一种基于轨迹跟踪的深度强化学习局部路径规划方法
- 国知局
- 2024-07-31 23:56:11
本发明涉及移动机器人导航领域,尤其涉及一种基于轨迹跟踪的深度强化学习局部路径规划方法。
背景技术:
1、移动机器人是指自主移动机器人,它是一种具备感知、理解和行动能力的机器人。移动机器人是通过传感器来来识别周围环境,并在环境内按照规则移动,同时自动执行某些工作的机器。如果移动机器人在感知和行动能力的基础上进一步具备自主分析和规划等“思考”能力,则称之为自主移动机器人。近年来室内移动机器人的应用需求快速增长,越来越多不同功能的机器人产品进入了我们的日常生活。为了适应不同的室内环境,对机器人的未知环境探索能力和自身定位与移动的能力提出了新的要求。为了使机器人能够更好的在复杂的室内环境中工作,需要机器人能够具有自主导航、避障的能力。
2、深度强化学习(deep reinforcement learning drl)相关领域的进步为使用神经网络解决自主导航、避障问题创造了新的方案,其中利用drl替代传统算法来解决复杂场景下运动控制问题的工作近年来不断出现,其端到端的运动控制方式能够解决传统算法中存在的问题。然而基于drl的导航方法存在奖励稀疏、鲁棒性差等问题,训练难度大。目前基于drl的运动规划方法仍然具有很大改进空间。
技术实现思路
1、本发明的目的就在于提供一种解决了上述问题,基于轨迹跟踪的深度强化学习局部路径规划方法。
2、为了实现上述目的,本发明采用的技术方案是:一种基于轨迹跟踪的深度强化学习局部路径规划方法,包所述路径规划包括以下步骤:
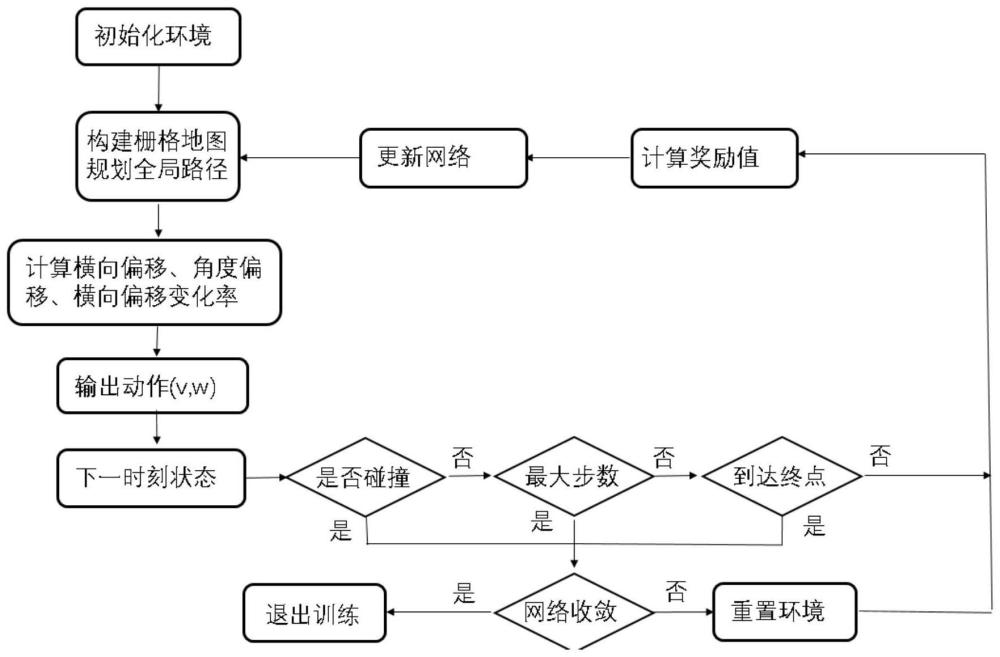
3、步骤1:设置机器人起始位置和导航目标点,利用2d激光雷达采集当前时刻周围环境的点云数据,由于机器人在同一位姿下的不同时刻,激光雷达对于固定障碍物探测距离存在误差(噪声),因此通过构建栅格地图表示机器人周围的障碍物信息;
4、机器人初始位置为ps=(xs,ys),导航目标点位置为pg=(xg,yg),机器人通过2d激光雷达扫描周围水平范围半径5米以内的障碍物信息,其扫描范围半径根据激光雷达性能参数决定,得到点云数据,使用gmapping算法建立增量式栅格地图,gmapping是一种应用于栅格地图的算法,小场景下具备精度高,计算量小的优点,能快速准确的建立增量式栅格地图,且不对激光雷达硬件要求低;
5、步骤2:根据栅格地图、机器人起始位置和导航目标点,确定一条能到达目标点的全局路径;
6、根据起始点ps,导航目标点pg,以及栅格地图信息,使用a*算法规划一条全局轨迹,并对该轨迹进行平滑操作,保证轨迹的平滑对于本发明中轨迹跟踪强化学习模型的训练更快,效果更好;
7、步骤3:找到当前时刻机器人距离全局路径最近的点,计算横向偏移、横向偏移变化量和角度偏移,三者将作为奖励函数设计的主体依据,区别于其它方法的是,本发明中并未把机器人与目标导航点的距离作为奖励,而是引入轨迹跟踪的约束,这种方法可以有效解决稀疏奖励的问题,在保证导航效果的同时有效降低训练难度,解决强化学习模型因为环境变化出现的泛化性问题;
