基于快速归一化流模型的语音驱动虚拟数字人脸生成方法与流程
- 国知局
- 2024-07-31 22:58:46
本技术涉及计算机信息,尤其涉及一种基于快速归一化流模型的语音驱动虚拟数字人脸生成方法。
背景技术:
1、随着人工智能和计算机视觉技术的不断发展,语音驱动虚拟数字人脸生成技术逐渐成为了一个备受关注的研究方向。这种技术可以将语音信息与人脸生成相结合,从而实现虚拟数字人的口型和面部表情的自然生成,为虚拟人物和人机交互技术提供了更加生动和自然的体验。
2、目前的语音驱动人脸生成方法主要包括基于人脸关键点、3dmm(三维形状和纹理模型)、运动场、神经辐射场等技术。此外,还有一些基于gan(生成对抗网络)和扩散模型的方法,这些方法在一定程度上均可以实现语音驱动的人脸生成。
3、尽管现有技术在语音驱动人脸生成领域取得了一定进展,但仍然存在一些问题亟待解决。例如,基于关键点的方法容易导致人脸驱动不自然,效果不平滑;基于3dmm的方法在重建人脸时容易出现抖动不平滑效果;基于gan的方法需要大量数据训练且难以训练;而基于扩散模型的方法在表达人脸细节特征上仍有缺失,如无法表达牙齿和人员身份等信息。综上所述,现有技术在语音驱动人脸生成方面尚存在生成效果不佳、模型复杂度高、计算资源消耗大等问题,因此需要一种更加高效且稳定的解决方案来应对上述技术的不足。
技术实现思路
1、本技术提供了一种基于快速归一化流模型的语音驱动虚拟数字人脸生成方法、系统、设备及存储介质,有效解决了现有技术中视频帧率不一致、人脸检测不准确以及语音特征提取困难等技术问题。本技术提供如下技术方案:
2、第一方面,本技术提供一种基于快速归一化流模型的语音驱动虚拟数字人脸生成方法,所述方法包括:
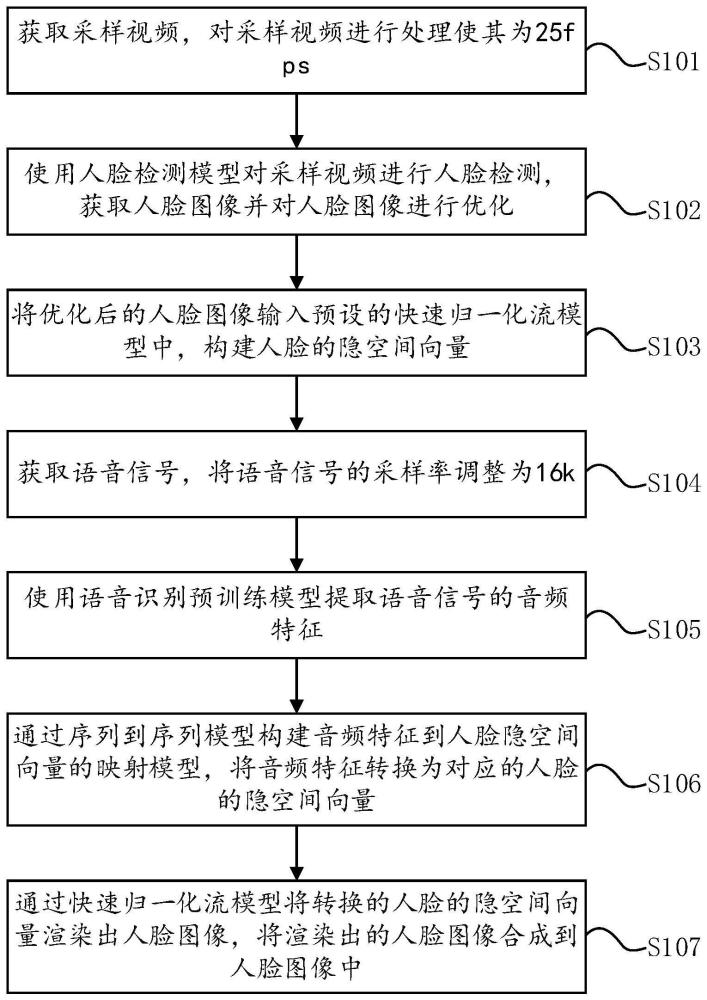
3、获取采样视频,对所述采样视频进行处理使其为25fps;
4、使用人脸检测模型对所述采样视频进行人脸检测,获取人脸图像并对所述人脸图像进行优化;
5、将优化后的人脸图像输入预设的快速归一化流模型中,构建人脸的隐空间向量;
6、获取语音信号,将所述语音信号的采样率调整为16k;
7、使用语音识别预训练模型提取所述语音信号的音频特征;
8、通过序列到序列模型构建所述音频特征到人脸隐空间向量的映射模型,将所述音频特征转换为对应的人脸的隐空间向量;
9、通过所述快速归一化流模型将转换的人脸的隐空间向量渲染出人脸图像,将渲染出的人脸图像合成到人脸图像中。
10、在一个具体的可实施方案中,所述获取采样视频,对所述采样视频进行处理使其为25fps包括:
11、检查所述采样视频的当前帧率;
12、如果所述采样视频的帧率不是25fps,使用ffmpeg工具进行处理,将所述采样视频转换为标准的25fps。
13、在一个具体的可实施方案中,所述使用人脸检测模型对所述采样视频进行人脸检测,获取人脸图像并对所述人脸图像进行优化包括:
14、采用sfd人脸检测模型对所述采样视频进行人脸检测;
15、所述sfd模型在所述采样视频中定位和识别人脸,将检测到的人脸图像截取出来;
16、将检测到的人脸框沿着其中心扩大1.25倍,并将扩大后的人脸图像缩放至256*256尺寸。
17、在一个具体的可实施方案中,所述将优化后的人脸图像输入预设的快速归一化流模型中,构建人脸的隐空间向量包括:
18、将优化后的人脸图像输入预训练的快速归一化流模型中;
19、所述快速归一化流模型内部的变换网络对优化后的人脸图像进行处理,逐步将其转换为一个高维的隐空间向量。
20、在一个具体的可实施方案中,所述使用语音识别预训练模型提取所述语音信号的音频特征包括:
21、将16k采样率的语音信号分成连续的语音帧或片段;
22、语音帧或片段作为语音识别预训练模型的输入,经过hubert模型处理后,每个语音帧都会被转换为一个特征向量。
23、在一个具体的可实施方案中,所述通过序列到序列模型构建所述音频特征到人脸隐空间向量的映射模型,将所述音频特征转换为对应的人脸的隐空间向量包括:
