一种基于语义分解多关系图卷积网络的骨架动作识别方法
- 国知局
- 2024-07-31 23:18:27
本发明属于计算机视觉,具体涉及一种基于语义分解多关系图卷积网络的骨架动作识别方法。
背景技术:
1、基于骨架的动作识别技术利用人体骨架信息进行动作分析和识别,其应用潜力广泛,涵盖智能监控、健康管理、虚拟现实、体育训练等多个领域。这项技术通过传感器或深度学习模型捕捉人体姿态,从中提取骨架信息,并分析空间和时间特征,以识别不同的动作。然而,动作识别面临诸多挑战,如背景杂波、光照变化、尺度变化、视点变化、遮挡和运动速度变化等。
2、早期基于深度学习的方法将人类关节视为一组独立的特征,并将它们组织成一个特征序列或一个伪图像,并将其输入循环神经网络或卷积神经网络来预测动作标签。然而,这些方法忽略了关节之间的内在相关性。而这些内在相关性揭示了人体的拓扑结构,是人体骨骼的重要信息。
3、与rgb或光流等数据模式相比,骨架数据虽然结构更为紧凑,但却蕴含着丰富的信息。这种紧凑结构使得骨架数据,揭示了人体的拓扑结构,更具适应性和鲁棒性,能够更好地应对光照变化或场景变化等干扰因素。因此,基于骨架的动作识别近年来备受关注。
4、基于骨架的动作识别研究可以分为四大类:传统手工方法、基于循环神经网络(recurrent neural network, rnn)的方法、基于卷积神经网络(convolutional neuralnetwork, cnn)的方法和基于图卷积网络(graph convolutional network, gcn)的方法。其中,基于gcn的图卷积方法不同于传统手工方法、cnn和rnn网络模型,它可以处理具有广义拓扑结构的数据,并深入挖掘其特征。
5、近年来,许多基于图卷积的方法被提出,几种具有代表性的方法包括时空图卷积网络、双流自适应图卷积网络、解耦图卷积网络、多尺度图卷积和统一的空时图卷积、通道拓扑细化图卷积以及poseconv3d;上述现有技术存在的缺点在于:
6、(1)广泛使用的手工图,只使用人体骨骼中物理连接边的关系;然而,对于人类识别行为,不仅相邻关节之间的关系很重要,而且远处关节之间的关系也很重要。
7、(2)没有识别哪些边对动作识别结果影响更显著,因为它们只是聚合边特征,忽略了每个边的贡献。
8、(3)当前技术使用2d或3d坐标作为关节点的特征;由于2d坐标是经过严格的人工校验得到的,2d坐标比3d坐标更准确,若只使用2d坐标作为输入,又缺乏3d坐标的深度信息。
技术实现思路
1、针对现有技术中的上述不足,本发明提供的基于语义分解多关系图卷积网络的骨架动作识别方法解决了上述现有的图卷积网络考虑因素不完全,进而影响骨架动作识别准确性的问题。
2、为了达到上述发明目的,本发明采用的技术方案为:一种基于语义分解多关系图卷积网络的骨架动作识别方法,包括以下步骤:
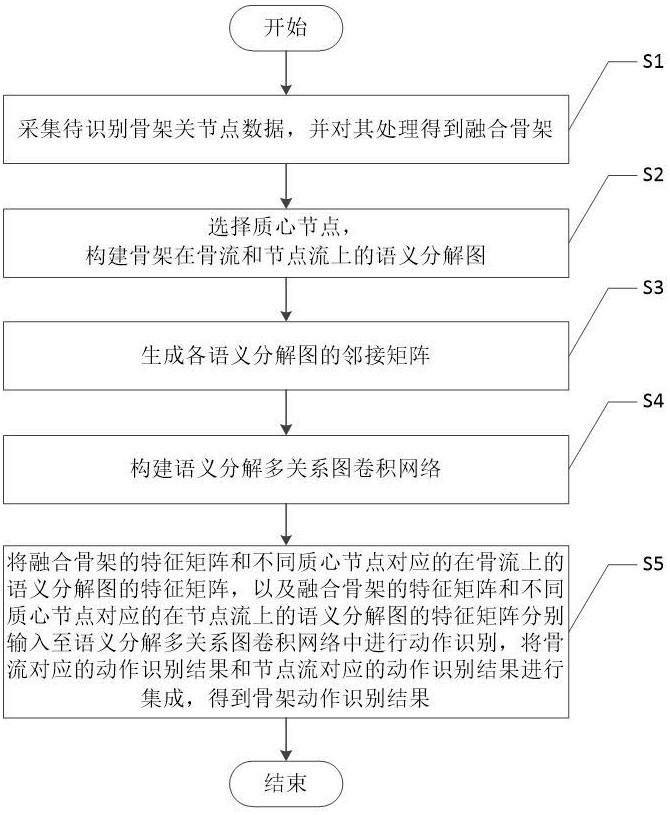
3、s1、采集待识别骨架关节点数据,并对其处理得到融合骨架;
4、s2、选择质心节点,构建骨架在骨流和节点流上的语义分解图;
5、s3、生成各语义分解图的邻接矩阵;
6、s4、构建语义分解多关系图卷积网络;
