一种油气管道数据处理方法、装置、设备、介质及产品
- 国知局
- 2024-07-31 22:57:56
本发明涉及数据处理,具体涉及一种油气管道数据处理方法、装置、设备、介质及产品。
背景技术:
1、存储技术的发展使得大数据在各行业(如油气管道安全领域)不断累积,快速的大数据分析技术对各行业大规模数据的及时的统计分析具有重要意义。相关技术中,在油气管道领域中,大多采用分布式计算方式处理油气管道数据,如图1所示,首先由中心计算机把大数据随机分成多个数据集,将每一个小的数据集交给一个计算机进行处理,然后各个计算机把各自分析结果传输给中心计算机,由它整合得到最终分析结果。该方式在处理如油气管道数据时,需要搭建庞大的分布式计算系统,通常花费比较昂贵,分布式计算需要在多个计算机之间传输数据,数据容易发生泄露,并且需要依赖专业人员参与,导致数据处理效率较低。
技术实现思路
1、有鉴于此,本发明提供了一种油气管道数据处理方法、装置、设备、介质及产品,以解决分布式计算系统在处理油气管道数据时,需要搭建庞大的分布式计算系统,通常花费比较昂贵,分布式计算需要在多个计算机之间传输数据,数据容易发生泄露,并且需要依赖专业人员参与,导致数据处理效率较低的问题。
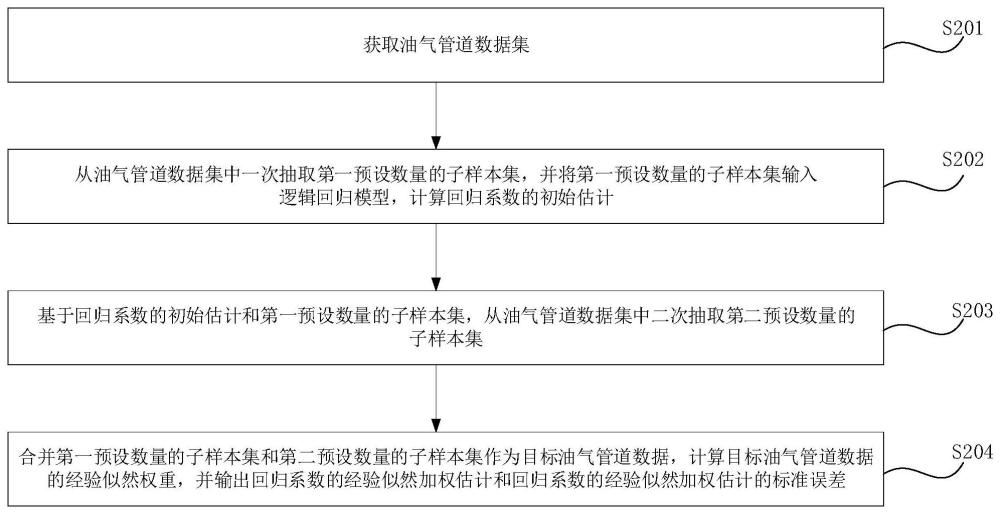
2、根据第一方面,本实施例提供一种油气管道数据处理方法,方法包括:
3、获取油气管道数据集;
4、从油气管道数据集中一次抽取第一预设数量的子样本集,并将第一预设数量的子样本集输入逻辑回归模型,计算回归系数的初始估计;
5、基于回归系数的初始估计和第一预设数量的子样本集,从油气管道数据集中二次抽取第二预设数量的子样本集;
6、合并第一预设数量的子样本集和第二预设数量的子样本集作为目标油气管道数据,计算目标油气管道数据的经验似然权重,并输出回归系数的经验似然加权估计和回归系数的经验似然加权估计的标准误差。
7、通过执行上述实施方式,基于容量较小的子样本对油气管道大数据做统计推断,因而在处理油气管道大数据方面具有计算速度快、处理方便、保护数据等优点。本发明以油气管道大数据分析为实施例,基于逻辑回归模型探究影响管道环焊缝安全的风险因素,相比于通过分布式计算系统,能够解决分布式计算系统在处理油气管道数据时,需要搭建庞大的分布式计算系统,通常花费比较昂贵,分布式计算需要在多个计算机之间传输数据,数据容易发生泄露,并且需要依赖专业人员参与,导致数据处理效率较低的问题。
8、在一种可选的实施方式中,从油气管道数据集中一次抽取第一预设数量的子样本集,并将子样本集输入逻辑回归模型,计算回归系数的初始估计,包括:
9、基于油气管道数据集,计算逻辑回归模型中回归系数的统计概率;
10、基于逻辑回归模型中回归系数的统计概率,确定一次抽取子样本集的第一预设数量;
11、基于一次抽取子样本集的第一预设数量,从油气管道数据集中一次抽取第一预设数量的子样本集;
12、将第一预设数量的子样本集输入逻辑回归模型,计算回归系数的初始估计。
13、通过执行上述实施方式,计算初始估计,最终有利于从油气管道数据集中二次抽取第二预设数量的子样本集,同时,通过该加权估计,能够有效识别影响管道环焊缝安全的风险因素。
14、在一种可选的实施方式中,基于回归系数的初始估计和第一预设数量的子样本集,从油气管道数据集中二次抽取第二预设数量的子样本集,包括:
15、基于油气管道数据集,确定二次抽取子样本集的第二预设数量;
16、基于第一预设数量和第二预设数量,计算两次抽样的平均入样概率;
17、基于平均入样概率和回归系数的初始估计,计算两次抽样的最优入样概率;
18、基于最优入样概率,利用不等概率泊松抽样算法二次抽取第二预设数量的子样本集。
