保证公平的联邦学习客户端选择方案
- 国知局
- 2024-07-31 23:20:51
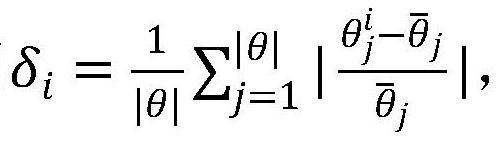
本发明涉及一种保证公平的联邦学习客户端选择方案。
背景技术:
1、在联邦学习的过程中,服务器首先初始化全局模型,广播给所有参与训练的客户端。客户端收到模型后结合本地数据集在客户端本地对模型进行训练,再将更新结果上传给服务器。服务器接收到上传的参数进行聚合得到全局更新,迭代数次后停止训练。在这一过程中,存在许多安全的隐患问题。例如,设备异构导致客户端之间计算能力,通信,存储效率不平衡;数据异构引起的数据类型,数据量不平衡问题等。
2、联邦学习(federated learning)本质上是一种分布式的机器学习技术。传统的由服务器集中训练的机器学习模型存在安全性和隐私方面的不足,联邦学习作为一种高效的隐私保护手段应运而生。联邦学习利用去中心化的数据源进行训练,避免因中心化带来的隐私问题;以不访问参与者私有数据为前提,在一定程度上保证了原始数据的隐私安全。具体来说,联邦学习过程就是参与者在本地对数据进行训练,再将训练后得到的参数上传到服务器,最后由云聚合得到整体参数。通过这种方式,可以在客户端和服务器之间共享信息,且在训练过程中有效的保护了用户的数据隐私。
3、在典型的fl场景中,客户端在数据分布和硬件配置方面表现出显著的异构性,在每一轮训练中随机采样的客户端可能无法完全利用来自异构客户端的本地更新,导致模型精度较低、收敛速度较慢、公平性降低等。
4、下面就是保证公平的联邦学习客户端选择方案所使用的一些技术:
5、联邦平均(fedavg)算法将每个客户端的局部随机梯度下降(sgd)与执行模型平均的服务器相结合。在客户端进行多轮局部模型的更新,在服务器将局部模型上传,只进行一个平均算法进行聚合,即,该算法将计算量放在了本地客户端,而服务器只用于聚合平均。
6、随机梯度下降算法(sgd)是深度学习中常用的优化算法之一。sgd是一种基于梯度的优化算法,用于更新深度神经网络的参数。它的基本思想是,在每一次迭代中,随机选择一个小批量的样本来计算损失函数的梯度,并用梯度来更新参数。这种随机性使得算法更具鲁棒性,能够避免陷入局部极小值,并且训练速度也会更快。
7、客户端选择策略:设计一种公平的客户端选择策略,以确保每个参与联邦学习的客户端都有公平的机会参与模型更新。这可以通过考虑客户端的计算能力、通信性能、数据量大小等因素来实现。一种可能的方法是基于客户端的性能指标进行加权随机选择,以使得每个客户端在一定程度上能够公平地参与到模型更新中。
8、均衡数据采样:为了保证公平性,可以采用加权均衡采样策略。假设有m个客户端,每个客户端的数据集大小不同,分别为|d1|,|d2|,...,|dm|。可以计算每个客户端的加权采样概率,使得每个客户端被采样的概率与其数据集大小成正比。采样概率pi=|di|/(|d1|+|d2|+...+|dm|),在每一轮训练中,根据上述概率进行加权采样,使得各个客户端的数据贡献相对均衡。
9、动态客户端选择:为了保证公平性,可以引入动态客户端选择策略,根据客户端的性能指标和数据质量等因素,合理地选择参与训练的客户端。可以定义一个客户端选择指标,综合考虑客户端的准确度、收敛速度、通信延迟等因素。
10、共享模型参数:为了保证公平性,可以将服务器的全局模型参数与客户端共享,以使客户端能够更好地利用来自其他客户端的信息。具体做法是,在每一轮训练中,服务器将全局模型参数广播给所有客户端。客户端在本地进行训练时,将全局模型参数作为初始参数,并在训练过程中利用本地数据进行更新。在上传更新结果时,只传输模型的更新部分,而不包括全局模型参数,以减少通信开销。服务器在接收到客户端的更新结果后,将其与全局模型参数进行聚合,得到更新后的全局模型参数。
11、模型评估和选择:为了保证公平性,可以引入模型评估和选择的策略,综合考虑客户端的性能指标、数据质量等因素。例如,可以设定一个合适的评估指标,如准确度或损失函数值,根据该指标对各个客户端进行排名。然后,在每一轮训练中,选择排名靠前的客户端参与训练,以保证公平性和代表性。
12、客户端优先级排序:在每一轮训练中,对每个客户端的效用/优先级进行测量,并选择具有最佳效用测量的客户端进行模型训练和聚合。制定客户效用的方法多种多样。统计效用表示客户对全局模型的本地更新的有用性。可将统计实用程序分为基于数据样本和基于模型。基于数据样本的效用测量即基于数据采样的效用,利用客户端的本地数据来量化统计效用;基于模型的效用测量即确定客户端优先级的另一种方法是比较其模型权重/梯度,效用其中,θ表示本地模型的权重,表示全局模型的权重,|θ|表示模型权重参数的总量,和分别表示客户端i和全局模型在第j个参数的权重。
技术实现思路
1、为解决上述技术问题,本发明提供一种通过干预并选择合适干预时间来保证公平性的联邦学习客户端选择方案。
2、本发明解决上述技术问题的技术方案的技术方案是:一种保证公平的联邦学习客户端选择方案,包括以下步骤:
3、(1)初始化:云服务器初始化全局模型,发送给参与训练的客户端;