8、步骤4:将横向偏移dt、角度偏移θt、上一时刻机器人的速度xt-1、角速度wt-1,以及2d激光雷达传感器观测数据,2d激光雷达传感器观测数据为机器人正前方180度范围内,以9度为间隔的20维激光雷达扫描数据,构成机器人当前的状态st,将一共24维数据归一化至[0,1]范围内,并作为ppo算法的输入,输入ppo算法,经过ppo算法进行优化求解得到当前时刻的线速度、角速度输出,并发布给机器人执行;
9、ppo神经网络结构:中间层包括2层mlp结构,其每层包含的神经元个数分别为512,512,并且每一层的输出使用normalize函数归一化,再输入tanh激活函数。神经网络的输出2维的连续动作(线速度、角速度)的高斯分布的均值;高斯分布的方差是以e为底数的指数函数,指数通过一层神经网络输出得到(由nn.parameter定义,初始值为0),采样后得到机器人待执行的连续动作,其中机器人线速度限制在0~0.5m/s范围内,角速度限制在-1~1rad/s范围内。
10、ppo神经网络相关参数:actor网络学习率3e-4;crtic网络学习率1e-3;折扣因子gamma 0.9,gae参数lamda为0.95;clip裁剪阈值为0.2;
11、步骤5:机器人根据设定的线速度和角速度前进一定时间,计算当前时刻横向偏移惩罚、横向偏移变化奖励、角度偏移惩罚,碰撞惩罚,其中横向偏移和角度偏移惩罚衡量当前时刻机器人与所跟踪轨迹的位置偏差,如果偏差越大,负奖励越大,通过横向偏移变化量判断机器人动作的好坏,增强轨迹跟踪的效果,碰撞奖励只在机器人距离障碍物较近时才会生效,根据当前时刻机器人位置,以及当前时刻线速度和角速度计算下一时刻机器人位置,并计算与障碍物的距离差,如果距离变小,获得负奖励,如果距离小于安全阈值,表明发生碰撞,获得较大的负奖励。将以上奖励进一步加权计算当前时刻综合奖励,反馈至ppo算法进行梯度更新;
12、步骤6:判断是否发生碰撞或超过最大步数或到达目标点,若都不是,则将重复步骤1至步骤5,否则将判断网络是否收敛,若不是,则重置训练环境,重复步骤1至步骤5,否则视为训练完成,退出环境。
13、作为优选,步骤3中,进行横向偏移和角度偏移的计算方法,
14、以步骤2中得到的全局轨迹为参考线,参考线实际上由离散点组成,遍历参考线所有离散点,以当前时刻距离机器人最近的点为投影点,以投影点与其相邻点的直线方向为x轴,向左旋转90度方向为y轴,建立自然坐标系,设投影点x轴的单位向量是τm,y轴单位向量是nm,机器人当前时刻坐标减去投影点坐标得到向量乘δm,则
15、角度偏移θ表示为:
16、θ=<δm,τm>
17、横向偏移d表示为:
18、d=δm*nm
19、横向偏移变化量derta表示为:
20、derta=|v|*sin(θ)
21、其中v表示机器人当前线速度。