7、s5、将融合骨架的特征矩阵和不同质心节点对应的在骨流上的语义分解图的特征矩阵,以及融合骨架的特征矩阵和不同质心节点对应的在节点流上的语义分解图的特征矩阵分别输入至语义分解多关系图卷积网络中进行动作识别,将骨流对应的动作识别结果和节点流对应的动作识别结果进行集成,得到骨架动作识别结果。
8、进一步地,所述步骤s1中,所述融合骨架表示为(, , score, , );
9、其中,(, , score)为关节点n的2d姿态估计的坐标三联体,为关节点n的3d姿态估计中的深度信息,为深度信息的置信度,其表达式为:
10、;
11、式中,d表示边界框的对角线长度。
12、进一步地,所述步骤s2中,构建任一质心节点在骨流或节点流上对应的语义分解图的方法具体为:
13、s21、在骨架中,选择使同一层次边集中的节点存在于同一语义空间中的质心节点;
14、s22、根据确定的质心节点,使用物理连接对骨架进行边分解;
15、s23、对分解得到的每个集合加上全连接边,进而构建出语义分解图。
16、进一步地,所述步骤s3中,邻接矩阵表示为:
17、<mi>a</mi><mi>=[</mi><msup><mi>e</mi><mi>(1)</mi></msup><mi>||</mi><msup><mi>e</mi><mi>(2)</mi></msup><mi>||...||</mi><msup><mi>e</mi><mrow><mi>(</mi><msub><mi>n</mi><mi>l</mi></msub><mi>)</mi></mrow></msup><mi>]</mi>;
18、;
19、式中,表示语义分解图中第l层三个边子集的连接,表示语义分解图中每个层次节点集的同心边集,表示邻接矩阵的有向离心边集,表示向心边集,表示语义分解图中第lth层结构节点集,上标l表示语义分解图的层数序数。
20、进一步地,所述步骤s4中,所述语义分解多关系图卷积网络包括依次连接的若干堆叠图卷积块、全连接层和softmax输出层;
21、每个所述图卷积块均包括依次连接的空间网络和时间网络;
22、所述空间网络包括对语义分解图中每个层的进行语义分解的语义分解图卷积模块、将各层语义分解卷积模块的输出进行拼接的concat操作,以及对拼接得到的特征映射进行注意力引导的层次结构聚合模块;
23、所述时间网络包括均与所述空间网络输出连接的第一分支、第二分支、第三分支和第四分支;
24、所述第一分支包括依次连接的1×1卷积和dilation为1的5×1扩展卷积;
25、所述第二分支包括依次连接的1×1卷积和dilation为2的5×1扩展卷积;
26、所述第三分支包括依次连接的1×1卷积和3×1的卷积最大池化;
27、所述第四分支为5×1的扩展卷积;
28、所述第一分支、第二分支、第三分支和第四分支的输出通过concat操作连接输入至全连接层。
29、进一步地,所述语义分解图卷积模块对输入的特征矩阵进行处理的方法具体为:
30、a1、对特征矩阵进行线性变换;
31、a2、通过多关系图注意力网络对经过线性变换的特征矩阵进行处理,得到对应层的输出特征;
32、a3、将经过线性变换的特征矩阵依次进行平均池化和边卷积处理,获得边卷积输出;
33、a4、将和沿信道维度的边缘卷积连接起来,得到对应层的输出;
34、其中,表示线性变换后的特征矩阵,表示可训练参数,表示输入的特征矩阵,表示sigmoid函数,表示通过多关系图注意力网络得到的第l层的注意加权邻接矩阵,表示第层对应子集的可训练参数,表示第l层的边卷积,表示第帧的特征矩阵,表示帧总数。