19、通过执行上述实施方式,本实施例通过所提供的不等概率泊松抽样算法二次抽取第二预设数量的子样本集,而非基于传统的逆概率加权方式,由于经验似然加权技巧避免使用概率的倒数作为权重,同时充分利用抽样权重、样本数据等辅助信息,因而回归系数的经验似然加权估计相对于逆概率加权估计而言更加稳定,统计意义上具有更高的估计效率。
20、在一种可选的实施方式中,合并第一预设数量的子样本集和第二预设数量的子样本集作为目标油气管道数据,计算目标油气管道数据的经验似然权重,并输出回归系数的经验似然加权估计和回归系数的经验似然加权估计的标准误差,包括:
21、合并第一预设数量的子样本集和第二预设数量的子样本集,计算完全似然函数的对数经验似然函数;
22、创建经验似然权重约束条件;
23、基于经验似然权重约束条件,对对数经验似然函数的权重最大化得到目标油气管道数据的经验似然权重;
24、基于目标油气管道数据的经验似然权重,计算回归系数的经验似然加权估计;
25、基于回归系数的经验似然加权估计和油气管道数据集,计算回归系数的经验似然加权估计和回归系数的经验似然加权估计的标准误差。
26、通过执行上述实施方式,基于容量较小的子样本对油气管道大数据做统计推断,因而在处理大数据方面具有计算速度快、处理方便的优势。
27、根据第二方面,本实施例提供一种油气管道数据处理装置,装置包括:
28、油气管道数据获取模块,用于获取油气管道数据集;
29、初始估计计算模块,用于从油气管道数据集中一次抽取第一预设数量的子样本集,并将第一预设数量的子样本集输入逻辑回归模型,计算回归系数的初始估计;
30、样本二次抽取模块,用于基于回归系数的初始估计和第一预设数量的子样本集,从油气管道数据集中二次抽取第二预设数量的子样本集;
31、油气管道数据计算模块,用于合并第一预设数量的子样本集和第二预设数量的子样本集作为目标油气管道数据,计算目标油气管道数据的经验似然权重,并输出回归系数的经验似然加权估计和回归系数的经验似然加权估计的标准误差。
32、在一种可选的实施方式中,初始估计计算模块,包括:
33、统计概率计算子模块,用于基于油气管道数据集,计算逻辑回归模型中回归系数的统计概率;
34、一次样本确定子模块,用于基于逻辑回归模型中回归系数的统计概率,确定一次抽取子样本集的第一预设数量;
35、一次样本抽取子模块,用于基于一次抽取子样本集的第一预设数量,从油气管道数据集中一次抽取第一预设数量的子样本集;
36、初始估计计算子模块,用于将第一预设数量的子样本集输入逻辑回归模型,计算回归系数的初始估计。
37、在一种可选的实施方式中,样本二次抽取模块,包括:
38、二次样本确定子模块,用于基于油气管道数据集,确定二次抽取子样本集的第二预设数量;
39、平均概率计算子模块,用于基于第一预设数量和第二预设数量,计算两次抽样的平均入样概率;
40、最优概率计算子模块,用于基于平均入样概率和回归系数的初始估计,计算两次抽样的最优入样概率;
41、二次样本抽取子模块,用于基于最优入样概率,利用不等概率泊松抽样算法二次抽取第二预设数量的子样本集。
42、根据第三方面,本实施例提供一种计算机设备,包括:
43、存储器和处理器,存储器和处理器之间互相通信连接,存储器中存储有计算机指令,处理器通过执行计算机指令,从而执行第一方面或第一方面任一实施方式中的油气管道数据处理方法。
44、根据第四方面,本实施例提供一种计算机可读存储介质,计算机可读存储介质上存储有计算机指令,计算机指令用于使计算机执行第一方面或第一方面任一实施方式中的油气管道数据处理方法。
45、根据第五方面,本实施例提供一种计算机程序产品,包括计算机指令,计算机指令用于使计算机执行第一方面或第一方面任一实施方式中的油气管道数据处理方法。
本文地址:https://www.jishuxx.com/zhuanli/20240730/195512.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表