法,所述方法包括:
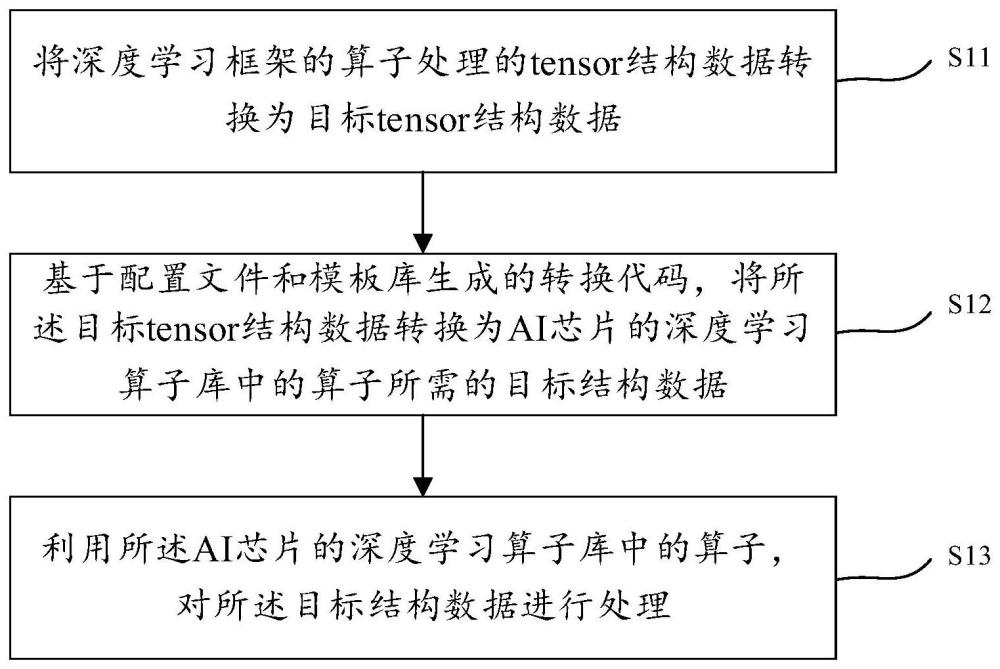
3、将深度学习框架的算子处理的tensor结构数据转换为目标tensor结构数据;
4、基于配置文件和模板库生成的转换代码,将所述目标tensor结构数据转换为ai芯片的深度学习算子库中的算子所需的目标结构数据;所述模板库包括算子对接过程的操作;所述配置文件用于对所述算子对接过程的操作进行配置;
5、利用所述ai芯片的深度学习算子库中的算子,对所述目标结构数据进行处理。
6、可选地,在所述基于配置文件和模板库生成的转换代码,将所述目标tensor结构数据转换为ai芯片的深度学习算子库中的算子所需的目标结构数据之前,所述方法还包括:
7、构建各个所述配置文件和代码的对应关系,并编写规则解析脚本;
8、获取所述模板库;
9、将各个所述配置文件传入所述规则解析脚本,遍历所述模板库,得到各个所述算子对接过程的操作对应的代码片段;
10、将各个所述代码片段进行组合,得到所述转换代码。
11、可选地,在所述基于配置文件和模板库生成的转换代码,将所述目标tensor结构数据转换为ai芯片的深度学习算子库中的算子所需的目标结构数据之前,所述方法还包括:
12、通过定义的所述ai芯片的通用基本操作接口,将所述目标tensor结构数据传输到所述ai芯片。
13、可选地,在通过定义的所述ai芯片提供的通用基本操作接口,将所述目标tensor结构数据传输到所述ai芯片之前,所述方法还包括:
14、定义所述ai芯片的runtime接口和分布式通信接口,得到通用接口;
15、定义所述ai芯片的深度学习算子库的公共接口基类,提炼出所述ai芯片的深度学习算子库所需的数据结构;
16、定义所述ai芯片的深度学习算子库适配过程所需的辅助数据结构。
17、可选地,所述定义所述ai芯片的runtime接口和分布式通信接口,得到通用接口,包括:
18、对所述ai芯片提供的runtime接口和分布式通信接口,定义用于进行设备管理、内存复制和通信操作的函数,得到所述通用接口;所述ai芯片提供的runtime接口和分布式通信接口和参考ai芯片提供的runtime接口和分布式通信接口相似;所述参考ai芯片为已经对提供的runtime接口和分布式通信接口进行了定义并得到通用接口的ai芯片;
19、在不存在所述ai芯片对应的所述参考ai芯片的情况下,所述对所述ai芯片提供的runtime接口和分布式通信接口,定义用于进行设备管理、内存复制和通信操作的函数,包括:
20、对所述ai芯片提供的runtime接口和分布式通信接口,进行如下定义:初始化设备,并设定执行设备;获取当前正在运行的设备的状态信息,并同步所述正在运行的设备的状态信息;将数据从主机内存拷贝到设备内存,并在设备内存之间拷贝数据;在多个设备之间执行规约操作,将各个进程的数据汇总,并分发给各个进程;将一个所述进程的数据,广播给其他进程;
21、在存在所述ai芯片对应的所述参考ai芯片的情况下,所述对所述ai芯片提供的runtime接口和分布式通信接口,定义用于进行设备管理、内存复制和通信操作的函数,包括:
22、将对所述参考ai芯片提供的runtime接口和分布式通信接口,定义用于进行设备管理、内存复制和通信操作的函数中,所述参考ai芯片对应的关键词,批量替换为所述ai芯片对应的关键词;所述关键词包括接口名称。
23、可选地,所述定义所述ai芯片的深度学习算子库的公共接口基类,提炼出所述ai芯片的深度学习算子库所需的数据结构,包括:
24、对所述ai芯片的深度学习算子库的线程入口的成员变量和成员函数进行定义,所述线程入口用于管理深度学习计算任务在所述ai芯片上的执行;
25、所述成员变量包括句柄成员变量、设备成员变量、流成员变量和流数组,所述句柄成员变量用于存储与所述深度学习算子库交互时所需的设备句柄;
26、所述成员函数包括静态成员函数和公有成员函数。
27、可选地,所述定义所述ai芯片的深度学习算子库适配过程所需的辅助数据结构,包括:
28、从所述ai芯片中,分配并管理用于算子对接的内存块;
29、设计智能指针和线程安全,以保证所述内存块的使用和释放。
30、根据本公开实施例的第二方面,提供一种芯片算子库接入深度学习框架的装置,所述装置包括:
31、第一转换模块,被配置为将深度学习框架的算子处理的tensor结构数据转换为目标tensor结构数据;
32、第二转换模块,被配置为基于配置文件和模板库生成的转换代码,将所述目标tensor结构数据转换为ai芯片的深度学习算子库中的算子所需的目标结构数据;所述模板库包括算子对接过程的操作;所述配置文件用于对所述算子对接过程的操作进行配置;
33、数据处理模块,被配置为利用所述ai芯片的深度学习算子库中的算子,对所述目标结构数据进行处理。
34、根据本公开实施例的第三方面,提供一种电子设备,包括:处理器;用于存储所述处理器可执行指令的存储器;其中,所述处理器被配置为执行所述指令,以实现如第一方面所述的芯片算子库接入深度学习框架的方法。
35、根据本公开实施例的第四方面,提供一种非易失性可读存储介质,当所述非易失性可读存储介质中的指令由电子设备的处理器执行时,使得所述电子设备能够执行如第一方面所述的芯片算子库接入深度学习框架的方法。
36、本公开实施例中,深度学习框架的算子直接对接ai芯片的深度学习算子库中的算子,只需将深度学习框架的算子处理的tensor结构数据转换为目标tensor结构数据,并将tensor结构数据转换为ai芯片的深度学习算子库中的算子所需的目标结构数据,即可利用ai芯片的深度学习算子库中的算子对目标结构数据进行处理,其中,对接过程无需编译,适配对接的层次是算子,适配难度小,且性能较好。
技术特征:1.一种芯片算子库接入深度学习框架的方法,其特征在于,所述方法包括:
2.根据权利要求1所述的方法,其特征在于,在所述基于配置文件和模板库生成的转换代码,将所述目标tensor结构数据转换为ai芯片的深度学习算子库中的算子所需的目标结构数据之前,所述方法还包括:
3.根据权利要求1所述的方法,其特征在于,在所述基于配置文件和模板库生成的转换代码,将所述目标tensor结构数据转换为ai芯片的深度学习算子库中的算子所需的目标结构数据之前,所述方法还包括:
4.根据权利要求3所述的方法,其特征在于,在通过定义的所述ai芯片提供的通用基本操作接口,将所述目标tensor结构数据传输到所述ai芯片之前,所述方法还包括:
5.根据权利要求4所述的方法,其特征在于,所述定义所述ai芯片的runtime接口和分布式通信接口,得到通用接口,包括:
6.根据权利要求4所述的方法,其特征在于,所述定义所述ai芯片的深度学习算子库的公共接口基类,提炼出所述ai芯片的深度学习算子库所需的数据结构,包括:
7.根据权利要求4所述的方法,其特征在于,所述定义所述ai芯片的深度学习算子库适配过程所需的辅助数据结构,包括:
8.一种芯片算子库接入深度学习框架的装置,其特征在于,所述装置包括:
9.一种电子设备,其特征在于,包括:处理器;用于存储所述处理器可执行指令的存储器;其中,所述处理器被配置为执行所述指令,以实现如权利要求1-7任一所述的芯片算子库接入深度学习框架的方法。
10.一种非易失性可读存储介质,当所述非易失性可读存储介质中的指令由电子设备的处理器执行时,使得所述电子设备能够执行如权利要求1-7任一所述的芯片算子库接入深度学习框架的方法。
技术总结本公开关于一种芯片算子库接入深度学习框架的方法、装置、设备及介质,涉及人工智能技术领域,旨在方便快捷地将深度学习框架的算子与AI芯片的深度学习算子库的算子进行对接。该方法包括:将深度学习框架的算子处理的tensor结构数据转换为目标tensor结构数据;基于配置文件和模板库生成的转换代码,将所述目标tensor结构数据转换为AI芯片的深度学习算子库中的算子所需的目标结构数据;所述模板库包括算子对接过程的操作;所述配置文件用于对所述算子对接过程的操作进行配置;利用所述AI芯片的深度学习算子库中的算子,对所述目标结构数据进行处理。技术研发人员:何也受保护的技术使用者:苏州元脑智能科技有限公司技术研发日:技术公布日:2024/7/29本文地址:https://www.jishuxx.com/zhuanli/20240730/195100.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表