35、进一步地,所述步骤a2中的多关系图注意力网络用于处理多关系图的消息传递,在信息聚合过程中以不同的权值评估不同类型的关系,并在训练过程中自适应学习权值;
36、所述多关系图注意力网络处理多关系图的方法具体为:
37、对于多关系图不同关系的子图应用一个注意力机制,然后每个对子图的输出进行权值求和,进而得到对应层的输出特征。
38、进一步地,所述子图的输出表示为:
39、;
40、式中,表示应用注意力机制计算的注意力系数,表示关系r中节点i的邻居节点的集合,
41、通过关系r与节点i连接的集合,表示节点i的特征,表示线性变换的权重矩阵;
42、其中,注意力系数的计算公式为:
43、<msub><mi>μ</mi><mi>i, j, r</mi></msub><mi>=</mi><msub><mi>softmax</mi><mi>j,r</mi></msub><mrow><mi>a</mi><mrow><msub><mi>x</mi><mi>i</mi></msub><mi>|| </mi><msub><mi>x</mi><mi>j</mi></msub></mrow></mfenced></mrow></mfenced><mi>=</mi><mfrac><mrow><mi>exp(a[</mi><msub><mi>x</mi><mi>i</mi></msub><mi>|| </mi><msub><mi>x</mi><mi>j</mi></msub><mi>])</mi></mrow><mstyle displaystyle="false"><munder><mo>∑</mo><mo>j∈n(i,r)</mo></munder><mrow><mi>exp(a[</mi><msub><mi>x</mi><mi>i</mi></msub><mi>|| </mi><msub><mi>x</mi><mi>j</mi></msub><mi>])</mi></mrow></mstyle></mfrac>;
44、式中,<mi>a[.]</mi>表示把拼接后的高维特征映射到一个实数上,表示连接操作。
45、进一步地,所述层次结构聚合模块的输出为特征映射与注意力系数的乘积;
46、其中,注意力系数的计算公式为:
47、;
48、;
49、式中,表示边的卷积,表示对进行池化,表示第层的节点数,表示线性变换,表示节点,下标表示帧序数,下标表示层序数,下标表示层总数。
50、进一步地,所述步骤s5中的质心节点包括3个。
51、本发明的有益效果为:
52、(1)本发明将人体骨架按质心节点分解为根树,再将全连接边应用到根树上,使得该图将变得更密集,接受域比以前更大,并具有更有意义的远距离连接。
53、(2)本发明提出了多关系图注意力网络,并使用多关系图注意力网络来计算不同分层的贡献,能识别出哪些边是重要的,哪些边是次要的。
54、(3)本发明提出了一种新的2d和3d融合坐标作为网络输入,提升了特征的准确性。
本文地址:https://www.jishuxx.com/zhuanli/20240730/196919.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。