22、作为优选,步骤5中,横向偏移惩罚设定为derr,横向偏移惩罚设定为θerr,横向偏移变化率惩罚设定为dderta,碰撞惩罚设定为rc,计算公式如下:
23、derr=-0.1*d
24、θerr=-0.1*(e|θ|-1)
25、
26、
27、其中,laserinfo表示机器人前方180度的激光雷达扫描信息,disnow表示当前时刻机器人距离障碍物的距离,disnext表示下一时刻机器人距离障碍物的距离。
28、用深度强化学习(drl)训练的控制器在实际表现的一个关键问题是drl策略学习的动作明显缺乏平滑性,这种趋势通常以控制信号振荡的形式出现,并可能导致控制不良、高功耗等问题。因此提出ppo算法训练时在梯度更新中加入平滑损失,旨在减少机器人当前状态st和下一时刻状态st+1动作输出的差距。本方法与直接通过强化学习的奖励函数来实现平滑相比,更具有泛化性,和可移植性。
29、作为优选,步骤5的ppo算法在梯度更新中加入平滑损失,设平滑损失为lt,具体定义如下:
30、lt=-0.000001*dt(πθ(st),πθ(st+1))
31、其中,dt表示欧几里得距离,即d(a1,a2)=||a1-a2||2,神经网络策略πθ由θ参数化,st表示当前时刻机器人状态,st+1表示下一时刻机器人状态。
32、平滑损失为lt具体使用方法如下:
33、在每个时间步t,保存当前状态st至列表s,保存下一时刻的状态st+1至列表s_。在当前epoch周期结束,更新actor神经网络时,将πθ(s)、πθ(s_)输入mse loss函数计算得到结果。将结果乘上系数后直接加在actor网络原本的loss后面即可,根据本发明实际经验,平滑损失的系数取很小,一般小于1e-5。
34、终止状态1,发生碰撞:机器人当前状态st中,20维的激光雷达扫描数据中存在小于安全阈值的数据,安全域值取0.2m。
35、终止状态2,到达最大步数:在训练中,根据实际地图大小、机器人速度和全局轨迹长度,合理设置一个周期的训练步长,本发明中设置一个训练周期为150步。
36、终止状态3,到达目标点:机器人当前位置坐标与目标导航点坐标的欧氏距离小于0.2m,视为到达终点。
37、关于重置训练环境:本发明中,推荐随机选择机器人起始点和目标导航点,保证泛化性。
38、与现有技术相比,本发明的优点在于:
39、(1)通过引入轨迹跟踪的方式解决了深度强化学习中稀疏奖励难题,训练难度远小于端到端的强化学习方式。实现机器人无碰撞完成路径跟踪及导航任务,能够顺利躲避动态和静态障碍物,并且相较于传统方法轨迹更加平滑。
40、(2)通过本发明可实现机器人无碰撞完成导航任务,具备躲避动态和静态障碍物能力,并且相较于传统方法轨迹更加平滑。
本文地址:https://www.jishuxx.com/zhuanli/20240730/199258.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。