4、(2)训练:客户端接收到全局模型,利用本地数据对模型进行训练;
5、(3)判断:云服务器根据客户端的局部相似度大小判断是否需要开始进行干预;
6、(4)聚合:云服务器采用干预和不干预两种模式对客户端提供的训练参数进行聚合;
7、(5)客户端选择:计算客户端的效用值并进行排序,选择效用值最大的k个客户端参与训练;
8、(6)分发:云服务器将新的全局模型广播给被选择参与训练的客户端。
9、上述的保证公平的联邦学习客户端选择方案,所述步骤(1)中,初始化阶段主要是服务器初始化全局模型,广播给所有参与联邦学习训练的客户端。其具体过程为:
10、服务器:
11、1-1)服务器ecs初始化全局模型θ0。
12、1-2)服务器ecs向所有参与训练的客户端ck(k={1,...,k},k为参与训练的客户端总数)广播初始化的全局模型θ0。
13、上述的保证公平的联邦学习客户端选择方案,所述步骤(2)中,训练阶段主要是客户端接收到全局模型,利用本地数据对模型进行训练。其具体过程为:
14、客户端:
15、2-1)客户端ck(0<k≤k)接收到云服务器ecs广播分发的全局模型θt-1。
16、2-2)客户端ck(0<k≤k)利用本地数据集的样本进行模型训练,更新客户端模型,其中,为第t轮第k个客户端更新的模型,θt-1为第t-1轮的全局模型,ηt为更新的第t轮的全局模型的学习率,ξk为客户端ck的数据集样本。
17、2-3)客户端ck(0<k≤k)将训练后的本地更新δθk和损失fk(θ)传回给云服务器。
18、上述的保证公平的联邦学习客户端选择方案,所述步骤(3)中,判断阶段主要是云服务器根据客户端的局部相似度大小判断是否需要开始进行干预。其具体过程为:
19、服务器:
20、3-1)服务器ecs接受到各个客户端训练后发送的本地更新δθk和损失fk(θ)。
21、3-2)在第t轮中,计算全局更新参数其中,δθi,j表示第t轮通信中全局模型的第(i,j)个参数(δθ∈ra×b)。
22、3-3)计算客户端的局部相似度大小其中t表示当前轮次,d表示滑动窗口的大小,表示在第i轮中的全局更新参数。
23、3-4)根据客户端的局部相似度大小判断是否启动公平干预:如果则启动公平干预;否则不启动公平干扰。ξ大小的选择可根据前段时间δgs的结果进行适当调整。
24、上述的保证公平的联邦学习客户端选择方案,所述步骤(4)中,聚合阶段主要是云服务器采用干预和不干预两种模式对客户端提供的训练参数进行聚合。其具体过程为:
25、服务器:
26、4-1)通过步骤(3)中的判断决定是否进行干预,如果不进行干预,执行步骤4-2);如果进行干预,执行步骤4-3)。
27、4-2)如果不进行干预来聚合更新全局模型:其中,θt表示第t轮的全局模型,ηt表示学习率,δθk表示第t轮中在k个客户端中的第k个客户端的本地模型。
28、4-3)如果进行干预来聚合更新全局模型:其中,θt表示第t轮中使用的全局模型参数,ηt表示学习率,表示下降梯度。其中k为参与训练的客户端总数,λ作为公平惩罚项,λ的值越小,第二项的值越大,意味着更加强调公平;相反,当λ的值越大,第二项的值越小,意味着更强调平均损失的最小化。
29、上述的保证公平的联邦学习客户端选择方案,所述步骤(5)中,客户端选择阶段主要是计算客户端的效用值并进行排序,选择效用值最大的k个客户端参与训练。其具体过程为:
30、服务器:
31、5-1)计算每个客户端ci的效用值其中,θ表示本地模型的权重,表示全局模型的权重,|θ|表示模型权重参数的总量,和分别表示客户端i和全局模型在第j个参数的权重。
32、5-2)在第t轮中,将所有客户端ci利用效用值δi进行排序,选择效用值最大的前k个客户端参与第t+1轮的训练。
33、上述的保证公平的联邦学习客户端选择方案,所述步骤(6)中,分发阶段主要是云服务器将新的全局模型广播给被选择参与训练的客户端。其具体过程为:
34、服务器:
35、6-1)在第t轮中,服务器ecs将新的全局模型θt-1广播给所有被选择参与训练的k个客户端。
36、本发明的有益效果在于:
37、1、本发明提出一个保证公平的联邦学习客户端选择方案,采用一个相对指标来量化联邦学习的公平性,具有洛伦兹一致性,可以反映每一轮通信的公平程度。这不仅可以帮助我们了解联合学习过程中公平性的变化,从而调整客户的权重以达到预期的公平性和模型性能,还可以更好地激励客户参与培训过程。
38、2、本发明提出了一种新的干预联邦学习过程,以往干预联邦学习全过程的方法不同,我们将联邦学习分为两个不同的训练阶段,并提出在第二阶段应进行公平干预。因为在这个阶段,更新的波动会急剧缩小,单个更新看起来不那么相似。
39、3、本发明提出了一种公平的联邦优化算法。与以往的实证方法不同,在目标函数中加入了公平惩罚项,通过梯度下降得到客户的梯度更新与全局模型公平性之间的关系,从而在保持全局模型性能的同时提高模型的公平性。
本文地址:https://www.jishuxx.com/zhuanli/20240730/197120.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表