24、使用语音识别模型中的conformer结构将音频特征解耦为表情信息向量和语义信息向量;
25、利用线性映射技术,将解耦后的音频特征映射为人脸的隐空间向量;
26、构建并训练seq2seq模型,模型接受解耦后的音频特征作为输入,并输出对应的人脸隐空间向量。
27、在一个具体的可实施方案中,所述通过序列到序列模型构建所述音频特征到人脸隐空间向量的映射模型,将所述音频特征转换为对应的人脸的隐空间向量还包括:
28、通过线性映射与随机选取的参考特征向量,将其分解成两个关键组成部分:姿态特征和外观特征;
29、利用两个连续的conformer结构来处理语音识别预训练模型提取的特征,将其分解为两类向量:一类捕捉表情信息,另一类包含与说话内容密切相关的语义信息。
30、第二方面,本技术提供一种基于快速归一化流模型的语音驱动虚拟数字人脸生成系统,采用如下的技术方案:
31、一种基于快速归一化流模型的语音驱动虚拟数字人脸生成系统,包括:
32、视频采样模块,用于获取采样视频,对所述采样视频进行处理使其为25fps;
33、人脸检测模块,用于使用人脸检测模型对所述采样视频进行人脸检测,获取人脸图像并对所述人脸图像进行优化;
34、向量构建模块,用于将优化后的人脸图像输入预设的快速归一化流模型中,构建人脸的隐空间向量;
35、信号获取模块,用于获取语音信号,将所述语音信号的采样率调整为16k;
36、特征提取模块,用于使用语音识别预训练模型提取所述语音信号的音频特征;
37、图像转换模块,用于通过序列到序列模型构建所述音频特征到人脸隐空间向量的映射模型,将所述音频特征转换为对应的人脸的隐空间向量;
38、图像合成模块,用于通过所述快速归一化流模型将转换的人脸的隐空间向量渲染出人脸图像,将渲染出的人脸图像合成到人脸图像中。
39、第三方面,本技术提供一种电子设备,所述设备包括处理器和存储器;所述存储器中存储有程序,所述程序由所述处理器加载并执行以实现如第一方面所述的一种基于快速归一化流模型的语音驱动虚拟数字人脸生成方法。
40、第四方面,本技术提供一种计算机可读存储介质,所述存储介质中存储有程序,所述程序被处理器执行时用于实现如第一方面所述的一种基于快速归一化流模型的语音驱动虚拟数字人脸生成方法。
41、综上所述,本技术的有益效果至少包括:
42、(1)通过使用二阶段网络实现虚拟数字人脸生成,我们能够迅速且准确地生成数字人脸。同时,通过快速归一化流模型实现的人脸编辑功能,我们不仅能优化隐空间特征,还可以进行更为精细的人脸编辑,如表情和姿态的调整,提供了更高的人脸生成和编辑效率。
43、(2)采用序列到序列模型,我们能够有效地学习长时音频信息到人脸的特征向量的映射,实现了对音频信息的精准捕捉和转换。此外,通过引入参考向量,我们不仅成功保留了说话人的身份特征,还能有效解耦出与音频无关的头部姿态信息,实现了对头部姿态的精准控制。
44、通过结合25fps的视频处理、sfd人脸检测、快速归一化流模型和hubert语音识别模型,实现了从采样视频和16k语音信号到人脸隐空间向量的流程。采用特定的seq2seq架构确保了音频特征与人脸向量的匹配,同时通过定制的解码器结构优化了向量生成。hubert模型的选用利用其transformer架构和预训练优势,实现了从语音信号中高效准确地提取音频特征。这一整套流程有效解决了现有技术中视频帧率不一致、人脸检测不准确以及语音特征提取困难等技术问题,为实现语音驱动的虚拟数字人脸生成提供了稳健的解决方案。
45、上述说明仅是本技术技术方案的概述,为了能够更清楚了解本技术的技术手段,并可依照说明书的内容予以实施,以下以本技术的较佳实施例并配合附图详细说明如后。
本文地址:https://www.jishuxx.com/zhuanli/20240730/195579.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
上一篇
一种碳减排规划方法与流程
下一篇
返回列表